

Microsoft has introduced Maia 200, a new custom inference accelerator designed to improve the economics of AI token generation at scale. Positioned as the company’s first silicon and system platform optimized specifically for AI inference.

Microsoft frames AI inference around an “efficient frontier” that balances capability and accuracy against cost, latency, and energy. In practice, that frontier looks different depending on the workload: interactive copilots prioritize low latency, batch summarization and search emphasize throughput per dollar, and advanced reasoning pushes sustained performance under long context windows and multi-step execution. Microsoft’s message is that infrastructure can no longer be one-size-fits-all, and that Azure needs a portfolio of serving options tuned to different inference profiles.

Microsoft Maia Rack
Microsoft says Maia reflects a full-stack approach spanning software, silicon, systems, and data centers, and claims a 30% improvement in performance per dollar compared with the latest-generation hardware currently deployed in its fleet. The company is positioning this integrated design as a foundational advantage as agentic applications become more complex and more widely adopted.

Microsoft Maia 200 Server Blade
Maia 200: Key architectural claims and peak specs
Maia is built around narrow-precision execution, a memory hierarchy designed to reduce off-chip traffic, and an Ethernet-scale-up design intended to keep multi-accelerator inference efficient.
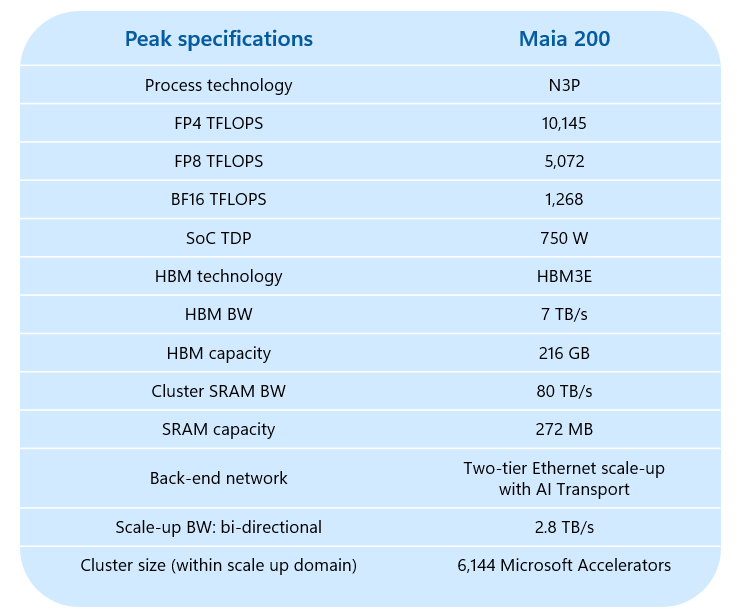
Microsoft highlights several peak-level specifications and design points. Maia uses optimized narrow-precision datapaths on TSMC’s N3 process and is rated at 10.1 PetaOPS FP4 peak. Microsoft is leaning into FP4 as the cost-efficient inference format, aiming for higher tokens per dollar and per watt.
Memory is a significant theme. Maia combines 272 MB of on-die SRAM with 216GB of HBM3e, and Microsoft quotes 7TB/s of HBM bandwidth. The goal is to keep critical working sets local, reduce HBM bandwidth demand through better locality, and improve energy efficiency by minimizing off-chip movement.
For data movement, Maia pairs a multi-level DMA subsystem with a hierarchical network-on-chip to maintain predictable performance for heterogeneous, memory-bound workloads. Microsoft is emphasizing the overlap between data movement and compute, as well as structured support for tensor-friendly layouts.
