

The Lenovo ThinkSystem SR650 V4 is a flexible and powerful 2-socket, 2U rack server designed to meet the needs of industries such as cloud services, telecommunications, and high-performance computing (HPC). Whether optimizing for scale-out workloads or future-proofing your data center with high-density compute, the SR650 V4 offers meaningful upgrades over its predecessor, the SR650 V3.

Differences Between Lenovo SR650 V4 and SR650 V3
Processors
The processor capabilities mark one of the more significant upgrades in the SR650 V4. While the SR650 V3 relied on 4th Gen Intel Xeon Scalable Processors, the SR650 V4 introduces the Intel Xeon 6 platform (formerly codenamed “Granite Rapids”). Our review focuses on the P-core (Performance-core) architecture, designed explicitly for compute-intensive workloads. The V4 supports one or two processors with up to 86 P-cores per socket (up to 172 threads), delivering higher core speeds (up to 4 GHz) and TDPs up to 350W.
This transition allows organizations to handle more demanding applications per server, reducing their physical footprint. The architecture creates a robust foundation for virtualization and heavy database operations. Additionally, the V4’s architecture supports massive PCIe bandwidth, with up to 88 PCIe 5.0 lanes per processor, which is essential for feeding modern high-speed networking adapters and NVMe storage arrays without bottlenecks.
| CPU Model | Cores / Threads | Base Freq | Max Turbo | L3 Cache | TDP |
|---|---|---|---|---|---|
| 6787P | 86 / 172 | 2.0 GHz | 3.8 GHz | 336 MB | 350 W |
| 6781P | 80 / 160 | 2.0 GHz | 3.8 GHz | 336 MB | 350 W |
| 6767P | 64 / 128 | 2.4 GHz | 3.9 GHz | 336 MB | 350 W |
| 6761P | 64 / 128 | 2.5 GHz | 3.9 GHz | 336 MB | 350 W |
| 6760P | 64 / 128 | 2.2 GHz | 3.8 GHz | 320 MB | 330 W |
| 6747P | 48 / 96 | 2.7 GHz | 3.9 GHz | 288 MB | 330 W |
| 6745P | 32 / 64 | 3.1 GHz | 4.3 GHz | 336 MB | 300 W |
| 6741P | 48 / 96 | 2.5 GHz | 3.8 GHz | 288 MB | 300 W |
| 6740P | 48 / 96 | 2.1 GHz | 3.8 GHz | 288 MB | 270 W |
| 6737P | 32 / 64 | 2.9 GHz | 4.0 GHz | 144 MB | 270 W |
| 6736P | 36 / 72 | 2.0 GHz | 4.1 GHz | 144 MB | 205 W |
| 6732P | 32 / 64 | 3.8 GHz | 4.3 GHz | 144 MB | 350 W |
| 6731P | 32 / 64 | 2.5 GHz | 4.1 GHz | 144 MB | 245 W |
| 6730P | 32 / 64 | 2.5 GHz | 3.8 GHz | 288 MB | 250 W |
| 6724P | 16 / 32 | 3.6 GHz | 4.3 GHz | 72 MB | 210 W |
| 6714P | 8 / 16 | 4.0 GHz | 4.3 GHz | 48 MB | 165 W |
| 6530P | 32 / 64 | 2.3 GHz | 4.1 GHz | 144 MB | 225 W |
| 6527P | 24 / 48 | 3.0 GHz | 4.2 GHz | 144 MB | 255 W |
| 6521P | 24 / 48 | 2.6 GHz | 4.1 GHz | 144 MB | 225 W |
| 6520P | 24 / 48 | 2.4 GHz | 4.0 GHz | 144 MB | 210 W |
| 6517P | 16 / 32 | 3.2 GHz | 4.2 GHz | 72 MB | 190 W |
| 6515P | 16 / 32 | 2.3 GHz | 3.8 GHz | 72 MB | 150 W |
| 6511P | 16 / 32 | 2.3 GHz | 4.2 GHz | 72 MB | 150 W |
| 6507P | 8 / 16 | 3.5 GHz | 4.3 GHz | 48 MB | 150 W |
| 6505P | 12 / 24 | 2.2 GHz | 4.1 GHz | 48 MB | 150 W |
Memory
Regarding memory, the SR650 V4 significantly improves on the V3’s capabilities, maximizing subsystem performance. It supports DDR5 memory speeds of up to 6400 MHz (1 DIMM per channel), a substantial jump from the previous generation’s 4800 MHz limit. The system features 32 DIMM slots (16 per processor) arranged across eight memory channels per processor. It supports standard RDIMMs, 3DS RDIMMs, and the new Multiplexed Rank DIMMs (MRDIMMs), which can operate at speeds up to 8000 MHz for bandwidth-hungry applications. Using 256GB 3DS RDIMMs, the server supports a massive 8TB of total system memory.

Furthermore, the V4 introduces support for CXL 2.0 (Compute Express Link) memory expansion. Administrators can install up to 12 CXL memory modules in the E3.S drive bays (specifically the E3.S 2T form factor). This allows the system to scale memory capacity and bandwidth beyond traditional processor-attached limits, reducing compute latency for next-generation workloads and lowering Total Cost of Ownership (TCO) by stranding less memory.
