

Seit Jahren ist automatisiertes Storage Tiering (Speicherschichtung) eine unverzichtbare Lösung für Unternehmen, die ihren Rechenzentrumsfußabdruck effizient verwalten und gleichzeitig die Gesamtbetriebskosten (TCO) senken möchten. Die Strategie ist einfach: Man verwendet Algorithmen und Richtlinien mit automatischer Zeitsteuerung und hält die aktiven Daten auf dem Primärspeicher, während inaktive Daten in kostengünstige Speicherkategorien verschoben werden. In den letzten Jahren hat sich Cloud Tiering als eine robuste, kostengünstige Lösung herauskristallisiert, die die Verlagerung inaktiver Daten auf kostengünstige Objektspeicher in der Cloud verwaltet. Mit der ThinkSystem DM-Serie ermöglicht Lenovo Unternehmen die Verwaltung von Daten und Cloud-Alternativen mit einer intelligenten Speicherlösung. Diese Cloud-Strategie befasst sich erfolgreich mit Kapazität, Agilität und Sicherheit in Hybrid-Cloud-Umgebungen, ohne die Verwaltbarkeit, Sicherheit oder Leistung zu beeinträchtigen.

Dieser Artikel beschreibt, wie Lenovo ThinkSystem Speicherlösungen und die DM Serie eine End-to-End-Strategie für Rechenzentren bieten, von der Vor-Ort-Installation bis hin zur Cloud. Zunächst werden wir einige grundlegende Konzepte zur Datenspeicherung, zum Cloud Tiering und zu neuen Herausforderungen beim Speichermanagement ansprechen. Wir werfen einen Blick auf das Datenmanagement-Ökosystem von Lenovo und darauf, wie sich das Unternehmen mit der DM-Serie auf dem Speichermarkt hervorhebt. Außerdem werfen wir einen genauen Blick auf die ONTAP-Software und die FabricPool-Storage-Tiering-Richtlinien. Und schließlich zeigen wir von unserem Labor aus die Einrichtung und Validierung der Cloud-Tiering-Lösung von Lenovo.
In einem traditionellen Rechenzentrumsmodell beginnt ein wachsendes Unternehmen mit dem Sammeln kritischer Daten und Dateien in seinen Räumlichkeiten. Diese Daten sind jedoch irgendwann veraltet und es wird nur noch selten auf sie zugegriffen, wodurch wertvolle Leistung und Kapazität des primären und sekundären Speichers in Anspruch genommen wird, was sich auf kritische Arbeitslasten auswirkt. Die Archivierung dieser Daten war in der Vergangenheit eine praktische Lösung für Unternehmen; dadurch stehen die Daten jedoch nicht sofort zur Verfügung, wenn sie plötzlich benötigt werden.
Dieses Problem hat bei IT-Organisationen das Bewusstsein dafür geweckt, Speicherebenen mit unterschiedlichen Kapazitäts-, Kosten- und Leistungsmerkmalen in Betracht zu ziehen. Darüber hinaus müssen sie die Anforderungen an das Datenwachstum über mehrere und Cloud-Umgebungen hinweg anerkennen und darauf vorbereitet sein, diese zu erfüllen. Cloud Tiering ist die Antwort, und es muss in modernen Speicherarchitekturen berücksichtigt werden. Andernfalls wird ein wachsender Datenfußabdruck die Investitionen des Unternehmens in hochleistungsfähige Primärspeicher in seinem Rechenzentrum überfordern.
Die Cloud als Speicherstufe
Wenn fortschrittlichere Technologien zugänglich werden, können bestehende Speicherebenen nach Bedarf transformiert und weitere hinzugefügt werden, um die mehrstufige Speicherarchitektur weiter zu diversifizieren. Die Cloud hat IT-Organisationen neue Möglichkeiten eröffnet, indem sie Speicherlösungen von öffentlichen Cloud-Anbietern als zusätzliche (untere) Ebene ermöglicht. Wenn sie gut konzipiert und ausgeführt wird, ist die Cloud eine ausgezeichnete und kostengünstigere Lösung als eine niedrigere On-Prem-Tier-Lösung.
