

VMware recently added NVMe over Fabric (NVMe-oF) as a storage network protocol option in vSphere 7.0. The fact that the fastest shared-storage solution is now able to be used by the world’s most popular virtualization software is a game changer, opening a whole new set of use cases for a virtualized data center. This also means that there are now bare-metal applications capable of running on NVMe-oF enabled virtual machines (VMs) on vSphere. These include artificial intelligence (AI), machine learning (ML), in-memory databases, high-performance computing (HPC), high-frequency trading (HFT), online transaction processing (OLTP), as well as any other application that requires extremely low latency and high-capacity storage.
At StorageReview.com, we are always interested in testing the latest technologies to see how they work in the real world. Given our previous experience with NVMe-oF, we fully expect it to significantly improve application performance for vSphere. To get an actual idea of how NVMe-oF will affect performance, we will compare it to iSCSI, which is the current standard-bearer for block storage in a vSphere data center. But our testing will have a unique twist, as we will not be using highly specialized, niche technology. Instead we will use products commonly found in the data center today. Our testing will be on a Dell R720XD server connected by NVIDIA’s ConnectX-5 dual-port adapters running at 25GbE to a Pure Storage FlashArray//X that supports NVMe-oF.

Before we get to the results of our testing, we will first give you an overview of what VMware supports in the way of NVMe-oF, and then give you a little background on NVMe and NVMe-oF and explain why they are more performant than iSCSI. We will also cover some of the steps we took to set up NVMe on vSphere.
VMware recently enabled NVMe-oF support (April 2020), though the NVMe-oF standard was released in 2016. Linux has been capable of using it since 2018, and NVMe-oF support in storage arrays has been available for a few years as well. NVMe-oF is considered to be an emerging, yet stable technology. In April of 2020, VMware released vSphere 7.0 and this release included support for NVMe-oF, allowing connectivity to NVMe arrays with either NVMe over Fibre Channel (NVMe/FC) or NVMe over RDMA Converged Ethernet (NVMe-RoCE, also referred to as NVMe/RDMA).
Overview of NVMe and NVMe-oF
Until recently, SSDs were the de facto standard media for attached storage. However, they also have a critical bottleneck. SSDs use SATA or SAS connectors, which were designed to be used with HDDs and this severely limits an SSD’s performance. To address this issue, a consortium of over 90 companies coalesced in 2011 and released a new specification to connect SSDs to computers which would not have this SATA bottleneck. This solution eventually became known as NVMe.
NVMe devices are fast. Whereas SATA/SAS SSDs radically changed the storage industry last decade, NVMe is radically changing the storage industry this century. For example, in our recent testing using a 4K Read workload, we found that a SATA drive (Kingston DC500M) could deliver just under 80,000 IOPS, but an NVMe drive (Kingston DC1000M) could deliver 580,000 IOPS, a whopping 7.25 times difference. There are many technical reasons to explain why NVMe is so much more performant than SATA drives, but one of the most important is it has a shorter data path. The diagram below shows a simplified illustration of how the data path is considerably shorter for NVMe when compared to last generation storage like SAS.