Storage
The Lenovo SR650 V4 storage capabilities demonstrate a shift toward high-performance NVMe density and flexible form factors. While supporting legacy 3.5-inch and 2.5-inch drives, the V4 introduces massive support for the E3.S NVMe form factor. The system can accommodate up to 32x E3.S 1T drives or 12x E3.S 2T drives, delivering higher density and improved thermal management compared to traditional U.2 SSDs.

Crucially, the V4 supports direct NVMe connectivity without oversubscription (1:1), ensuring that high-speed storage is not bottlenecked by PCIe lane sharing. The inclusion of M.2 hot-swap boot drive options further enhances serviceability.
Networking
For networking, the SR650 V4 features two dedicated OCP 3.0 slots, both supporting PCIe Gen 5 x16. This is a key upgrade that enables redundant, high-speed networking (e.g., dual-port 200GbE or single-port 400GbE) without consuming standard PCIe riser slots. The transition to PCIe 5.0 doubles the theoretical bandwidth (32 GT/s vs. 16 GT/s), making the V4 capable of handling the most demanding cloud and AI network traffic.

Power and Cooling
The SR650 V4 offers enhanced power supply options, ranging from 800W up to 3200W, available in Titanium and Platinum efficiency levels. The system also supports -48V DC and HVAC/HVDC options to meet specific data center requirements.

To manage heat from high-TDP processors and memory, Lenovo introduces Neptune liquid-cooling options. The “Compute Complex Neptune Core Module” uses open-loop liquid cooling to remove heat from processors, memory, and voltage regulators, capable of capturing over 80% of server heat and significantly reducing datacenter cooling costs.
Overall, the SR650 V4 delivers a solid leap forward in performance, density, and thermal efficiency for modern enterprise environments.
Lenovo ThinkSystem SR650 V4 Specifications
| Specification | Details |
|---|---|
| System Specifications | |
| Form Factor | 2U rack |
| Processor | Up to 2x Intel Xeon 6700/6400-series (P-cores); Up to 86 cores per CPU; Up to 350W TDP |
| Memory | 32 DIMM slots (16 per processor); supports TruDDR5 RDIMMs up to 6400 MHz and MRDIMMs up to 8000 MHz |
| Memory Expansion | Supports CXL 2.0 memory modules in E3.S 2T form factor (up to 12x DIMMs) |
| Memory Maximum | Up to 8TB system memory (using 256GB 3DS RDIMMs) |
| Disk Drive Bays | Front: Up to 24x 2.5″ NVMe/SAS/SATA, 16x 3.5″ SAS/SATA, or 32x E3.S NVMe Mid: Up to 8x 2.5″ simple-swap Rear: Up to 8x 2.5″ or 4x 3.5″ hot-swap |
| Storage Controller | Up to 36x onboard NVMe ports (1:1 connectivity); RAID/HBA support |
| Network Interfaces | Two OCP 3.0 SFF slots with PCIe 5.0 x16 host interface |
| PCI Expansion Slots | Up to 10x PCIe 5.0 slots (rear); optional front PCIe slots |
| GPU Support | Up to 10x single-width GPUs or 2x double-width GPUs |
| Ports | Front: External diagnostics port, optional USB, and Mini-DP Rear: 2x USB 3.0, 1x VGA, 1x RJ-45 management, optional serial |
| Cooling | Up to 6x hot-swap fans (N+1 redundancy); Optional Neptune liquid cooling modules |
| Power Supply | Up to two hot-swap redundant AC/DC power supplies (800W–3200W) |
| Systems Management | XClarity Controller 3 (XCC3); Optional XCC3 Premier |
| Security Features | TPM 2.0, PFR Root of Trust (NIST SP800-193), chassis intrusion, lockable bezel |
| Operating Systems | Microsoft Windows Server, RHEL, SLES, Ubuntu Server |
| Warranty | 3-year base warranty (configurable) |
| Dimensions | 87 mm (3.4 in) H x 440 mm (17.3 in) W x 800 mm (31.5 in) D |
| Weight | Maximum weight: 38.8 kg (85.5 lb) |
Lenovo ThinkSystem SR650 V4 Design and Build
The Lenovo ThinkSystem SR650 V4 is a standard 2U platform that makes efficient use of its physical envelope, balancing component density with airflow and serviceability. The chassis measures 3.4 in high, 17.3 in wide, and 31.5 in deep, with a maximum configured weight of 85.5 lb. These dimensions place it squarely in line with other 2U enterprise servers while providing sufficient depth for high-performance CPUs, dense memory configurations, and flexible storage backplanes.
Lenovo’s established ThinkSystem industrial design is immediately recognizable, with a rigid steel chassis and clear, functional labeling. Internally, the layout is clean and purpose-driven, emphasizing straight-through airflow, modular component zones, and tool-less access for routine service. The overall construction feels robust and well-engineered, reflecting a platform designed for continuous operation in data center environments rather than aesthetic appeal.
Front Panel
The front panel is highly configurable. Our test system is equipped with an 8-bay 2.5-inch drive backplane, but the chassis scales easily to 16 or even 24 bays with minimal effort. Customers can also opt for 3.5-inch bays for higher raw capacity or the newer E3.S backplane options for high-performance NVMe density. AnyBay support allows SAS, SATA, and NVMe drives to coexist within the same drive cage, providing substantial flexibility for mixed-storage deployments.

The front panel includes essential operator controls: a power button, an ID button, and status LEDs indicating system health and network activity. A pull-out information tab provides quick access to the XCC network access label and serial number. Optional local connectivity includes a Mini DisplayPort and USB ports for crash-cart access, which is invaluable for troubleshooting in “lights-out” data centers.