Auf primären Speicherebenen, die Flash für extrem hohe Leistung nutzen, könnten etwa 50% der kalten Daten der Cloud zugewiesen werden. Snapshot-Kopien und unstrukturierte Daten gehören häufig in diese Kategorie, einschließlich unternehmenskritischer Anwendungen. Auf sekundären Ebenen können bis zu 90 % der im Speicher befindlichen Cold-Daten aus Sicherungskopien stammen. All diese wertvollen Daten, auf die nur gelegentlich zugegriffen wird, könnten ebenfalls in die Cloud verschoben werden. Zu den beliebten Cloud-Anbietern und -Diensten, die bereit sind, inaktive Daten in die Cloud zu verschieben, gehören Azure Blob-Speicher, AWS S3 und Google Cloud Storage.
Wie beim automatisierten Speicher-Tiering vor Ort können wir Richtlinien und Regeln zur Verwaltung der Daten für die Cloud erstellen. Die Bedingungen erlauben es uns, Dateien direkt von vor Ort in die öffentliche Cloud zu übertragen. Die Richtlinien werden auf verschiedene Weise angewendet Beispielsweise können Daten auf der Grundlage der Dateierweiterung, von Mustern, die im Dateinamen enthalten sind, oder danach, wie oft innerhalb eines bestimmten Zeitraums auf die Datei zugegriffen wird, verschoben werden. Diese letzte Option ist wahrscheinlich das beste Szenario, bei dem Speicherdateien und -blöcke mit Temperaturwerten versehen werden, wobei neu geschriebene Daten als heiß und inaktive als kalt gekennzeichnet werden. Durch die Implementierung einer Reihe von Richtlinien für die Speicherausrichtung können kalte Daten schnell in die Cloud verschoben werden, indem Regeln nach Bedarf oder nach Zeitplan ausgeführt werden.
Neue Herausforderungen bei der Speicherverwaltung
Die Hauptherausforderungen, die heute auf dem Markt im Zusammenhang mit der Verwaltung von Hybrid-Cloud-Daten zu beobachten sind, bestehen aus Volumen und Vielfalt, Datengeschwindigkeit und Datenintegrität.
Das Datenvolumen wächst nahezu exponentiell. IT-Organisationen müssen nicht nur das Datenwachstum in den Griff bekommen, sondern auch das Datenwachstum und die Datenverwaltung in verschiedenen Umgebungen. Die Menge und Vielfalt der erzeugten Daten ist nach wie vor überwältigend. Ohne die Möglichkeit, diese Daten in einer Hybrid-Cloud-Lösung zu speichern, zu kategorisieren und zu verarbeiten, entgehen Unternehmen wichtige Erkenntnisse über ihre Kunden und ihr Geschäft. Darüber hinaus wird vorhergesagt, dass das Datenvolumen bis 2025 um das 10-fache (ca. 163ZB) ansteigen wird, angetrieben durch IoT und Spitzentechnologie. Wenn Daten das wertvollste Gut sind, müssen sie mit Sorgfalt behandelt werden und in der Lage sein, Erkenntnisse für gezielte Entscheidungen zu liefern und gleichzeitig einen Blick in die Zukunft zu ermöglichen. Darüber hinaus ist es für die Kaufentscheidungen der Kunden von entscheidender Bedeutung, effizientere Wege zur Verarbeitung dieser Daten zu finden, um sie in einen Wert umzuwandeln.
Auch IT-Bedrohungen entwickeln sich weiter – und die Sicherheit der Infrastruktur ist ein ständiger Kampf. Eine gute Sicherheitsstrategie besteht darin, eine solide Grundlage zu schaffen, die darauf beruht, genau zu wissen, wann, wo und wie Daten gespeichert werden Eine solche Strategie hilft Unternehmen, die steigenden Kosten zu vermeiden, die mit Datenverstößen sowie mit neuer Malware, Katastrophen und Vorschriften verbunden sind, die erhebliche Risiken für den Betrieb darstellen. Datensicherheit ist für Unternehmen von absoluter Wichtigkeit, sei es zum Schutz vor Datenverlust oder zur Gewährleistung der Datenintegrität. Hier deckt Lenovo alle Möglichkeiten ab und stellt sicher, dass die Daten seiner Kunden stets geschützt sind.
