

Computex 2026 has kicked off in Taipei, and as usual, NVIDIA set the tone with a Jensen Huang keynote that ran the length of the company’s roadmap. A good chunk of it was the datacenter GPU goodness we had already seen, with Vera Rubin now in full production and the by-now-familiar messaging about agents reshaping every layer of computing. We will not rehash all of that here.
The genuinely new material, and the reason this keynote mattered for anyone who lives on the client side, was the PC. NVIDIA and Microsoft used Computex to announce a reinvention of the Windows machine, doing so across an entire product family rather than a single device. Before we get to that, though, one piece of the data center story is worth a closer look.
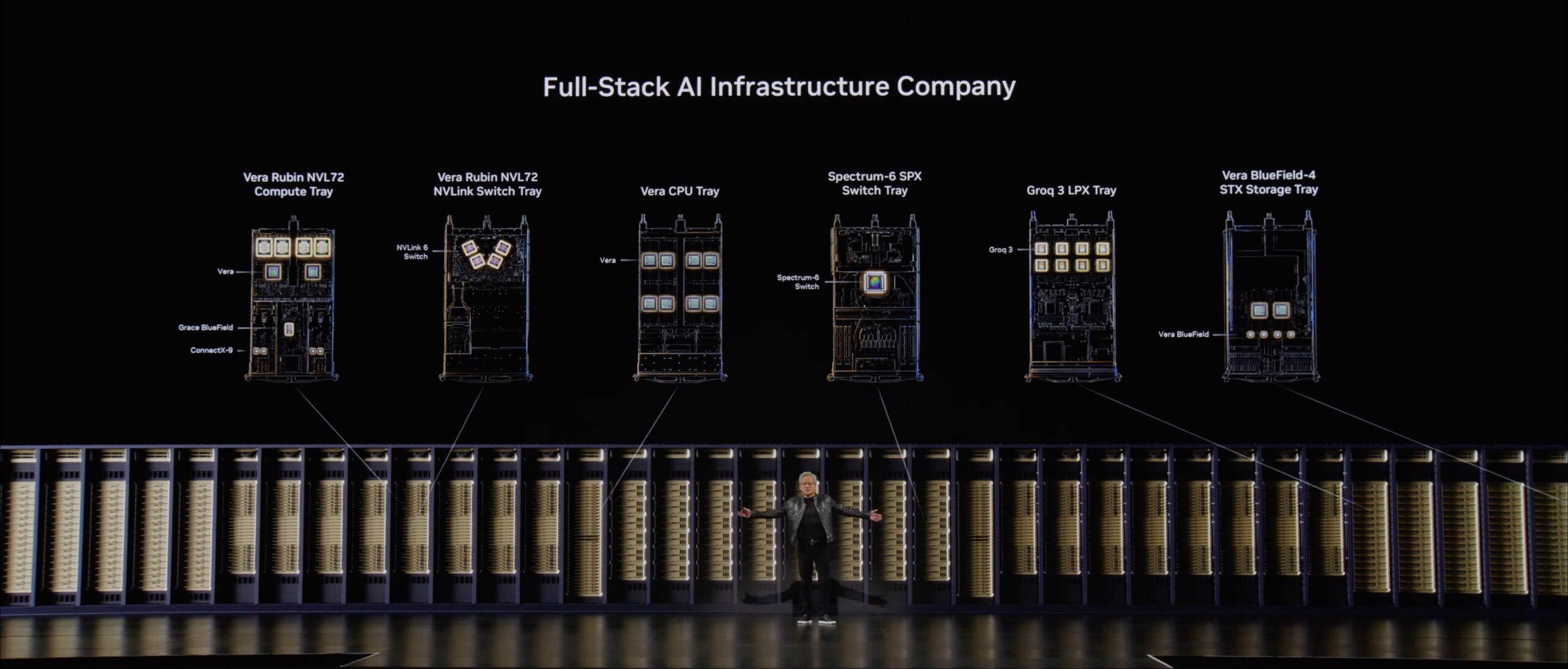
A Closer Look at the LPX Rack

One data center item did catch our eye. The LPX rack has changed. The systems appear to have moved from 1 OU to 2 OU, and the four Groq C2C links also look physically different from our earlier LPX coverage. NVIDIA gave us an even closer look at the rack this time. Beyond those two changes, nothing else stood out as obviously different on the outside, which leaves us very curious about what that second layer actually houses.
A Three-Tier PC Family