Rear Panel
The rear of the chassis is designed for maximum I/O density. It can accommodate up to 10 PCIe Gen 5 slots, depending on the riser configuration. The inclusion of two OCP 3.0 slots frees up the standard PCIe risers for other add-in cards, such as GPUs or storage controllers.
In addition to expansion, the rear panel houses the onboard BMC management network port, two USB-A ports, and a VGA output for local console access. Dual hot-swap power supplies are mounted at the rear, maintaining serviceability without impacting airflow or expansion layouts.
Internal
Internally, the layout is clean and optimized for airflow. 32 DIMM slots flank dual CPU sockets, arranged to maintain unobstructed front-to-back cooling from a bank of six high-performance hot-swap fans at the front of the chassis. The fans are fully toolless and easily replaceable, with the entire fan tray removable without tools. Removing the tray provides unobstructed direct access to the AnyBay storage area, simplifying service, upgrades, and backplane changes.

Storage cabling is routed neatly along the sides of the chassis to avoid blocking airflow to the CPUs and memory. For configurations using Neptune liquid-cooling modules, the internal layout changes slightly to accommodate the coolant loops, but core serviceability remains high. The M.2 boot drive module is mounted on the air baffle or drive cage, allowing easy access without removing other components.
XClarity Controller 3
The SR650 V4 features the new XClarity Controller 3 (XCC3). This management engine offers a significant performance upgrade over previous generations, with faster boot times and a more responsive HTML5 interface. The Platform Resource Manager provides detailed telemetry on power and thermal status, helping administrators optimize datacenter efficiency.
XCC3 supports a wide range of remote management functions, including remote control (KVM), virtual media mounting, and firmware updates. The interface is intuitive, providing a dashboard view of system health, active events, and hardware inventory. For automation, XCC3 fully supports Redfish REST APIs.
Lenovo ThinkSystem SR650 V4 Performance
This section examines benchmark results from Blender, y-cruncher, vLLM, and Phoronix. Initial testing was conducted on the Lenovo ThinkSystem SR650 V4 equipped with Intel Xeon 6740P processors, allowing us to evaluate the platform’s performance-focused P-core architecture and overall throughput under CPU-bound workloads. Midway through the review, we adjusted the system configuration to enable GPU-accelerated testing. The transition was straightforward, aided by Lenovo’s GPU enablement upgrade kit, which includes high-performance fans, upgraded heatsinks, a revised airflow shroud, and GPU-capable risers designed to support higher-power accelerators. Installation required no significant chassis changes and integrated cleanly with the existing system layout.
With the upgraded cooling and airflow components installed, we added a single NVIDIA L40S GPU to the platform. This allowed us to expand testing to include GPU-accelerated workloads such as Blender GPU rendering and inference-focused benchmarks, while maintaining stable thermals and consistent system behavior. The modular nature of the upgrade highlights the SR650 V4’s flexibility, enabling it to transition easily from an efficiency-oriented CPU configuration to a balanced CPU+GPU platform suitable for mixed compute workloads.
Lenovo ThinkSystem SR650 V4 Configuration:
- CPU: 2x Intel Xeon 6740P
- Memory: 1TB RAM
- Storage: 4 x 960GB SSDs
- GPU: NVIDIA L40S
Blender 4.5
Blender is an open-source 3D modeling application. This benchmark was run using the Blender Benchmark utility. The score is measured in samples per minute, with higher values indicating better performance.
In the Blender CPU benchmark, the Lenovo ThinkSystem SR650 V4 delivers solid rendering performance across all scenes, scoring 1136.99 samples per minute in Monster, 707.60 in Junkshop, and 562.53 in Classroom. The results reflect strong multithreaded scaling from the dual Intel Xeon 6740P processors, with consistent performance as scene complexity increases.
| Blender CPU (Samples per minute; higher is better) | Lenovo ThinkSystem SR650 V4 (2x Intel Xeon 6740P, 1TB RAM) |
|---|---|
| Monster | 1136.99 |
| Junkshop | 707.60 |
| Classroom | 562.53 |
In the Blender CPU no SMT benchmark, the SR650 V4 shows a significant uplift in rendering throughput, reaching 4686.40 samples per minute in Monster, 2223.96 in Junkshop, and 2385.98 in Classroom. The GPU results highlight the system’s ability to accelerate complex rendering workloads, delivering substantially higher throughput compared to CPU-only rendering.
| Blender CPU (no SMT) (Samples per minute; higher is better) | Lenovo ThinkSystem SR650 V4 (2x Intel Xeon 6740P, 1TB RAM) |
|---|---|
| Monster | 4686.40 |
| Junkshop | 2223.96 |
| Classroom | 2385.98 |
y-cruncher
y-cruncher is a multithreaded, scalable program that computes Pi and other mathematical constants to trillions of digits. Since its launch in 2009, it has become a popular benchmarking and stress-testing application for overclockers and hardware enthusiasts.