Lenovo ThinkSystem Speicherlösung
Neue Entwicklungen zu antizipieren ist ebenso eine Herausforderung wie die beste Speicher- und Cloud-Strategie zu verfolgen. Die Branche hat jedoch bereits enorme Investitionen in Forschungsökosysteme und -plattformen getätigt, die dem Unternehmen einen Mehrwert und Möglichkeiten bieten. Mit dem nächsten strategischen Schritt für die Speicherbranche hat Lenovo seine Lösung auf die wichtigsten Herausforderungen im Datenmanagement zugeschnitten. Dieser kluge Schritt von Lenovo zielt darauf ab, seinen Kunden die ultimative Lösung zu bieten und bietet eine einzigartige Mischung aus Produkten und Dienstleistungen, die es Unternehmen ermöglicht, die Hybrid-Cloud optimal zu nutzen.
Lenovo ist eines der einzigartigen Technologieunternehmen auf dem Markt, das über die Lenovo Data Center Group (DCG) eine End-to-End-Rechenzentrumslösung anbietet. Darüber hinaus bietet Lenovo mit seinem Intelligent Device Group (IDG)-Ökosystem eine End-to-End-Sicherheits- und Software-Verwaltung. Mit diesen Angeboten und der ThinkSystem DM-Serie von Lenovo können Unternehmen ihre Infrastruktur verbessern und jede in ihrer Umgebung laufende Arbeitslast bewältigen.
Die ThinkSystem DM Serie ist Lenovos Flaggschiff-Speicherlösung, die eine vielseitige Datenmanagement-Suite für strukturierte und unstrukturierte Daten bietet. Sie reicht vom Einstiegsbereich bis hin zur oberen Mittelklasse und bietet datenintensive Funktionen wie integrierte Datenreduzierung, Datenschutz und Datensicherheit Jede der DM-Serien kann integrierte Hybrid-Cloud-Funktionen für Lösungen von Public-Cloud-Anbietern bereitstellen. Gleichzeitig baut Lenovo seine End-to-End NVMe-Angebote mit der kürzlich veröffentlichten DM7100F-Serie aus und plant noch in diesem Jahr, das Angebot von End-to-End NVMe auf weitere Einstiegs-Workloads für Kunden auszuweiten, um eine infrastrukturweite NVMe-Struktur für Unternehmen zu schaffen.
FabricPools
Die Data Management Suite der DM-Serie vereinheitlicht die Datenverwaltung über Flash, Festplatte und Cloud und vereinfacht so Speicherumgebungen. Diese umfassende Software ist einfach zu bedienen und hochflexibel, für effiziente Speicherung konzipiert und verfügt über robuste Datenverwaltungsfunktionen sowie eine nahtlose Cloud-Integration. Insgesamt zielt die DM-Serie darauf ab, die Bereitstellung und Verwaltung von Daten zu vereinfachen und Unternehmensanwendungen zu fördern, d.h. sie ist zukunftssicher für Dateninfrastrukturen.
Neben der bordeigenen Datenmanagement-Funktionalität steht die FabricPool Cloud Tiering-Technologie zur Verfügung. Sie ermöglicht das automatisierte Tiering von Daten auf kostengünstige S3-Objektspeicherebenen, die sich entweder vor Ort oder in der öffentlichen Cloud befinden. Im Gegensatz zu manuellen Tiering-Lösungen automatisiert FabricPool das Tiering von Daten, um die Speicherkosten zu senken. Aktive Daten verbleiben auf Hochleistungslaufwerken und inaktive Daten werden zum Objektspeicher gestaffelt, wobei die Funktionalität und die Dateneffizienz der DM-Serie erhalten bleiben.