NVIDIA announced a family of client machines: a laptop, a desktop, and a workstation, all built on the same Spark and Blackwell foundation, and also aimed at supporting Windows. Jensen framed it as the first completely re-engineered line of PCs in 40 years. Whether or not you buy the framing, the structure is worth understanding, because each tier targets a very different buyer. We will take them in order.
The RTX Spark Laptops
At the center of the laptops is the RTX Spark superchip, which NVIDIA showed on stage under the codename N1X and built in partnership with MediaTek. It is a 70-billion-transistor part on a TSMC 3nm process that fuses two chiplets into one SoC. The GPU side is a large Blackwell design with 6,144 CUDA cores and fifth-generation Tensor Cores with FP4 precision, rated at 1 petaflop of FP4 AI performance. That connects over NVLink-C2C at 600GB/s (NVIDIA’s figure is roughly 5x PCIe Gen 5, with much lower power) to a 20-core Grace CPU. Memory tops out at 128GB of unified memory at 300GB/s of bandwidth.

If that reads like a DGX Spark spec sheet, that is because it nearly is. NVIDIA said as much during the press Q&A, calling the full-spec chip “based on the same system” as DGX Spark but optimized for a different platform in both hardware and software. The framing is that DGX Spark is built for Linux and AI developers, while RTX Spark is a Windows-first product that layers the RTX gaming and creation stack on top of the same silicon. NVIDIA describes performance as “in the same class as an RTX 5070 laptop GPU,” with the heavy caveat that the comparison varies by workload, since an SoC with unified memory behaves very differently from a discrete GPU over PCIe.This is where our DGX Spark experience makes us most curious, and where we expect this launch to differ from the last one. In our DGX Spark testing, one of the most consistent findings was how close the various OEM designs landed to one another. Some implementations were better engineered than others, but because every unit was built on essentially the same NVIDIA reference platform with the same power and thermal envelope, real-world performance clustered tightly.
We do not expect that to hold here. RTX Spark is going into laptops, some as slim as 14mm and as light as 3 pounds. NVIDIA confirmed these chips will run anywhere from single-digit watts up to roughly 80W at the top end for the largest configurations, with each OEM free to pick its own cooling approach, from vapor chambers to advanced heat pipes. In a chassis that thin, the chip is almost certainly going to be power-limited, which in turn makes it thermally and frequency-limited. That is not a knock. It is physics. But it means the OEM that builds the better thermal solution, gives the chip a higher sustained power budget, and tunes its fan curves well, could open a real, sustained performance gap over a thinner, quieter competitor running identical silicon. Two laptops with the same chip and the same memory could deliver noticeably different sustained throughput, and figuring out which OEM actually lets the chip stretch its legs is exactly the kind of testing we live for.RTX Spark also spans a whole family of chips. NVIDIA made it clear that there will be multiple SKUs, with the full-spec part (20 CPU cores, up to 128GB) at the top. Across the broader family, memory will range from 16GB to 128GB, and NVIDIA expects over 30 laptops and well over 10 desktops in the initial wave alone, from every major OEM, including named designs such as the Dell XPS 16 Creator Edition, HP OmniBook, and Microsoft’s Surface Laptop Ultra.
Two hardware details have us optimistic. The first is networking, or rather, the lack of it. DGX Spark shipped with NVIDIA’s ConnectX-7 networking and 200GbE connectivity baked in, which was great for a developer cluster box but consumed board space, power, and cost. NVIDIA confirmed RTX Spark laptops will not carry the CX7 package. For a consumer Windows laptop, that is the right call, and with that board space and power budget freed up, we want to see much better storage shipping in these units. DGX Spark’s storage was serviceable, but never the star of the show, and a consumer notebook with no networking silicon to feed has every reason to ship faster and larger NVMe. The second is I/O. Because every DGX Spark used the same reference board, every unit shipped with the same ports. After the uniformity of DGX Spark, real per-OEM I/O variety would be welcome.
Battery life is the last laptop question, and the one our benchmarks are built for. NVIDIA promised all-day battery for productivity and browsing, while being honest that gaming or full-tilt AI will drain any laptop in 45 minutes to an hour. What we cannot wait to quantify is battery life while doing actual AI work. An agent that runs even when the user is not is a nice pitch, but local inference on battery is a real draw, and the gap between all-day email and all-day running a 120B model could be enormous. We have a full suite of custom personal AI computing benchmarks ready for exactly this kind of platform, and we plan to measure the real productivity uplift rather than taking the marketing figures at face value.
The RTX Spark Desktop
NVIDIA confirmed small-form-factor RTX Spark desktops are coming this fall alongside the laptops, and showed one from MSI on stage. Honestly, at first glance, it looks like a DGX Spark, and that is about all we know about it. The industrial design appears different from that of the DGX Spark unit we reviewed, but beyond that, NVIDIA shared very little.

