

The fundamental unit of intelligence in modern AI interactions is the token. Whether powering clinical diagnostics, interactive gaming dialogue, or autonomous customer service agents, the scalability of these applications depends heavily on tokenomics. Recent MIT Data indicate that advances in infrastructure and algorithmic efficiency are reducing inference costs by up to 10x annually. Leading inference providers, including Baseten, DeepInfra, Fireworks AI, and Together AI, are now using the NVIDIA Blackwell platform to achieve these efficiencies, often outperforming the previous Hopper generation by an order of magnitude.
Healthcare Efficiency via Baseten and Sully.ai
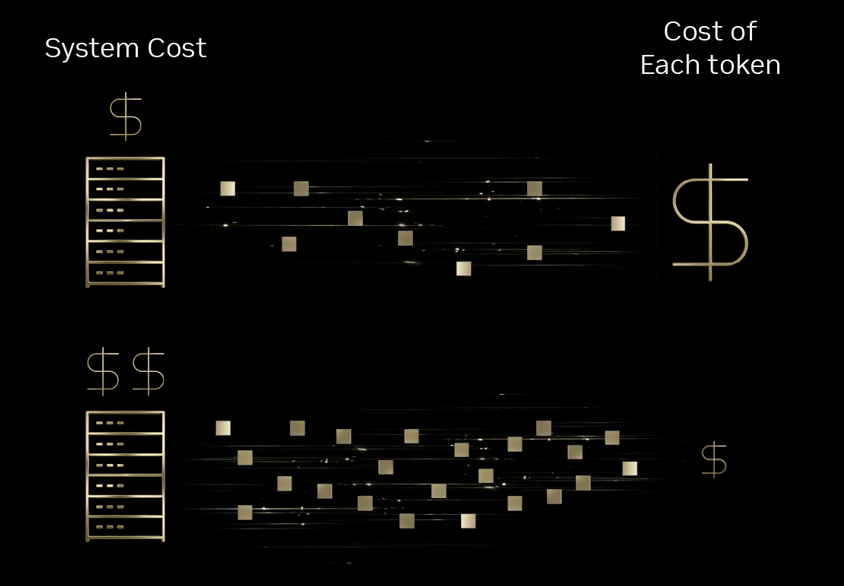
In the healthcare sector, administrative burdens such as medical coding and documentation significantly detract from patient care. Sully.ai addresses this by deploying AI agents to automate these routine tasks. Previously, the company faced bottlenecks, including unpredictable latency and inference costs that outpaced revenue growth when using proprietary, closed-source models.
By migrating to Baseten’s Model API, which uses open-source models on NVIDIA Blackwell GPUs, Sully.ai achieved a 90 percent reduction in inference costs. Baseten optimized the stack with the NVFP4 data format, TensorRT-LLM, and the NVIDIA Dynamo inference framework. The transition delivered 2.5x the throughput per dollar compared with Hopper and a 65% improvement in response times. To date, the implementation has reclaimed over 30 million minutes for physicians by automating manual data entry.
Gaming Performance with DeepInfra and Latitude
Latitude, the developer behind AI Dungeon and the Voyage RPG platform, faces unique scaling challenges because every player action requires an inference request. Maintaining seamless gameplay requires low latency and cost-effective token delivery. By running large-scale Mixture-of-Experts (MoE) models on DeepInfra’s Blackwell-powered infrastructure, Latitude has achieved significant cost improvements.

DeepInfra reduced the cost per million tokens from 20 cents on Hopper to 10 cents on Blackwell. By leveraging Blackwell’s native low-precision NVFP4 format, costs were further halved to 5 cents per million tokens. This 4x improvement enables Latitude to deploy more sophisticated models and handle traffic spikes without compromising the user experience or accuracy.
Scaling Agentic Workflows with Fireworks AI and Sentient
Sentient Labs develops open-source reasoning AI systems, such as Sentient Chat, which orchestrates multi-agent workflows. These complex interactions often trigger a cascade of autonomous tasks, resulting in significant infrastructure overhead. Utilizing Fireworks AI’s inference platform on NVIDIA Blackwell, Sentient achieved a 25 to 50 percent increase in cost efficiency over Hopper-based deployments.
The increased throughput per GPU enabled Sentient to handle massive concurrency. During a viral launch phase, the platform processed 1.8 million waitlisted users within 24 hours and managed 5.6 million queries in a single week. The Blackwell-optimized stack maintained consistently low latency despite the high query volume.
Enterprise Voice Support via Together AI and Decagon
Decagon provides AI agents for enterprise customer support, where voice interactions require sub-second response times to remain viable. Together AI hosts Decagon’s multimodel voice stack on NVIDIA Blackwell, implementing optimizations such as speculative decoding and caching of repeated conversation elements.

These technical refinements reduced response times to under 400 milliseconds, even for queries involving thousands of tokens. By combining open-source and in-house models with Blackwell’s hardware-software co-design, Decagon reduced the cost per query by 6x compared to proprietary closed-source alternatives.
The Future of Tokenomics
The transition to NVIDIA Blackwell, particularly the GB200 NVL72 system, marks a shift in how reasoning MoE models are deployed at scale. The platform’s ability to deliver a 10x reduction in cost per token is a result of deep integration across compute, networking, and software layers. Looking ahead, the upcoming NVIDIA Rubin platform is expected to continue this trajectory, delivering a further 10x improvement in performance and token cost efficiency compared with the Blackwell architecture.


 Amazon
Amazon