FabricPool unterstützt eine breite Palette von öffentlichen Cloud-Anbietern und deren Speicherdienste. Dazu gehören Amazon S3, Alibaba Cloud Object Storage Service, Microsoft Azure Blob Storage, Google Cloud Storage, IBM Cloud Object Storage und private Clouds. Kunden profitieren auch von der Beibehaltung der integrierten Datenreduzierungsfunktionen beim Verschieben von Daten in und aus der Cloud. Dies spart Transportkosten, wenn Daten aus der Cloud zurückversetzt werden müssen. Darüber hinaus schützt die integrierte Datenverschlüsselung sowohl die Daten während der Übertragung in die Cloud als auch die Daten in der Cloud. Dadurch wird sichergestellt, dass es während des gesamten Cloud-Tiering-Prozesses keine Schwachstellen gibt.
FabricPool Richtlinien
FabricPool hat zwei primäre Anwendungsfälle: die Rückgewinnung von Kapazität auf dem Primärspeicher oder die Verkleinerung des sekundären Speicherplatzes. Unser Schwerpunkt in diesem Artikel liegt auf der Möglichkeit, Kapazität im Primärspeicher zurückzugewinnen. Es gibt drei verschiedene und einzigartige Richtlinien für das Cloud Tiering von Primärspeicher: Auto-Tiering, nur Snapshots und All-Tiering.
Die Beibehaltung von Daten, auf die nur selten zugegriffen wird und die mit Produktivitätssoftware, abgeschlossenen Projekten und alten Datensätzen auf Primärspeicher verbunden sind, ist eine ineffiziente Nutzung von Hochleistungs-Flash-Speicher. Das Tiering dieser Daten zu einem Objektspeicher ist eine einfache Möglichkeit, vorhandene Flash-Kapazität zurückzugewinnen und die erforderliche Kapazität in Zukunft zu reduzieren. Die Auto-Tiering-Richtlinie verschiebt alle Cold Blocks im Volumen auf die Cloud-Ebene. Wenn sie durch zufällige Lesevorgänge gelesen werden, werden kalte Datenblöcke auf der Cloud-Ebene heiß und werden auf die lokale Ebene übertragen. Beim Lesen durch sequentielle Lesevorgänge, z. B. in Verbindung mit Index- und Antiviren-Scans, bleiben kalte Datenblöcke auf der Cloud-Ebene kalt und werden nicht auf die lokale Ebene geschrieben.
Snapshot-Kopien können häufig mehr als 10 % einer typischen Speicherumgebung beanspruchen. Obwohl diese Point-in-Time-Kopien für die Datensicherung und die Notfallwiederherstellung unerlässlich sind, werden sie nur selten verwendet und stellen eine ineffiziente Nutzung von Hochleistungs-Flash dar. Die Snapshot-Only Tiering Policy für FabricPool ist eine einfache Möglichkeit, Speicherplatz auf Flash-Speicher zurückzugewinnen. Während unserer Tests wurde Snapshot-Only als Richtlinie zum Testen von Cloud-Tiering-Operationen verwendet. Kalte Snapshot-Blöcke im Volume, die nicht für das aktive Dateisystem freigegeben sind, werden in die Cloud-Ebene verschoben. Wenn sie gelesen werden, werden kalte Datenblöcke auf der Cloud-Ebene heiß und werden auf die lokale Ebene übertragen.
Eine der häufigsten Anwendungen von FabricPool ist das Verschieben ganzer Datenmengen in Clouds. Abgeschlossene Projekte, Legacy-Reports oder historische Aufzeichnungen sind ideale Kandidaten, die in eine kostengünstige Objektspeicherung gestaffelt werden können. Das Verschieben ganzer Volumen erfolgt durch die Einstellung der All Tiering Policy auf einem Volumen. Diese Richtlinie wird in erster Linie für sekundäre Daten- und Datensicherungsvolumen verwendet. Sie kann jedoch auch dazu verwendet werden, alle Daten in Lese-/Schreib-Volumes zu staffeln.
Daten in Volumen, die die All Tiering Policy verwenden, werden sofort als kalt gekennzeichnet und so schnell wie möglich in die Cloud gestaffelt. Es muss nicht eine Mindestanzahl von Tagen abgewartet werden, bevor die Daten als “kalt” und “gestaffelt” gekennzeichnet werden. Wenn sie gelesen werden, bleiben kalte Datenblöcke auf der Cloud-Ebene kalt und werden nicht auf die lokale Ebene zurückgeschrieben.