In y-cruncher, the Lenovo scales cleanly as problem size increases, highlighting the platform’s strong multithreaded compute performance and memory bandwidth. With dual Intel Xeon 6740P processors and 1TB of RAM, the system completes a 1B-digit Pi calculation in just over 20 seconds and maintains consistent efficiency up to 25B digits, taking 362 seconds. The results show predictable scaling under sustained CPU and memory pressure, making the SR650 V4 well-suited for heavy mathematical workloads and stress-testing scenarios.
| Y-Cruncher (Total Computation Time) | Lenovo ThinkSystem SR650 V4 (2x Intel Xeon 6740P, 1TB RAM) |
|---|---|
| 1 Billion | 20.715 s |
| 2.5 Billion | 44.412 s |
| 5 Billion | 81.937 s |
| 10 Billion | 152.743 |
| 25 Billion | 362.566 |
vLLM Online Serving LLM Inference Performance
vLLM is the most popular high-throughput inference and serving engine for LLMs. The vLLM online serving benchmark is a performance evaluation tool that measures the real-world serving capabilities of this inference engine under concurrent requests. It simulates production workloads by sending requests to a running vLLM server with configurable parameters, including request rate, input/output lengths, and the number of concurrent clients. The benchmark measures key metrics, including throughput (tokens per second), time to first token, and time per output token (TPOT), helping users understand how vLLM performs under different load conditions.
We tested inference performance across a comprehensive suite of models spanning various architectures, parameter scales, and quantization strategies, and evaluated throughput under different concurrency profiles.
Dense Model Performance
Dense models follow the conventional LLM architecture, in which all parameters and activations are used during inference, resulting in more computationally intensive processing than their sparse counterparts. To comprehensively evaluate performance characteristics across model scales and quantization strategies, we benchmarked multiple dense model configurations from the Llama 3.1 8B family.
Llama 3.1 8B Precision FP8
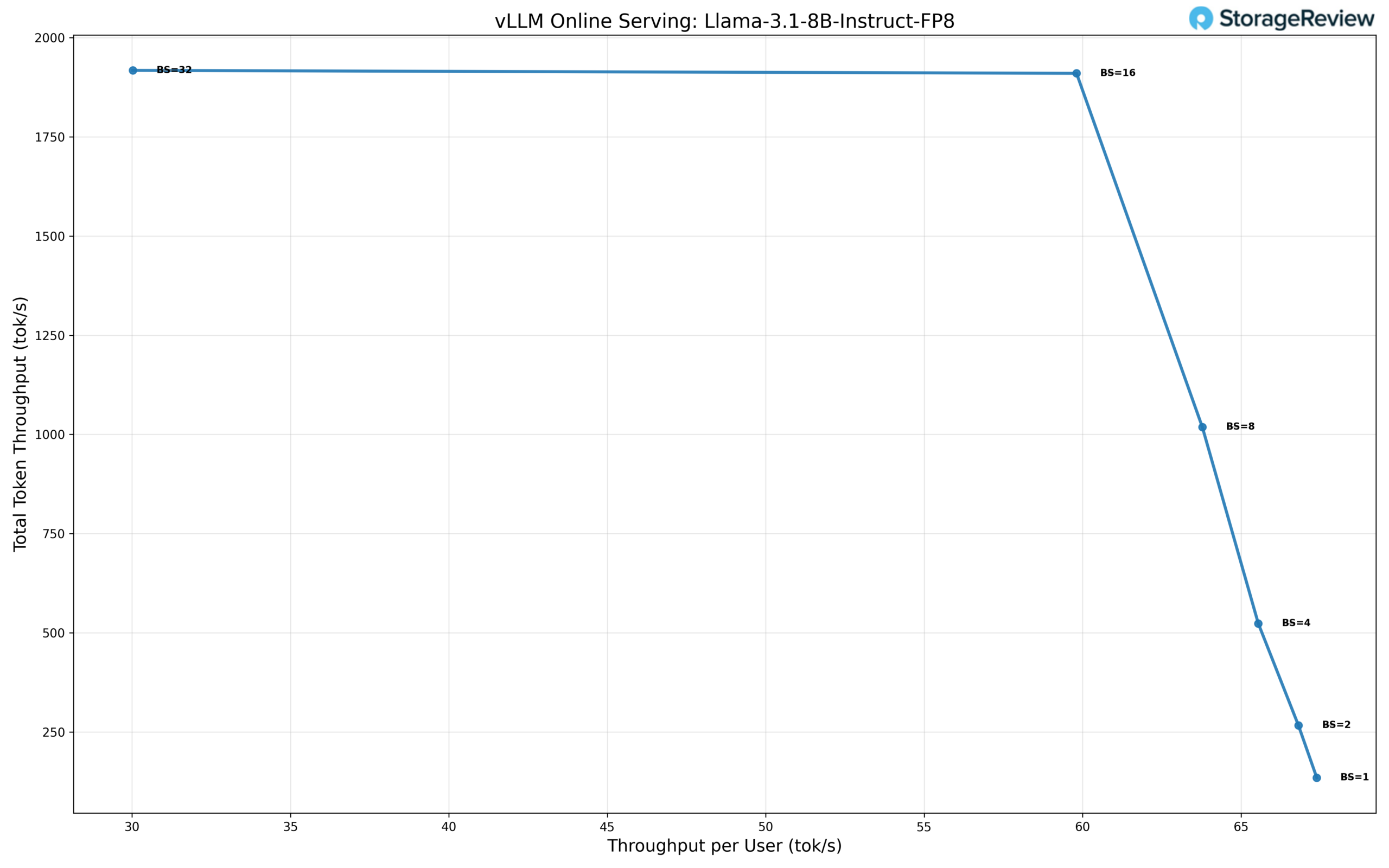
The Llama 3.1 8B model running in FP8 precision shows a different scaling profile than the standard-precision configuration, prioritizing efficiency at moderate concurrency levels while trading off peak throughput at higher batch sizes. At single-user concurrency (BS=1), the model delivers 67.8 tok/s per user, with a total throughput of 135.6 tok/s and a TPOT of approximately 3.1 ms, establishing a lower single-stream baseline compared to full precision.