Our questions are the obvious ones, and they will have to wait until we get hardware on the bench. How does the desktop’s sustained performance compare to both the laptops and to DGX Spark, given that it should have far more thermal headroom than a 14mm notebook? And does the desktop keep the 200G networking that defined DGX Spark, or does it drop the CX7 package, like the laptops, to hit a cheaper consumer price point?
DGX Station
The third tier is the big one, and it is a machine we already know. NVIDIA has publicly shown the DGX Station before, and we recently had the privilege of getting hands-on with one. We are not going to go into much detail here, since the headline specs have been public for a while, and we will have much more to say in our review coming soon.

The short version: DGX Station for Windows is built on the GB300 Grace Blackwell Ultra Desktop Superchip, pairing a Blackwell Ultra GPU with a 72-core Grace CPU. It has up to 748GB of coherent memory and up to 20 petaflops of FP4, enough to run trillion-parameter models locally and, in NVIDIA’s words, hundreds of agents at once. Unlike the consumer Spark machines, this one includes fast networking with a ConnectX-8 SuperNIC capable of up to 800Gb/s, plus an optional RTX PRO 6000 Blackwell workstation GPU.
The big asterisk: can Microsoft pull this off?
Let us be clear about where we stand. DGX Spark was a major success for NVIDIA, and we are very optimistic about this whole family. The hardware song hits the right notes, the efficiency is there, and NVIDIA has already proven the silicon. We are skeptical about Microsoft’s ability to support these devices.
Microsoft has been in the headlines for the wrong reasons lately, with growing user dissatisfaction over the direction of Windows. Some users have taken to calling it “Microslop.” The complaints are familiar: the aggressive push of Copilot into every corner of the OS, the vertical integration of AI across the stack, and long-running practices like effectively forcing OneDrive on people. On top of that, Windows on Arm is not a platform anyone would call mature. NVIDIA is betting heavily that this time is different, citing years of joint work on the Prism emulator and work with all the major anti-cheat vendors. The company’s answer to “Why will Windows on Arm succeed now?” is basically, “because everyone is finally throwing their full weight behind it.” That may well be true. It is also more or less what we heard the last time.
I am personally rooting for Microsoft to deliver, because the upside is real. RTX Spark is a capable gaming machine, roughly RTX 5070-class. If the emulation and driver story holds together, it could end up being the cheaper and more efficient alternative to gaming on NVIDIA’s own discrete-GPU notebooks. There is also a Linux angle we cannot ignore. The silicon is the silicon, so RTX Spark should inherit the same strong Linux support that made DGX Spark such a capable little machine, and we are very curious whether the gaming and graphics work going into the Windows stack also shows up as gaming gains on Linux. If Microsoft fumbles a platform this good, that Linux pedigree means this might be the launch that finally kicks off the year of the Linux desktop for the masses.