Mit Lenovo steht auch eine vierte Option für die Abstufung zur Verfügung, die treffend als “Keine” Abstufung bezeichnet wird. Bei diesem Vorgang werden keine Daten gestaffelt, so dass alle Daten in Flash verwaltet werden können. Ein gutes Beispiel für ihre Verwendung sind Snapshots in DevOps-Umgebungen, in denen häufig die früheren Point-in-Time-Kopien verwendet werden.
Lenovo Storage Cloud Tiering Konfiguration
Um die Fähigkeiten und einige der Funktionen der Lenovo Speicherlösung für die Cloud zu testen, haben wir in unserem Labor ein DM7000F-Modell eingerichtet.
Zunächst haben wir mit Azure Blob Storage, unserer Cloud-Lösung für diesen Test, einen Speichercontainer erstellt. Auch hier ist es gut, die breite Palette der von Lenovo angebotenen Optionen zu beachten, zu denen Alibaba Cloud, Amazon S3, Google Cloud, IBM Cloud und andere gehören. Während des Tests ging es darum, Microsoft Azure Blob Storage für die Cloud als Cloud-Tier für FabricPool zu verwenden. Nachdem wir die Einrichtung des Cloud-Speichers abgeschlossen hatten, war es an der Zeit, sich bei der GUI-Oberfläche des DM7000 anzumelden.
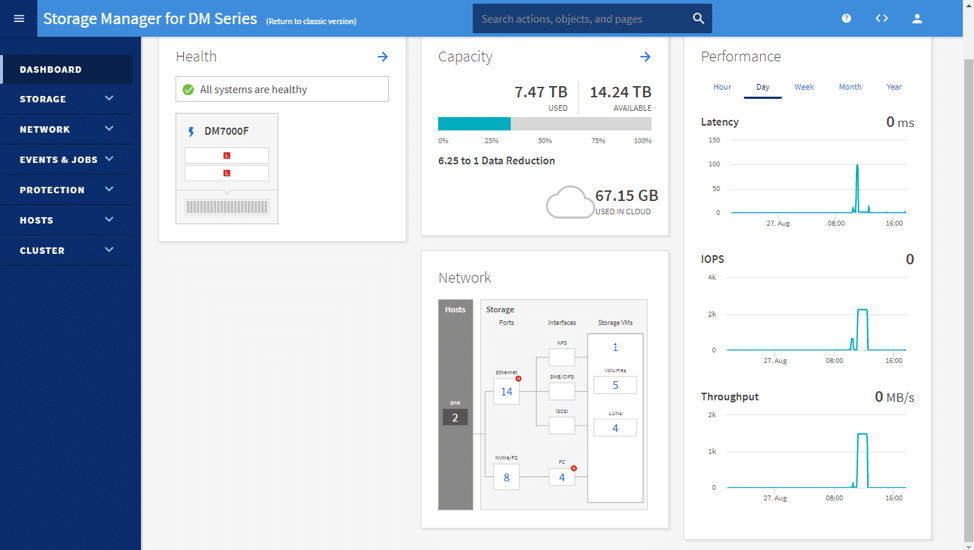
Sobald man angemeldet ist, erscheint die Standard-Dashboard-Seite. Das Dashboard zeigt den Zustand, die Kapazität, die Leistung und die Netzwerkinformationen des fraglichen Arrays an.