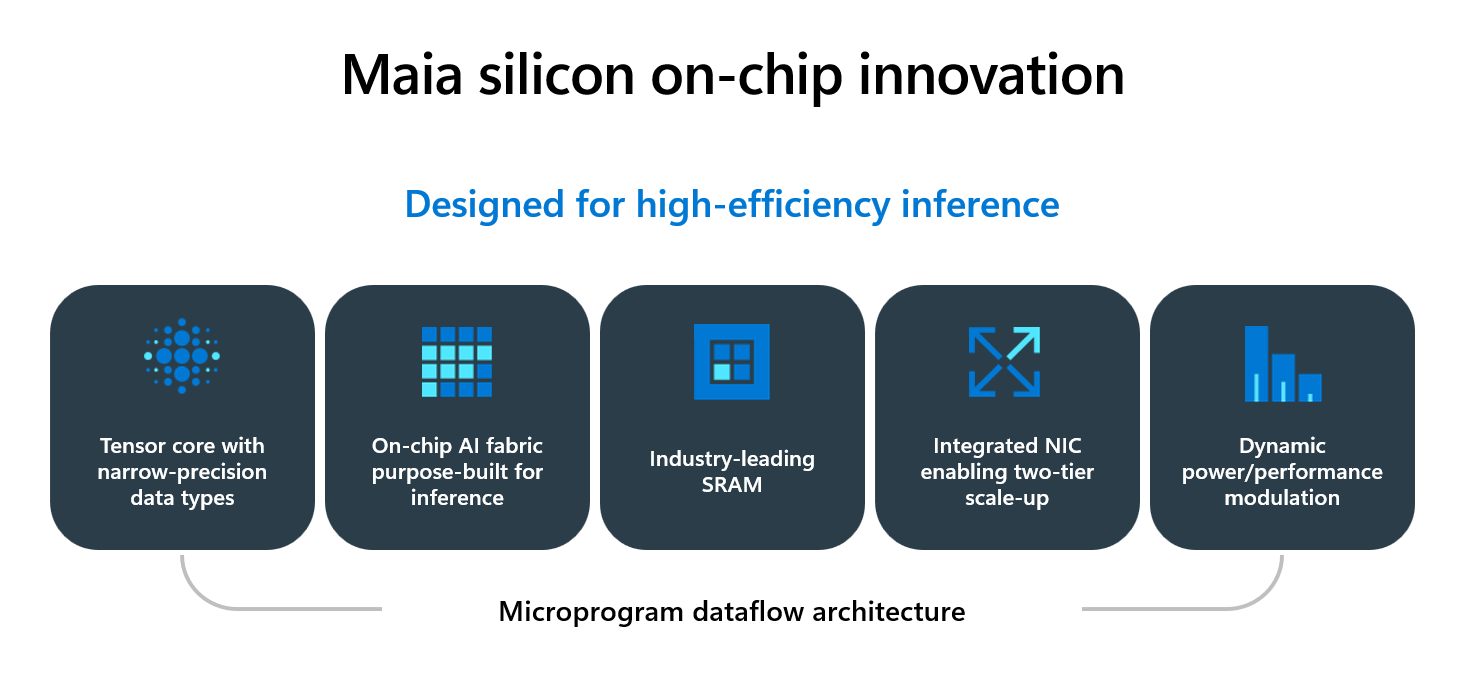
For scale-up, Maia integrates an on-die NIC and an Ethernet-based interconnect with 2.8TB/s bidirectional bandwidth. Microsoft says the design supports a two-tier scale-up domain with up to 6,144 accelerators, targeting high-bandwidth, low-latency communication for large inference clusters.
Tile- and cluster-based microarchitecture
Maia’s compute design is organized hierarchically. The smallest unit is a tile that combines a Tile Tensor Unit (TTU) for matrix operations and convolutions with a Tile Vector Processor (TVP), positioned as a programmable SIMD engine. Each tile is fed by multi-banked tile SRAM (TSRAM) and uses a tile-level DMA engine to move data without stalling the compute pipeline. A lightweight control processor orchestrates work issuance, with hardware semaphores intended to provide tight synchronization between movement and compute.
Tiles group into clusters, which add shared locality via cluster SRAM (CSRAM) and introduce a second DMA tier to stage data between CSRAM and co-packaged HBM. Microsoft also notes redundancy for tiles and SRAM to improve yield and manufacturability while keeping the programming model consistent.
Narrow precision focus: FP4 and mixed precision
Microsoft is betting heavily on narrow precision as the lever for inference efficiency, citing industry results that FP4 can preserve inference accuracy while cutting compute and memory costs. Maia’s TTU is optimized for FP8, FP6, and FP4, and supports mixed-precision modes such as FP8 activations multiplied by FP4 weights. The TVP supports FP8 alongside BF16, FP16, and FP32 for operators that benefit from higher precision. An integrated reshaper up-converts low-precision formats at line rate to avoid introducing bottlenecks during compute.