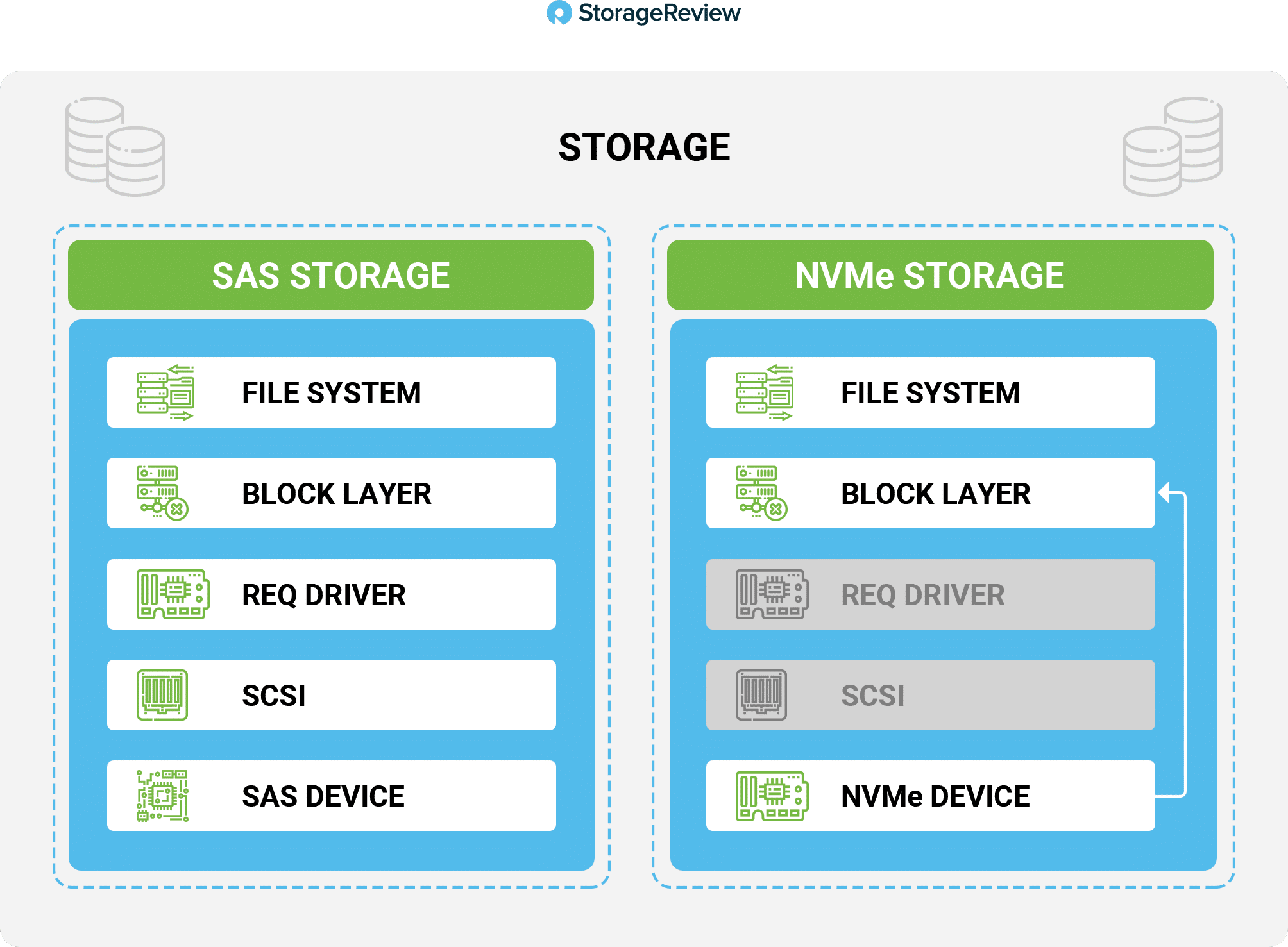 Its performance improvements, coupled with the precipitous drop in the price, have made NVMe the darling of the modern data center.
Its performance improvements, coupled with the precipitous drop in the price, have made NVMe the darling of the modern data center.