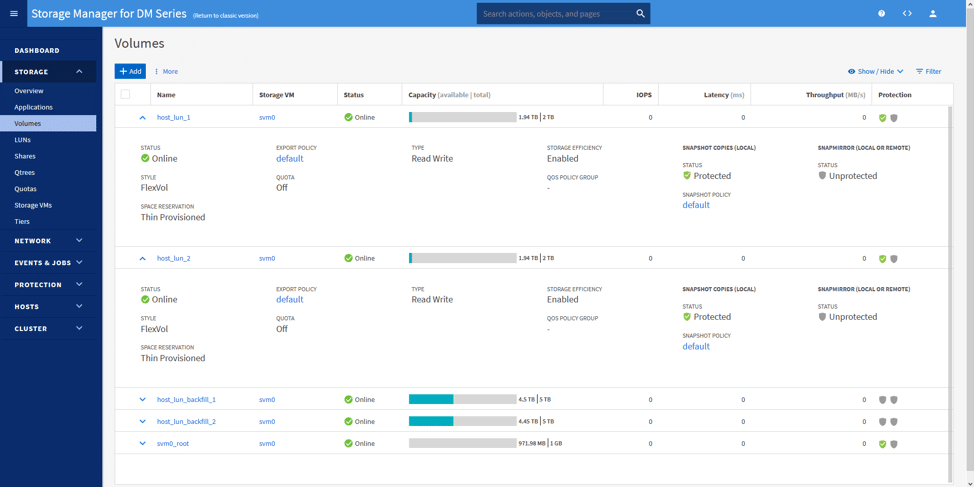
Wir haben dann zwei Volumen (eines pro Controller) und zwei VMs (eines für jedes Volumen) erstellt. Der Plan war, diese VMs laufen zu lassen und sie dann für eine Weile untätig zu lassen. Das folgende Bild zeigt die verwendeten Volumen: host_lun_1 und host_lun_2.
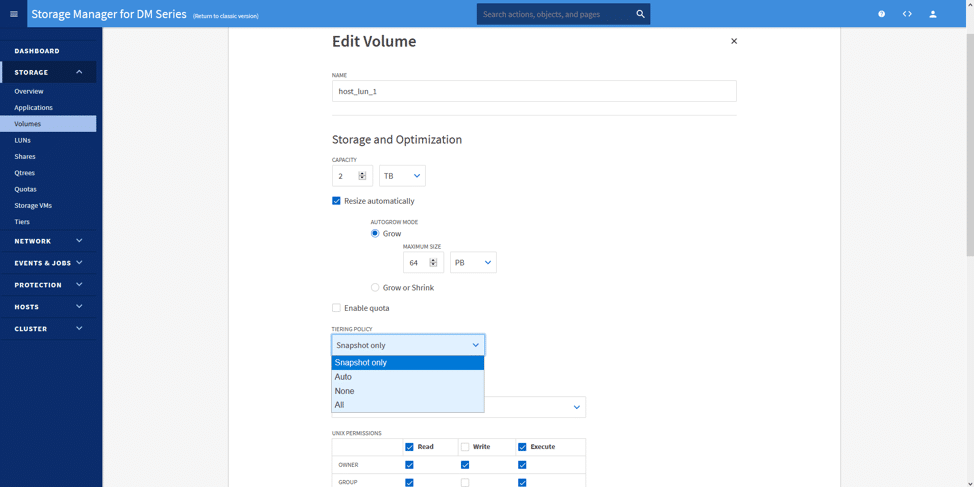
Während der Bearbeitung oder Erstellung des Volumens können wir die gewünschte Einstufungsrichtlinie auswählen. Hier haben wir nur Snapshot ausgewählt. Wenn wir diese Tiering-Politik auswählen, wandern unsere Daten (die nach jedem Snapshot als kalt angesehen werden) in den Azure Blob Storage, der in einem Hintergrundintervall erstellt wurde. Das Intervall läuft zu seiner eigenen Zeit und sagt voraus, wann die Arbeitslasten am wenigsten beeinträchtigt werden.
Unter der Tiers-Seite können wir unsere Cloud-Ebene aus den öffentlichen Clouds hinzufügen. Hier haben wir die Azure Blob Storage-Ressource angehängt und mit den beiden lokalen Speicherebenen verbunden. Unter dem Bild unten sehen Sie zwei Ressourcen, die mit Azure verbunden sind.