As batch size increases, total throughput scales rapidly while per-user throughput declines in a controlled manner. At BS=2, throughput increases to 271 tok/s total, with 66.8 tok/s per user. At BS=4, the total throughput reaches 523 tok/s, and at BS=8, the model delivers 1,017 tok/s, with 63.6 tok/s per user. Latency remains stable through these lower concurrency levels, making FP8 well-suited for light multi-user inference scenarios.
Scaling continues through BS=16, where the model maintains a total throughput of 1,918 tok/s, with 60.0 tok/s per user. At BS=32, total throughput plateaus at approximately 1,920 tok/s, with per-user throughput dropping to 30.0 tok/s. This plateau indicates that the FP8 configuration reaches its saturation point earlier than standard precision, favoring efficiency and predictability over maximum aggregate throughput.
Overall, FP8 achieves roughly a 14× increase in total throughput from BS=1 to its peak at BS=16-32. Latency remains consistent up to BS=16, then flattens alongside throughput at higher concurrency, highlighting FP8 as a practical choice for balanced, latency-sensitive inference workloads rather than extreme batch scaling.
Llama 3.1 8B Standard Precision
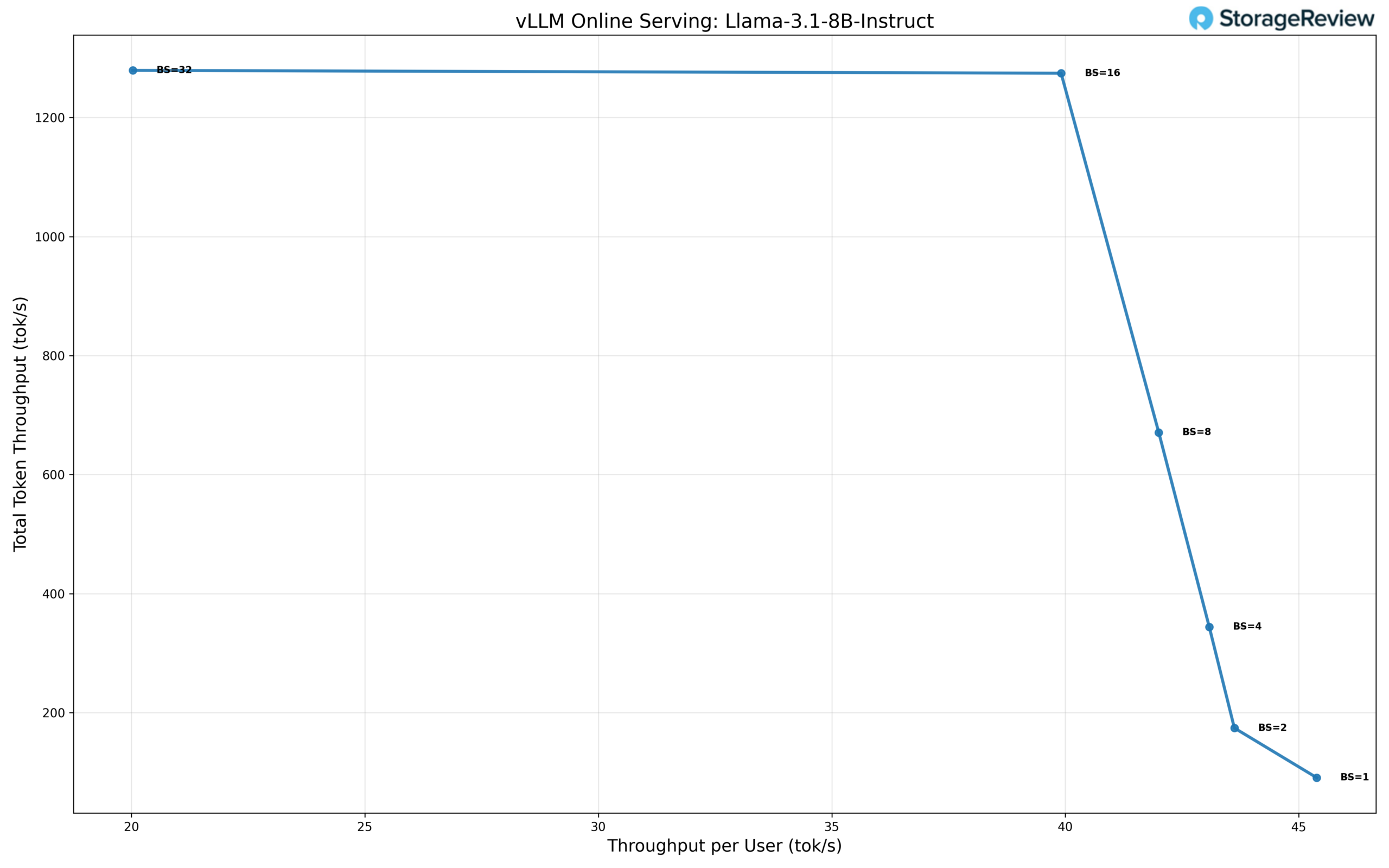
At standard precision, the Llama 3.1 8B model demonstrates predictable scaling behavior at lower concurrency levels, with strong per-user performance at small batch sizes and steadily increasing aggregate throughput as concurrency rises. In single-user operation (BS=1), the model delivers approximately 45.8 tok/s per user, yielding a total throughput of 91.6 tok/s and establishing a solid baseline for latency-sensitive workloads.