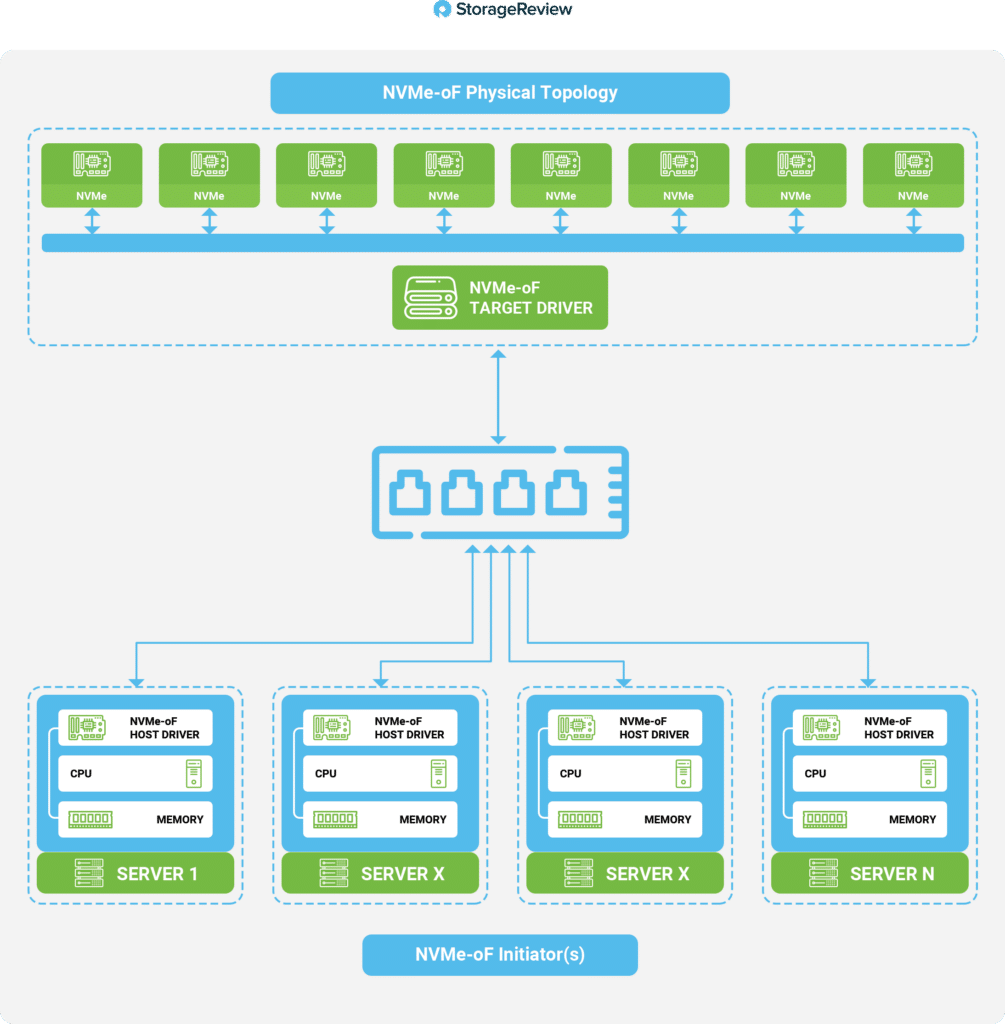
Shortly after NVMe drives became widely used in the data center, people realized that the devices were not being used to their full potential, and their limitation from being direct-attached storage became more apparent. NVMe devices needed to be decoupled from the server, hence another group of companies came together and developed a specification on how to deliver NVMe over a network. Once the transport mechanism for NVMe storage was available, we could aggregate, abstract, and share NVMe devices in a storage system to many different systems, including ESXi hosts. NVMe-oF uses target/initiator terminology.
RoCE allows remote direct memory access (RDMA) over an Ethernet network. There are two versions of RoCE: RoCE v1 and RoCE v2. While RoCE v1 allows communication between any two hosts in the same Ethernet broadcast domain (layer 2), RoCE v2 runs on top of TCP (layer 3) and is therefore routable, allowing it to connect to hosts outside of an Ethernet broadcast domain. Due to its inherent advantages and popularity in the data center, VMware only supports v2. For the duration of this article, we will be referring to RoCE v2 as simply RoCE.
RoCE requires RDMA network interface controllers (rNICs) instead of standard NICs. RoCE networks usually require configuring Priority Flow Control, but Spectrum switches are optimized for congestion control when used with ConnectX adapters, which allows for zero configuration. RoCE is very popular and has a thriving ecosystem that supplies both rNICs and NVMe-oF subsystems. It is currently being used by some of the world’s largest hyperscale data centers, and this has driven the price of rNICs down considerably from when they were first introduced.