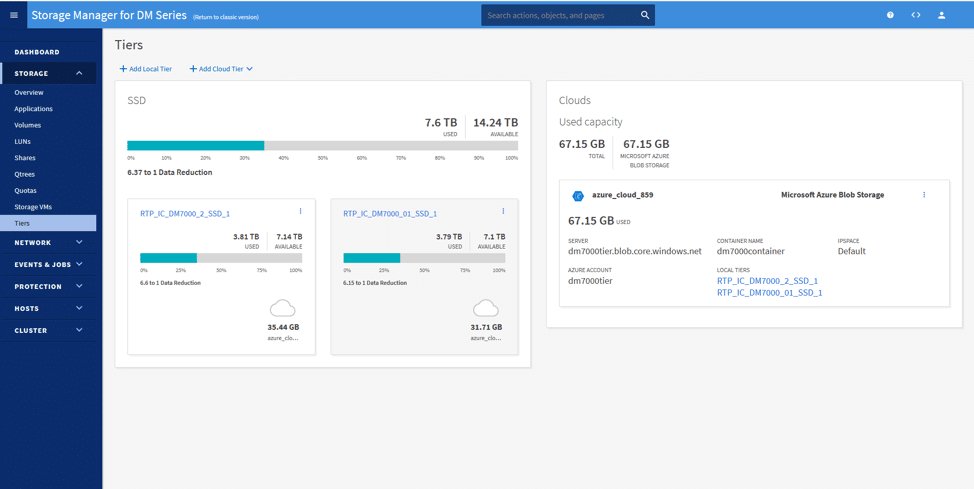
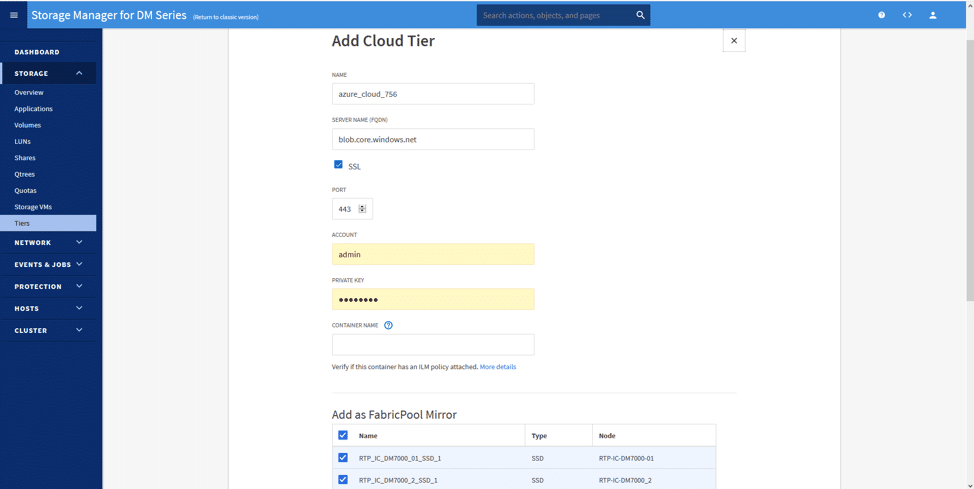
Die Konfiguration ist einfach; durch Klicken auf “Add Cloud Tier” (Cloud-Ebene hinzufügen) und Auswahl der gewünschten Cloud (in diesem Szenario Azure) könnten wir sofort die Cloud-Ebene einrichten.