Microsoft claims FP4 throughput on Maia is 2x that of FP8 and 8x that of BF16, positioning the architecture for higher tokens per second and stronger performance per watt in inference-heavy deployments.
Memory subsystem tuned for locality and determinism
Maia’s on-die SRAM is split across cluster-level and tile-level pools, and both tiers are fully software-managed. Microsoft is positioning this as deterministic control over placement and locality, either directly by developers or via compiler and runtime decisions.
The company describes several intended patterns: GEMM kernels can retain intermediate tiles in TSRAM to avoid round-trips to HBM; attention kernels can pin key tensors and partial products locally to reduce movement overhead; and collective communication can buffer payloads in CSRAM while accumulation proceeds in TSRAM to avoid HBM pressure during multi-node operations. Microsoft also highlights CSRAM as a transient buffer for cross-kernel pipelines, aiming to reduce stalls in dense operator chains and fused workloads.
Data movement: custom NoC plus multi-tier DMA
Microsoft’s view is that inference performance is frequently limited by data movement rather than peak math throughput, so Maia invests heavily in predictable transfers and low-latency control signaling. The on-chip interconnect is described as a mesh spanning clusters, tiles, memory controllers, and I/O units, with separate logical planes for high-bandwidth tensor traffic and latency-sensitive control traffic. That split is intended to prevent synchronization, interrupts, and small messages from being blocked behind bulk transfers.
Microsoft also cites hierarchical broadcast to reduce redundant HBM reads, localized cluster traffic to keep hot movement within the cluster, tile-to-tile SRAM access for intra-cluster sharing without pulling in HBM, and QoS mechanisms to prioritize urgent control and output traffic. DMA engines are tiered across tile, cluster, and network roles, enabling concurrent transfers across memory tiers and off-chip links while compute continues.
Scale-up networking: on-die NIC, Ethernet, and ATL
For multi-accelerator inference, Maia uses an integrated NIC and an Ethernet-based scale-up fabric built around Microsoft’s AI Transport Layer (ATL). Microsoft says ATL runs end-to-end over standard Ethernet and is intended to work with commodity, multi-vendor switching, while adding transport features such as packet spraying, multipath routing, and congestion-resistant flow control.
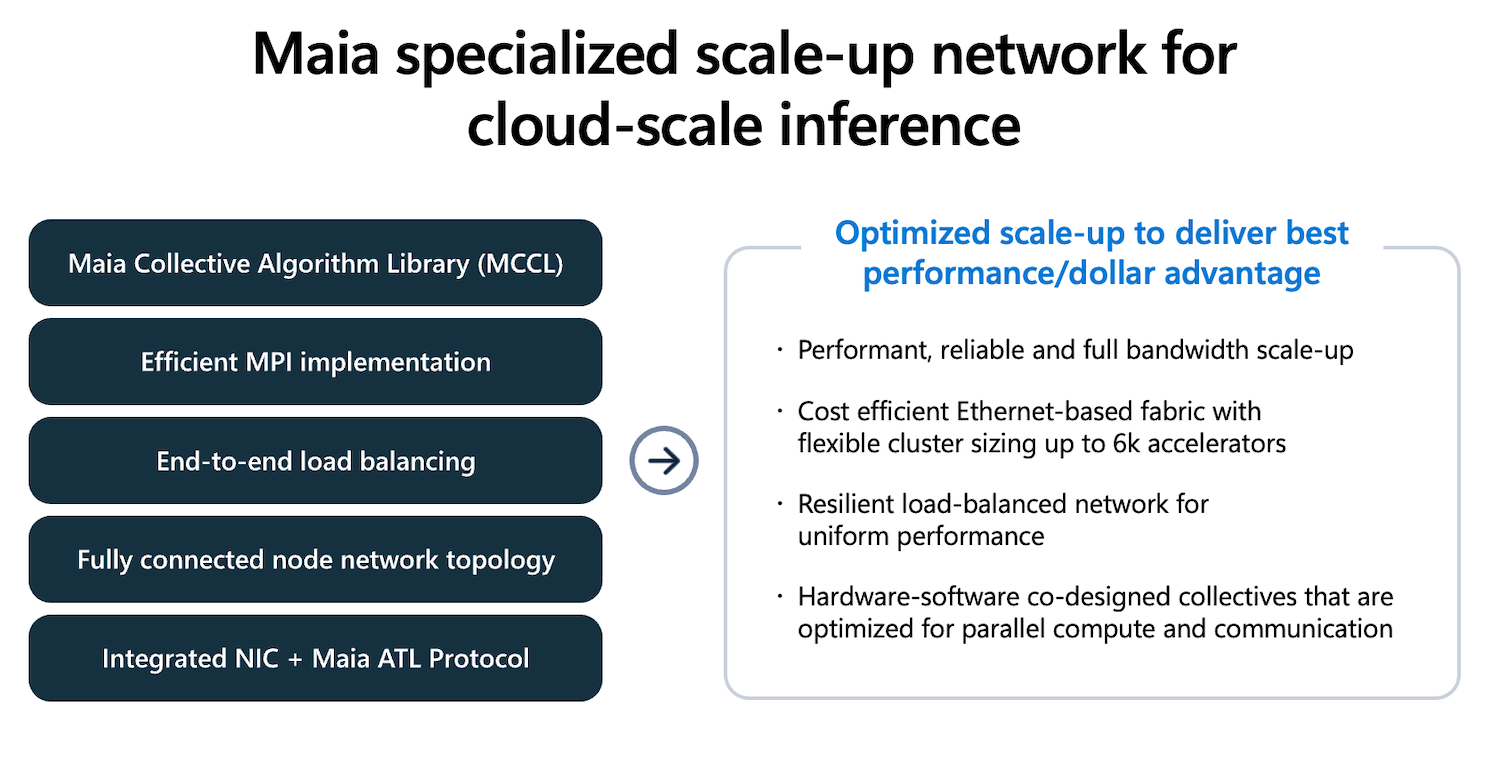