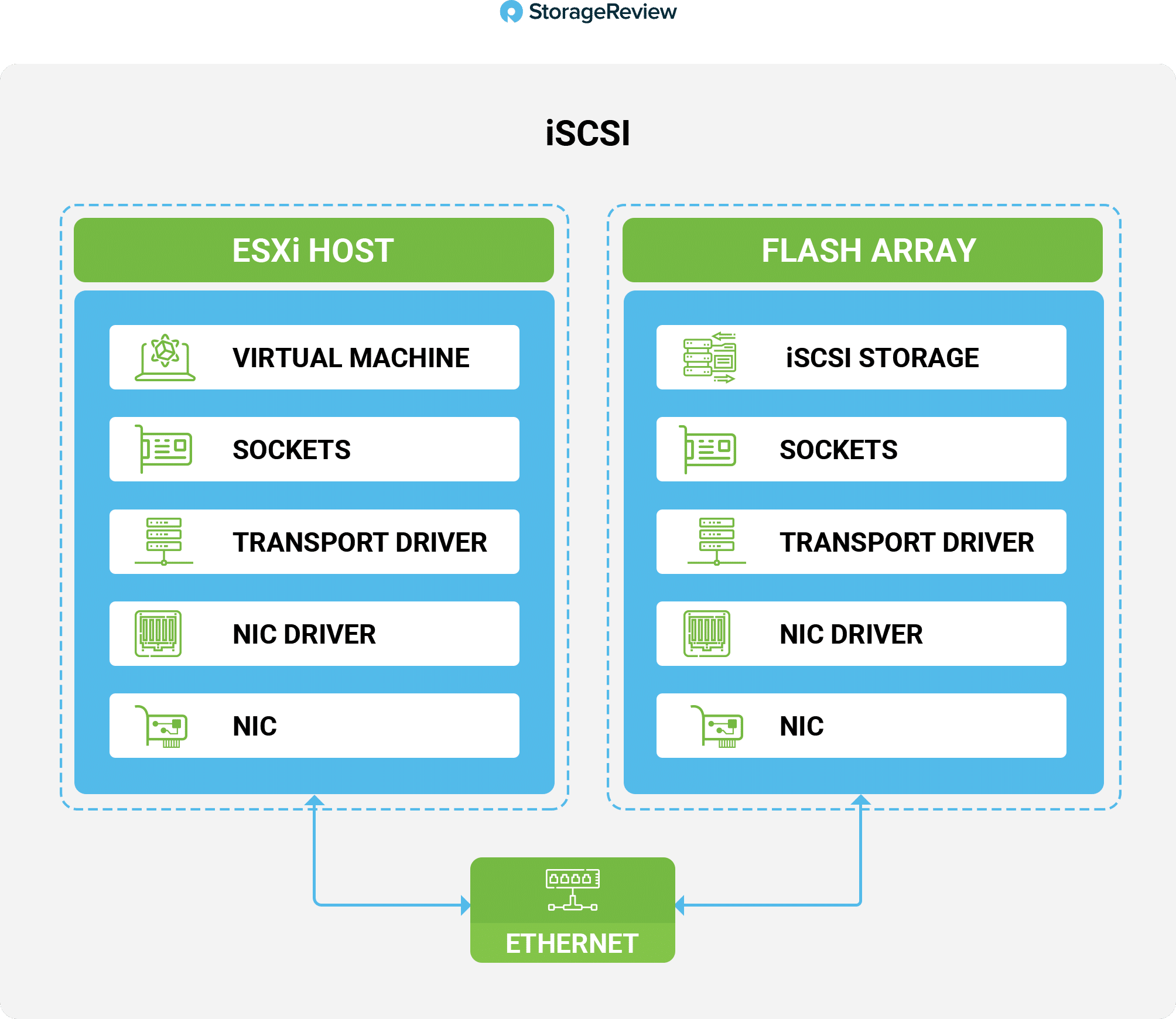
By using RDMA, data can be transferred directly to a host from the NVMe-oF devices without having to be copied to memory buffers, as would be the case if using a standard Transmission Control Protocol/Internet Protocol (TCP/IP) stack. By bypassing the buffers, RDMA reduces the CPU usage on the host and decreases the latency to access the data on the remote NVMe device. There are many technical reasons why NVMe-oF is more performant than last-generation network storage technologies. Of note is the massive number or queues (64K) NVMe-oF supports, but perhaps the most telling is the NVMe-oF data path. The diagram below shows a simplified illustration of how the data path is considerably shorter for NVMe-oF when compared to iSCSI storage.