As concurrency increases, total throughput scales efficiently while per-user throughput declines gradually. At BS=2, total throughput rises to 176 tok/s, with 44.0 tok/s per user, and at BS=4, throughput reaches 344 tok/s, with 43.0 tok/s per user. This behavior continues through BS=8, where the model maintains a total throughput of 672 tok/s, with 42.0 tok/s per user, indicating good utilization without significant per-user degradation.
Scaling continues through BS=16, where total throughput peaks at approximately 1,280 tok/s, with 40.0 tok/s per user. At BS=32, total throughput remains effectively flat at around 1,280 tok/s, while per-user throughput drops to 20.0 tok/s, signaling saturation of the execution pipeline. This plateau suggests that, at standard precision, the model reaches its optimal operating point around BS=16, balancing throughput and responsiveness.
Overall, standard precision achieves roughly a 14× increase in total throughput from BS=1 to its peak, with stable per-user performance through moderate concurrency levels. This profile makes standard precision well-suited for deployments prioritizing consistent latency and predictable scaling over aggressive batch expansion.
Sparse Model Performance
Sparse models, particularly Mixture of Experts (MoE) architectures, are an emerging approach to efficiently scaling language models. These architectures maintain high total parameter counts while activating only a subset of parameters per token, potentially offering improved performance per active parameter.
Qwen3-Coder-30B-A3B FP8 Performance
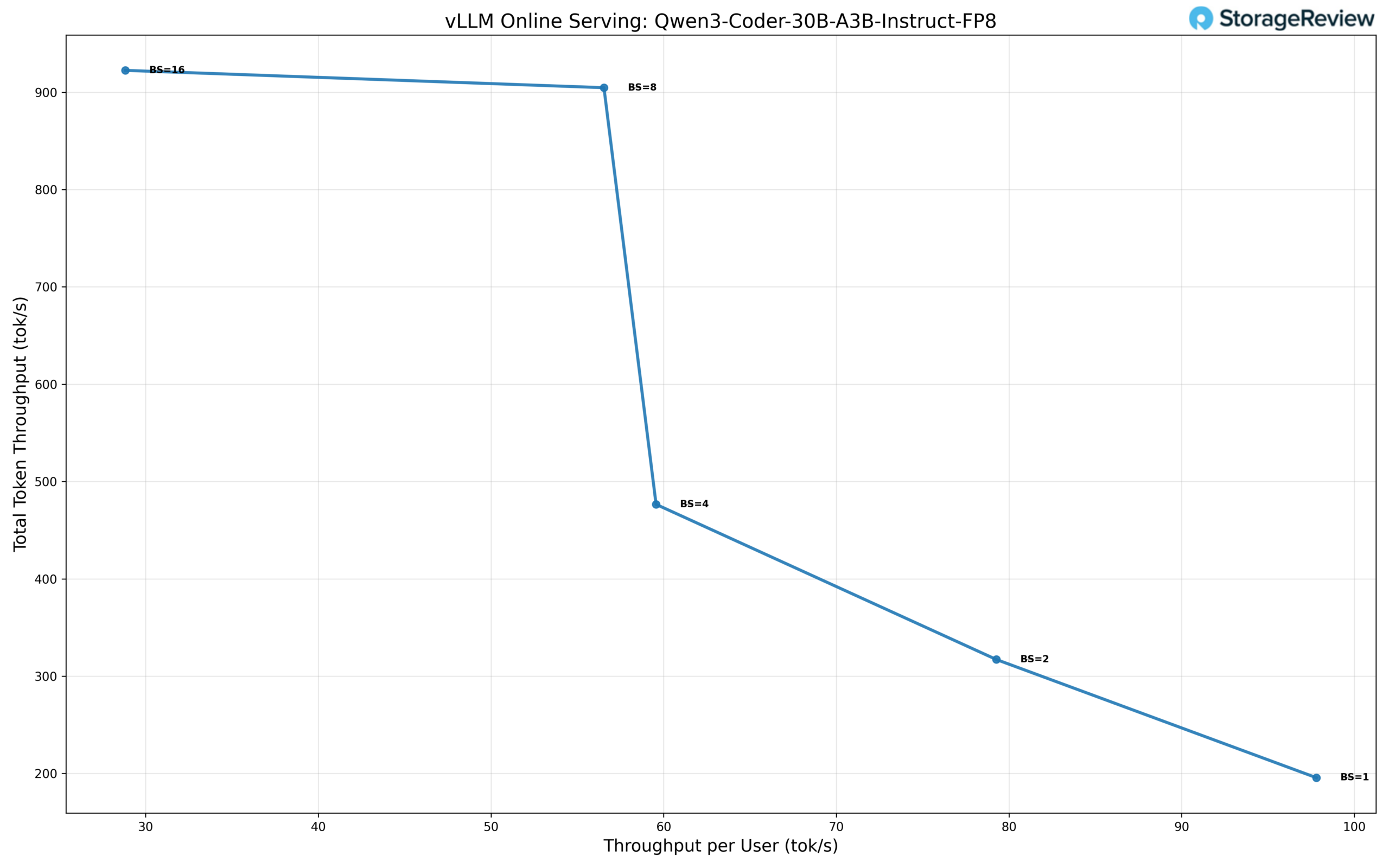
The Qwen3-Coder-30B-A3B model running in FP8 precision exhibits a scaling profile optimized for moderate concurrency, delivering strong per-user performance while reaching saturation earlier than smaller models. At single-user operation (BS=1), the model achieves approximately 98 tok/s per user, with a total throughput of 196 tok/s, establishing a high single-stream baseline that reflects the model’s optimization for code-generation workloads.