Microsoft also describes a topology choice meant to reduce reliance on external switches for local tensor-parallel traffic. The company’s Fully Connected Quad (FCQ) groups four accelerators with direct links, keeping high-intensity local collectives off the switched fabric. A second tier then scales beyond the FCQ domain to larger clusters, which Microsoft positions as “right-sized” for inference synchronization patterns compared to training-style all-to-all behavior.
On the software side of collective operations, Microsoft highlights the Microsoft Collective Communication Library (MCCL), co-designed with the hardware to improve scale-up efficiency. The company points to compute and I/O overlap, hierarchical collectives, dynamic algorithm selection, and pipelined scheduling to hide latency and reduce network pressure.
Azure integration and deployment model
Microsoft is pitching Maia as Azure-native rather than a stand-alone accelerator. It is designed to align with Azure’s rack, power, and mechanical standards used across third-party GPU systems, simplifying deployment and serviceability and enabling heterogeneous accelerator fleets in the same datacenter footprint.
Maia is also designed for both air- and liquid-cooled environments, including a second-generation liquid-cooling sidecar option aimed at high-density racks. Operationally, the platform integrates into Azure’s control plane for lifecycle management, health monitoring, firmware rollouts, and fleet workflows intended to reduce service impact during upgrades and maintenance.
Microsoft says Maia will be part of its heterogeneous AI infrastructure, supporting multiple models, including the latest GPT-5.2 models from OpenAI, and will be used to power AI workloads in Microsoft Foundry and Microsoft 365 Copilot. The company emphasizes that workloads can be scheduled, partitioned, and monitored using the same tooling as Azure’s GPU fleets, aiming for portability and the ability to optimize for performance per dollar, latency, or capacity without reworking orchestration.
Developer toolchain: Maia 200 SDK, Triton path, and low-level control
Microsoft describes a Maia 200 SDK that supports familiar entry points such as PyTorch while offering multiple levels of control. Options include a Maia Triton compiler path for kernel generation, tuned kernel libraries for the tile- and cluster-based architecture, and Microsoft’s Nested Parallel Language (NPL) for explicit management of data movement, SRAM placement, and parallel execution.