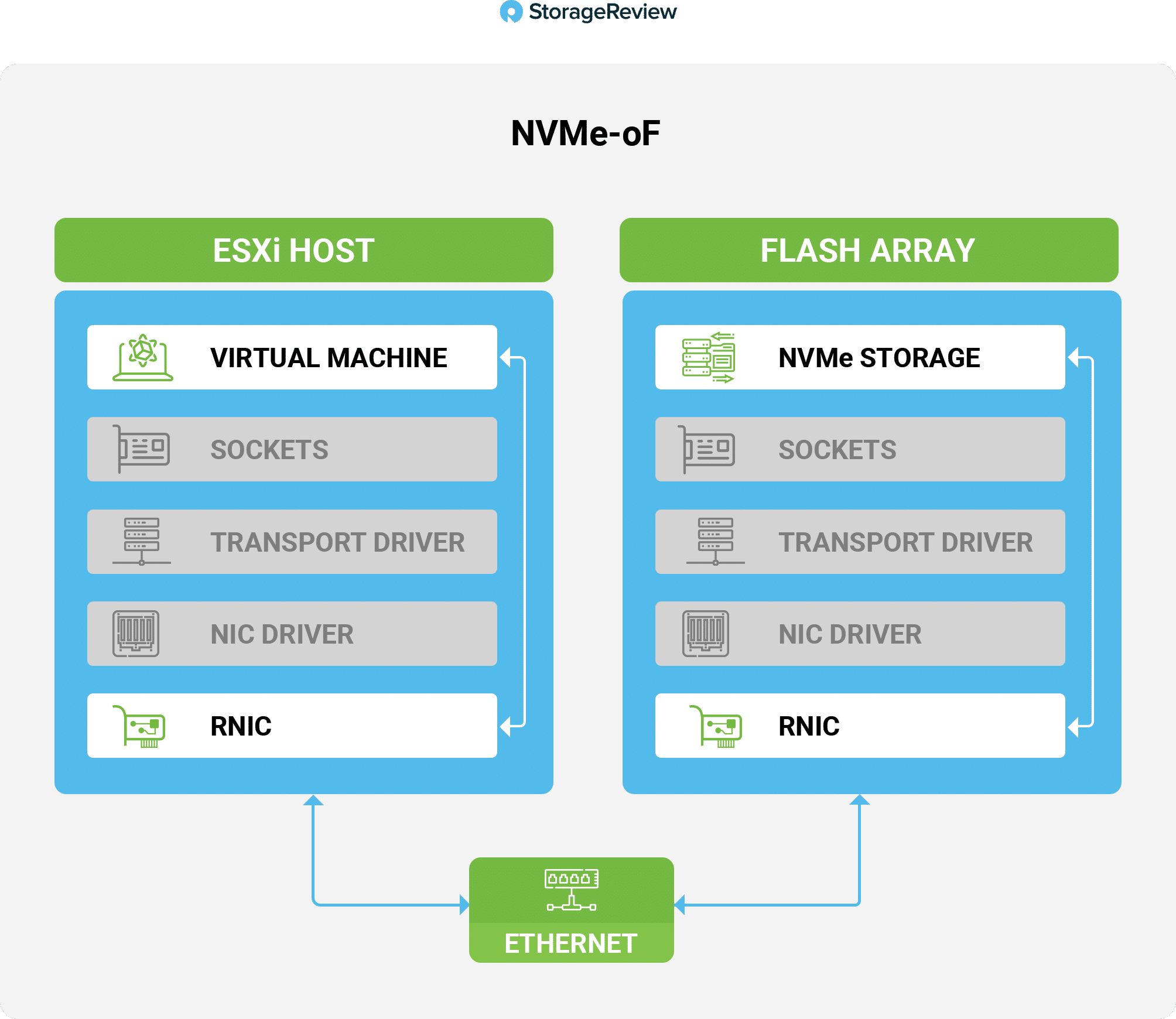
RoCE uses UDP, which impacts performance as UDP requires less overhead. However, RoCE relies on end-to-end compatibility to provide full lossless connectivity. Although modern network switches support lossless connectivity, care must be taken to ensure that an older switch that does not support lossless connectivity is not in the network path of NVMe-oF.