As concurrency increases, total throughput scales efficiently while per-user throughput declines in a controlled fashion. At BS=2, total throughput rises to 317 tok/s, with 79 tok/s per user, and at BS=4, the model delivers 477 tok/s total throughput at 59 tok/s per user. These results show effective utilization of available compute resources through low to moderate batching, without abrupt degradation in per-user responsiveness.
The model reaches its peak aggregate throughput at BS=8, sustaining approximately 905 tok/s total throughput, with 56 tok/s per user. Scaling continues marginally through BS=16, where total throughput increases slightly to 920 tok/s, while per-user throughput drops to 29 tok/s, indicating saturation of the inference pipeline. Beyond this point, additional concurrency provides minimal gains in total throughput while significantly impacting per-user performance.
Overall, Qwen3-Coder-30B-A3B FP8 delivers roughly a 4.7× increase in total throughput from BS=1 to its peak at BS=16. Latency and throughput characteristics suggest this configuration is best suited for moderate multi-user coding workloads that require high per-request performance. Still, extreme batch scaling is not the primary objective.
Microscaling Datatype Performance
Microscaling represents an advanced quantization approach that applies fine-grained scaling factors to small blocks of weights rather than uniform quantization across large parameter groups. NVIDIA’s NVFP4 format implements this technique through a blocked floating-point representation where each microscale block of 8-32 values shares a typical exponent as a scaling factor. This granular approach preserves numerical precision while achieving 4-bit representation, maintaining the dynamic range critical for transformer architectures. The format integrates with NVIDIA’s Tensor Core architecture, enabling efficient mixed-precision computation with on-the-fly decompression during matrix operations.
GPT-OSS-20b Performance
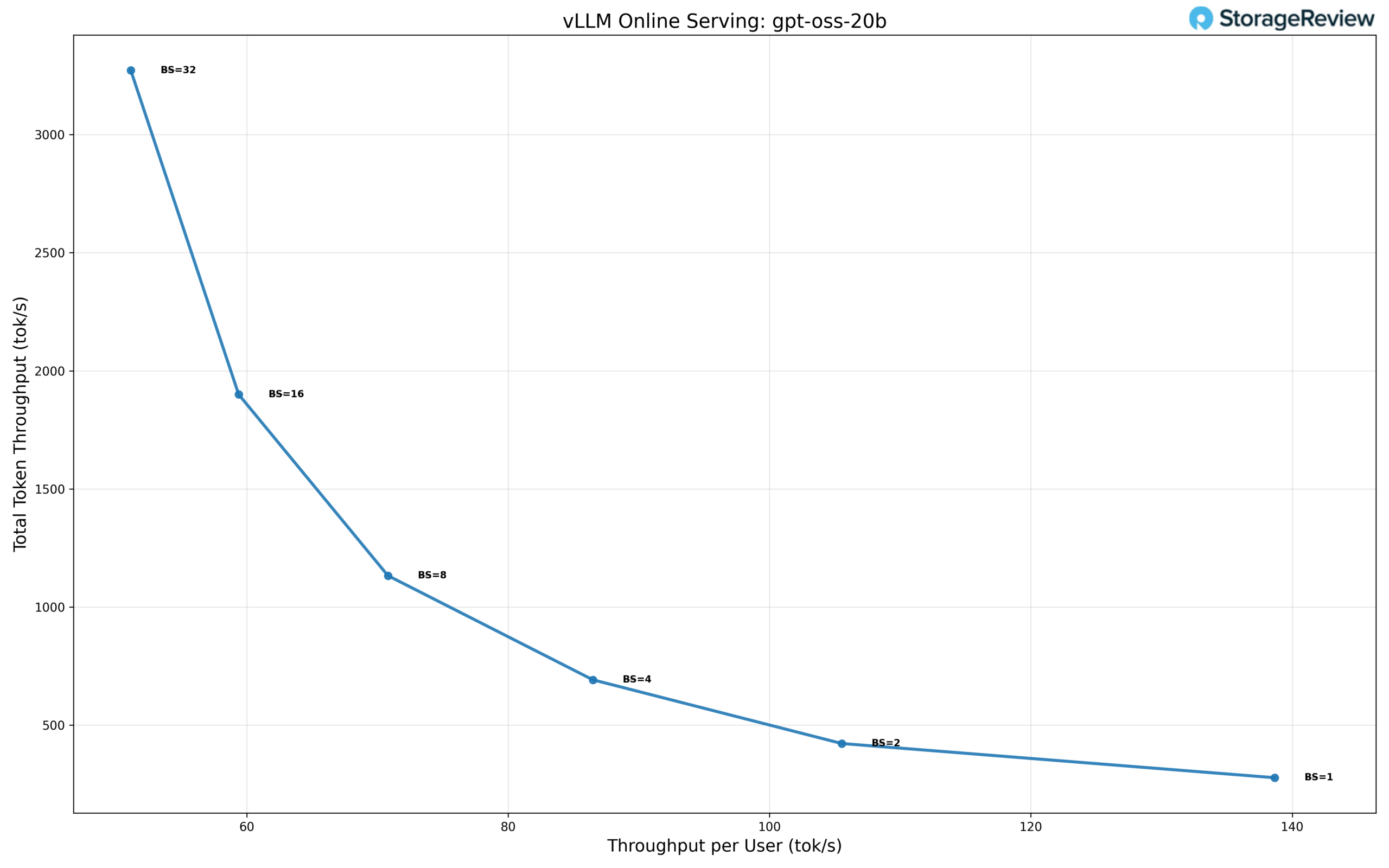
The gpt-oss-20b model demonstrates strong scaling characteristics across increasing concurrency levels, with particularly high aggregate throughput at larger batch sizes. At single-user concurrency (BS=1), the model delivers approximately 138 tok/s per user, resulting in a total throughput of 276 tok/s, establishing a strong baseline for single-stream inference.