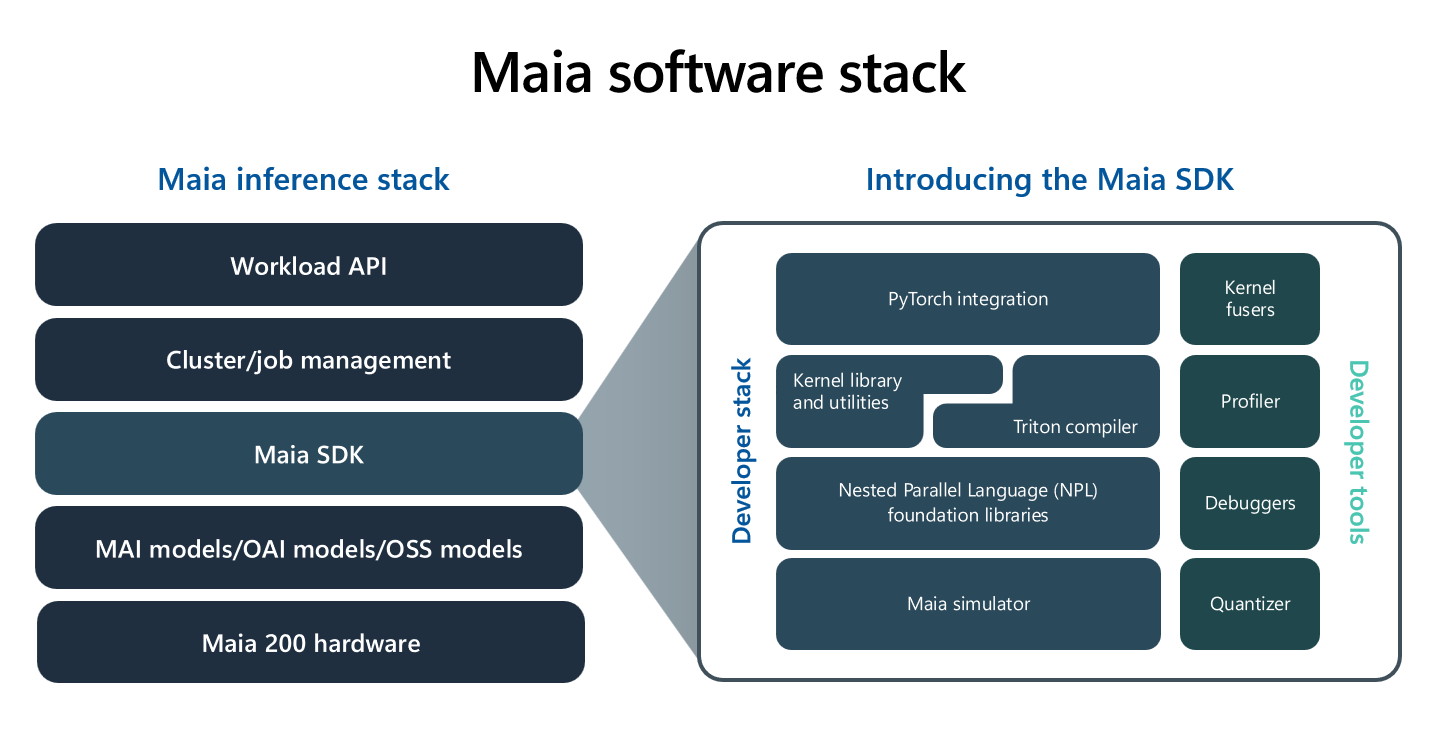
The SDK also includes a simulator, a compiler pipeline, a profiler, a debugger, and quantization and validation tooling. Microsoft positions this as a way to prototype and tune performance early, diagnose bottlenecks, and drive higher utilization across the stack.
Bottom line
Microsoft is positioning Maia 200 as a purpose-built inference platform focused on tokens per dollar and per watt, with an architectural emphasis on narrow-precision compute, software-managed SRAM locality, and an Ethernet-based scale-up fabric integrated directly on-die. The company’s headline claim is a 30% performance-per-dollar improvement versus current fleet hardware, delivered via coordinated optimization across silicon, networking, systems, and Azure operations.


 Amazon
Amazon