The upshot of all this is that NVMe-oF enables access to a network’s NVMe drives as if they were local to the accessing server. Early reports have shown that the latency for the pooled storage is about 100μs, instead of the 500μs or more of an iSCSI all-flash storage array.
NVMe-oF with vSphere
The requirements for NVMe-oF with vSphere are straight-forward:
- NVMe array supporting RDMA (RoCE) transport
- Compatible ESXi host
- Ethernet switches supporting a lossless network
- Network adapter supporting RoCE
- Software NVMe over RDMA adapter
- NVMe controller
- A lossless network at both layer 2 and layer 3 or lossy network with NVIDIA’s ZTR (Zero Touch RoCE) solution
- Dedicated links, VMkernels, and RDMA adapters to NVMe targets
- Dedicated layer 3 VLAN or layer 2 connectivity
Because NVMe-oF is new to VMware, not all vSphere features are available for it. A few features that we noticed were missing are support for shared VMDKs, Raw Device Maps (RDMs), vVols, and the ability to boot from NVMe-oF.
Implementing NVMe-oF
We used NVIDIA’s ConnectX-5 rNICs, one of the most common cards in the data center. These cards are RDMA-enabled single- or dual-port network adapters. They are available for PCIe Gen 3.0 and Gen 4.0 servers, and provide support for 1, 10, 25, 40, 50 and 100 Gb. They have 750ns latency and can pass up to 200 million messages per second. When used with storage workloads, they support a wide range of acceleration technologies.