As concurrency increases, total throughput scales aggressively while per-user throughput declines as expected. At BS=2, total throughput rises to 420 tok/s, with 105 tok/s per user, and at BS=4, throughput reaches 690 tok/s total, with 86 tok/s per user. This steady progression indicates efficient utilization of available compute resources through low to moderate batching.
Scaling continues through BS=8, where the model achieves approximately 1,120 tok/s total throughput at 70 tok/s per user, and BS=16, where total throughput increases to 1,900 tok/s, with 60 tok/s per user. These results show gpt-oss-20b maintaining relatively high per-user performance even as concurrency rises, making it well suited for multi-user serving scenarios.
The model reaches its peak aggregate throughput at BS=32, delivering approximately 3,250 tok/s total throughput, with per-user throughput dropping to 50 tok/s. This represents an 11.8× increase in total throughput compared to single-user performance. While per-user throughput continues to decline at higher batch sizes, the overall scaling efficiency remains strong, indicating that the model benefits from higher concurrency without encountering an early saturation point.
Overall, gpt-oss-20b exhibits a balanced scaling profile, combining high single-user performance with strong batch scaling. This makes it a compelling option for deployments that need both responsive individual inference and high aggregate throughput under heavier multi-user load.
Phoronix Benchmarks
Phoronix Test Suite is an open-source, automated benchmarking platform that supports over 450 test profiles and 100+ test suites via OpenBenchmarking.org. It handles everything from installing dependencies to running tests and collecting results, making it ideal for performance comparisons, hardware validation, and continuous integration.
Stream Memory Bandwidth
The SR650 V4 delivered 369.6GB/s of memory bandwidth, demonstrating strong throughput for data-intensive workloads and confirming healthy multi-channel memory performance.
7-Zip Compression
With 584,499 MIPS, the system posted excellent compression and decompression performance, reflecting solid multi-core efficiency and strong integer compute capability.
Kernel Compile
The server completed the allmod kernel build in 256.175 seconds, a respectable result that highlights its ability to handle parallel compilation and developer workflows efficiently.
Apache Web Server
At 61,654 R/s, the SR650 V4 showed strong web-serving performance, sustaining a high request throughput suitable for front-end hosting or lightweight virtualization stacks.
OpenSSL Verification
Achieving 712.6 billion bytes per second, the platform demonstrated robust cryptographic verification performance, confirming the CPU’s capability for secure, certificate-heavy operations.
| Phoronix Benchmarks | Lenovo ThinkSystem SR650 V4 |
|---|---|
| Stream | 369,58.3 MB/s |
| 7-ZIP | 584,499 MIPS |
| Kernel Compile (allmod) | 256.175 Seconds |
| Apache (requests per second) | 61,654.47 R/s |
| Open SSL | 712,633,776,990 Bytes/s |
Conclusion
The ThinkSystem SR650 V4 is the kind of platform refresh that matters because it is not just a CPU swap. Lenovo used this generation to push meaningful improvements across the areas that limit real-world deployments: memory bandwidth, PCIe lane availability, storage density, and the ability to adapt the configuration as needs change. The move to Intel Xeon 6 brings more core options and more I/O headroom per socket, and the surrounding platform work, including faster DDR5 with MRDIMM support and optional CXL expansion, gives the SR650 V4 a path to remain relevant as workloads become more memory-hungry.
On the storage side, despite our limited review configuration with U.2, Lenovo’s push toward E3.S offers higher NVMe density with 1:1 connectivity and cleaner thermal characteristics, aligning with how modern infrastructure is being built, especially for virtualization stacks that want more local flash, and for AI-adjacent pipelines where feeding GPUs matters as much as raw compute. The dual OCP 3.0 Gen5 x16 slots also land as a practical upgrade: you can deploy serious networking without sacrificing PCIe slots you would rather reserve for accelerators, storage, or specialty adapters.
If you are on the SR650 V3 and feeling constrained by memory speed, PCIe headroom, or NVMe density, the SR650 V4 is a compelling step forward. It preserves the serviceability and configurability that made the SR650 line popular, while adding the kind of platform runway that helps IT teams avoid painting themselves into a corner. Whether you are building a virtualization cluster, modernizing scale-out services, or assembling a balanced CPU/GPU node, the SR650 V4 checks the boxes that matter and leaves room for what comes next.


 Amazon
Amazon