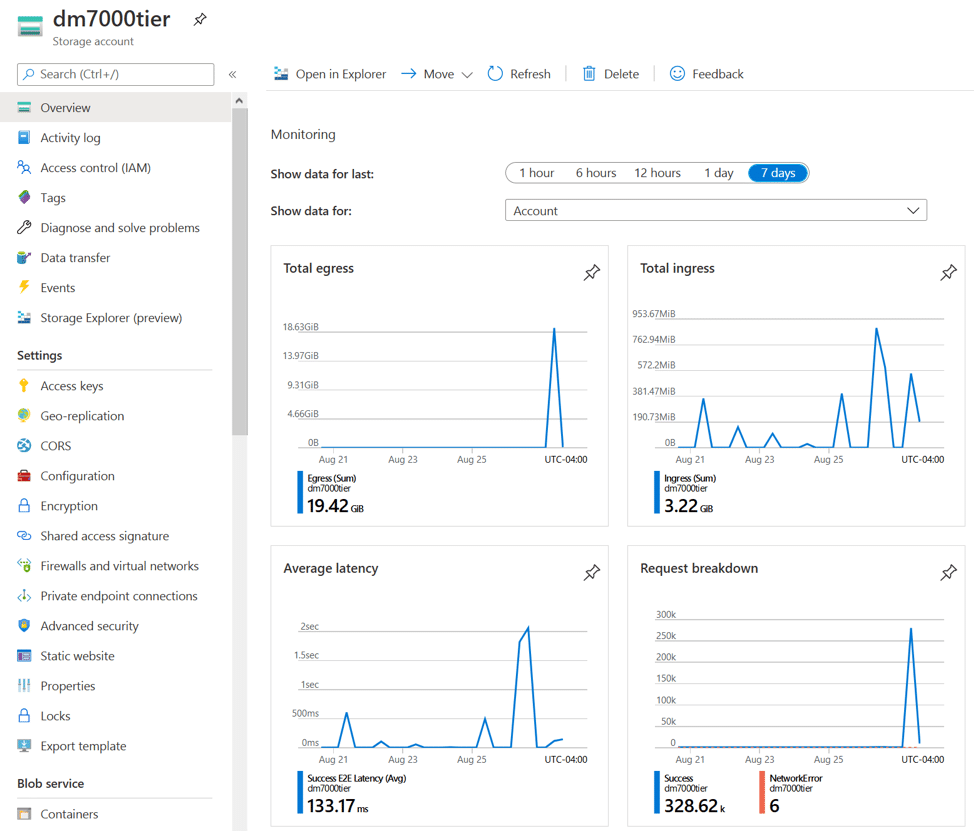
Schließlich wollten wir von unserem Azure Storage-Account-Dashboard aus sowohl Daten anzeigen, die in Azure eingehen (ingress), als auch Daten, die aus Azure herausgehen (egress). Die kleinen Spitzenwerte, die jeden Tag angezeigt werden, sind neue Momentaufnahmen von Daten, die nach Azure übertragen werden. Auf der anderen Seite zeigen die Austrittsspitzen ausgehende Daten und illustrieren eine Snapshot-Wiederherstellung von einem Volume zum Zurückfahren.
Schlussbemerkungen
Im Allgemeinen ist die Cloud und die Verwaltung der Daten ein breites, sich entwickelndes Thema in Unternehmen. Lenovo möchte Lösungen anbieten, die Kunden auf wechselnde Anforderungen vorbereiten, sei es im Rechenzentrum oder über Hybrid-Cloud-Umgebungen. Wir bei StorageReview sind ziemlich beeindruckt von Lenovos Ansatz für ihre Speicher-Arrays. Durch diese Evaluierung haben wir erfahren, wie das Tiering von Daten in die Cloud vom Storage Manager für die DM-Serie funktioniert und wie wertvolle Flash-Kapazität zurückgewonnen oder in die Cloud erweitert wird. Wichtig ist, dass das DM7000F-Speichersystem diese Flexibilität bietet, ohne Änderungen an der Infrastruktur vorzunehmen. Darüber hinaus ist die Funktionalität einfach zu implementieren
Unterstützt von der DCG und der IDG sehen wir Lenovo in einer starken Position auf dem Datenspeichermarkt. Ihre Speicherlösungen ermöglichen es den Kunden, das zu kaufen, was sie heute benötigen, und gleichzeitig die Cloud zu nutzen, um die Anforderungen an das Datenwachstum der Zukunft zu erfüllen. Das Ergebnis ist, dass das Lenovo Cloud Tiering die Kosten reduziert und Unternehmen die Flexibilität ermöglicht, die sie sich wünschen, wenn sie eine Investition in Speicherlösungen in Erwägung ziehen.
Lenovo ThinkSystem DM Serie Speicher-Arrays
Dieser Bericht wurde von Lenovo unterstützt. Alle in diesem Bericht zum Ausdruck gebrachten Ansichten und Meinungen basieren auf unserer unvoreingenommenen Sicht auf das/die in Frage kommende(n) Produkt(e).


 Amazon
Amazon