For our testing, we ran PCIe Gen 3.0 ConnectX-5 cards at 25GbE in a pair of Dell R720 servers over a network connected via a pair of NVIDIA’s Spectrum SN2010 switches to the Pure Storage flash array.

We first verified that we were running the nmlx5_core driver by entering esxcfg-nics -l |grep -E ‘Name|NVIDIA’.

If we were running the nmlx4_core driver, we could have enabled RoCE for it from the ESXi CLI.
The process for enabling NVMe-oF (similar to that of setting up and enabling iSCSI) involved configuring the vSwitches, port groups, and vmkernel ports on the ESXi hosts. The major difference was that we needed to add at least two software NVMe over RDMA adapters to each ESXi host.
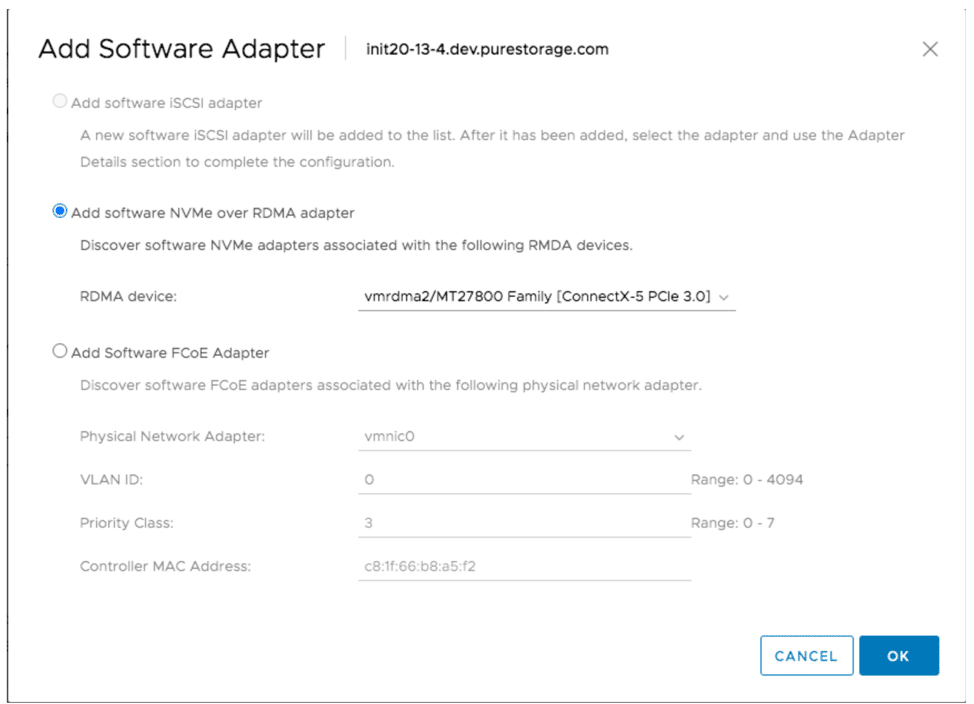
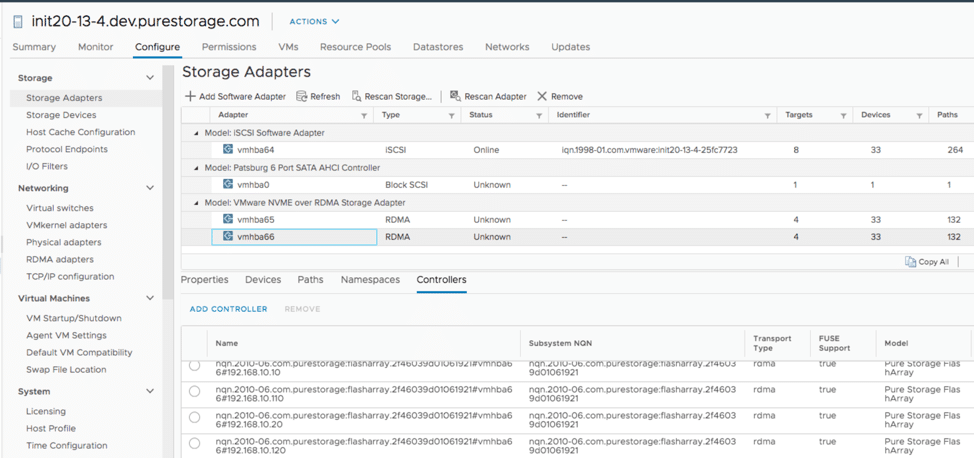
The last step we needed to complete was to identify the NVMe Qualified Name (NQN) of the ESXi host by entering esxcli nvme info get.

On the Pure Storage array, it was similar to setting up an iSCSI array, with one big exception. We needed to select Configure NQNs.
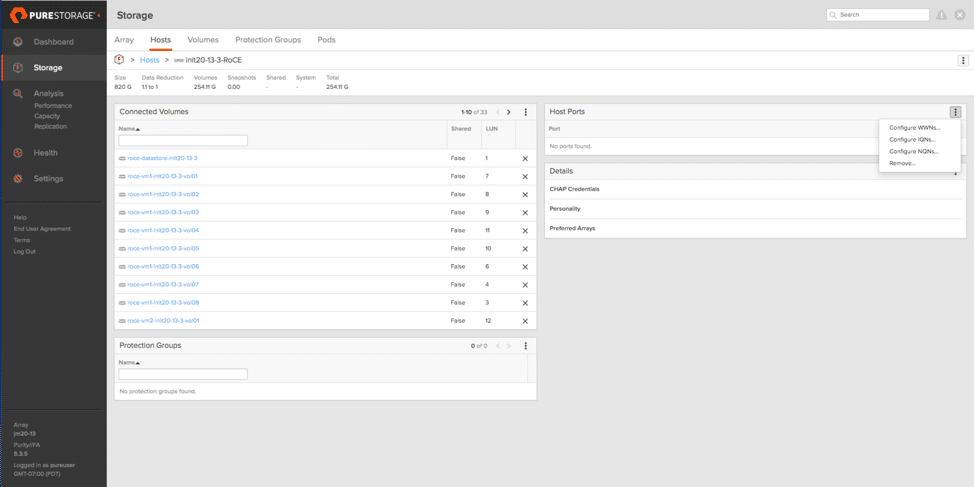
Test Results of NVMe-oF with vSphere
For this testing, we kept all things constant with the exception of the fabric. What we want to evaluate is the impact of moving from more traditional iSCSI to RoCE. To be clear, this isn’t a storage benchmarking exercise; this is an examination to look at the benefits of NVMe-oF in a VMware environment that requires very little change. We used two Dell EMC PowerEdge servers as well as a Pure FlashArray//X R2 for the storage backend.
Our test plan included measuring the aggregate performance of 8 VMs (4 on each ESXi host), and using vdBench to measure traditional four corners and mixed workloads. Each VM consumed 64GB of storage, with a 512GB total footprint per workload available to compare the performance changes as the protocol changed.
To interpret these results, please note that for throughput, an improvement is better, while in latency, a decrease is better.
 In our first workload measuring 4K random read performance at 80% load, we measured an increase in throughput of 14.6% and a drop in read latency by 21.4%.
In our first workload measuring 4K random read performance at 80% load, we measured an increase in throughput of 14.6% and a drop in read latency by 21.4%.
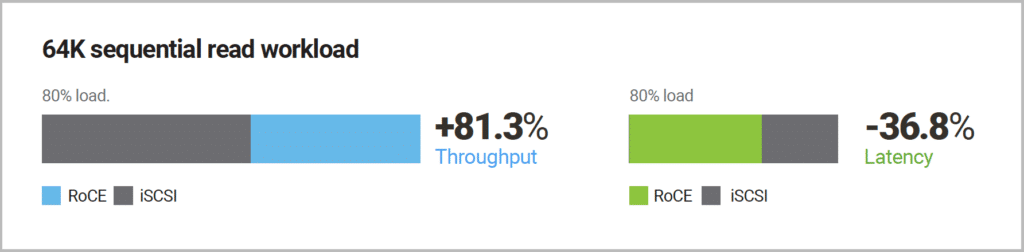 Next, looking at read bandwidth in a 64K sequential read workload, we saw a whopping 81.3% boost in throughput, as well as a 36.8% decrease in latency–again at 80% load.
Next, looking at read bandwidth in a 64K sequential read workload, we saw a whopping 81.3% boost in throughput, as well as a 36.8% decrease in latency–again at 80% load.
 While the largest gains measured were in the read workloads, we also looked at some common mixed workloads, the first of which was SQL 90/10. In this workload, we measured latency decreasing by up to 78.2% at a 100% load and a 43.4% drop in latency at an 80% load.
While the largest gains measured were in the read workloads, we also looked at some common mixed workloads, the first of which was SQL 90/10. In this workload, we measured latency decreasing by up to 78.2% at a 100% load and a 43.4% drop in latency at an 80% load.
 Finally, in our Oracle 90/10 workload, we saw a 13.2% drop in latency at a 100% load and a 35.7% drop in latency at an 80% load.
Finally, in our Oracle 90/10 workload, we saw a 13.2% drop in latency at a 100% load and a 35.7% drop in latency at an 80% load.
In this testing, clearly RoCE had great improvements across a wide swath of workloads common in the enterprise.
Conclusion
Our testing proved that NVMe-oF in the real world is more than just a concept. NVMe-oF can deliver outstanding performance using your data center’s current hardware, such as servers with Gen 3.0 PCI slots, NVIDIA’s ConnectX-5 NICs, and a Pure Storage FlashArray//X R2 (Pure is now shipping //X R3 with even greater performance improvements).
In our testing, we saw significant gains in small- and large-block read workloads. To look at real-world impact, we focused on less than 100% workload saturation, since most workloads aren’t fully saturating the underlying storage platform. In our test measuring 4K random read performance, latency dropped by 21.4% at an 80% workload. Sequential read performance with a 64K workload saw a huge 81.3% increase in throughput at an 80% load. We also saw 43.4% and 35.7% drops in latency in our SQL 90/10 and Oracle 90/10 workloads, respectively, again at an 80% load. These numbers indicate that there’s an additional opportunity to transition demanding bare-metal workloads into VMware.
We are confident that NVMe-oF will be the next big thing in storage technology, and we expect its popularity in the data center to quickly proliferate. We will be at the forefront of this category as it develops out over the next few years, and look forward to investigating other and adjacent NVMe technologies as they are released.
For Additional Information:
This report is sponsored by NVIDIA. All views and opinions expressed in this report are based on our unbiased view of the product(s) under consideration.


 Amazon
Amazon