The bigger surprise for us was NVIDIA’s choice to put Windows on the DGX Station at all. When the product was first announced in 2025, many of our friends at other publications and we thought it was a genius move. Software support has historically lagged new hardware, often by years, before the kernel and tooling mature enough to take real advantage of what the silicon can do. A DGX Station was the machine that top AI labs, researchers, and organizations could buy to start developing on the newest architecture, well before the datacenters were spun up around it. The problem is that the product is a year late to that party. And while we genuinely enjoyed our time with the system, pre-production quirks aside (a couple of those gave me night terrors), we cannot quite justify putting Windows on a machine this clearly built for hardcore AI. The B300 has no RT cores, so many of NVIDIA’s own workstation workloads would rely on the optional RTX PRO discrete card, leaving the B300 for AI tasks alone. We are very curious how Windows support on the DGX Station actually holds up, and frankly, skeptical that Microsoft can deliver a good experience here and make real use of the B300 and the 800G ConnectX-8 networking on a single host.
A New Product Family, Every Generation
The detail from the keynote that stuck with us most was not a spec.
Jensen presented this PC lineup as a permanent product family, promising a desktop, laptop, and workstation for every future architecture generation, with what he claims is 100% of the PC industry on board.
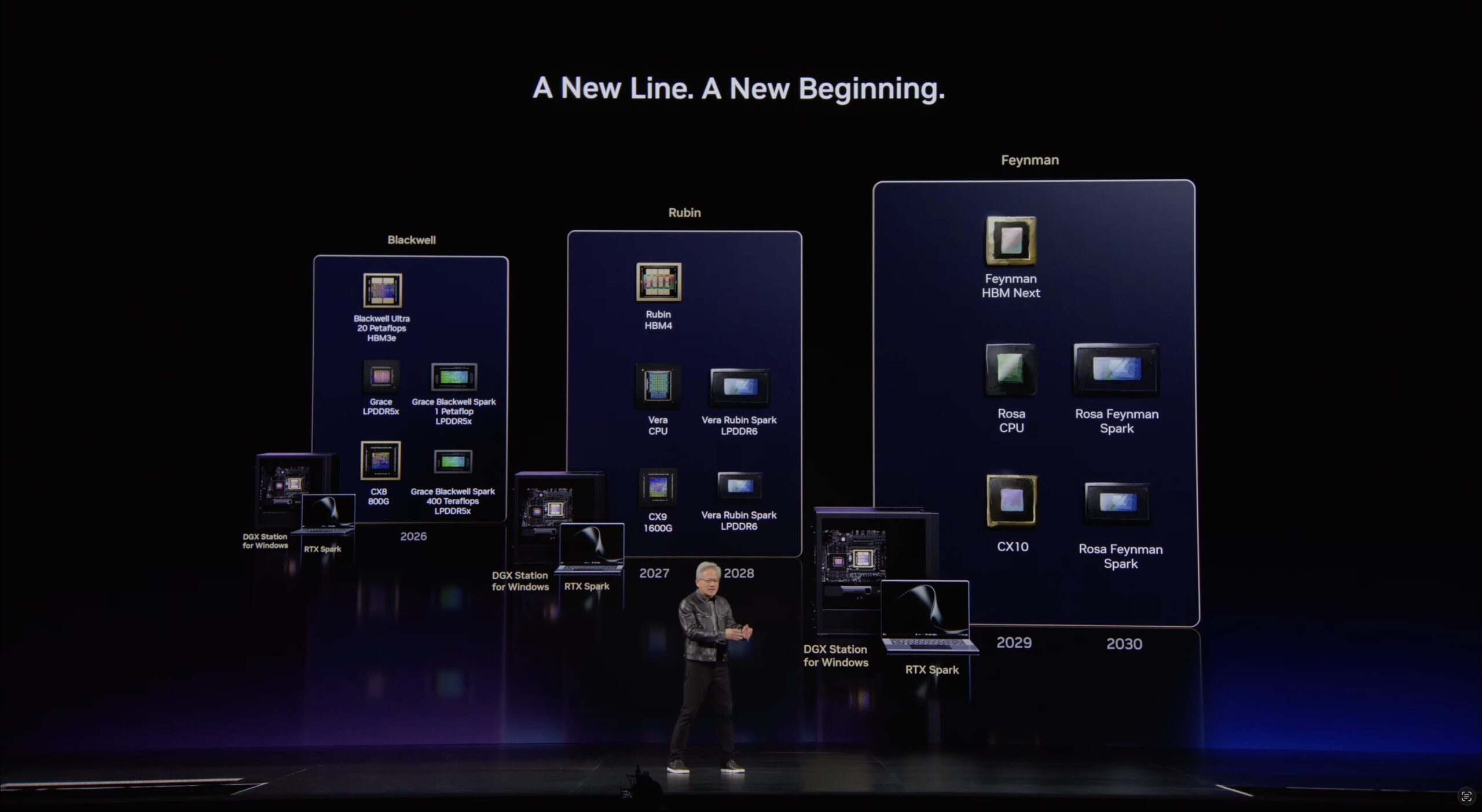
Just as a side note, we did finally see the smaller size 400 TFlop N1 Grace Blackwell Spark Superchip mentioned here. It will be interesting to see what type of devices end up featuring this chip.
Beyond the PC: Physical AI
The back half of the keynote pivoted hard into physical AI. It is a different world from the client hardware above, but it rounds out the Computex picture. NVIDIA also used the show to open-source a large collection of physical AI agent tools and skills, posted at github.com/NVIDIA/skills, including synthetic-data skills like Neural Reconstruction, Video Augmentation, and Defect Image Generation that manufacturing partners, including TSMC, Foxconn, and SK hynix, are already running on factory lines. The headline platforms are below.
Isaac GR00T Reference Humanoid Robot

NVIDIA released an open reference design for a humanoid robot, built on a Unitree H2 Plus chassis that is nearly six feet tall and weighs 150 pounds, with 75 degrees of freedom in total, thanks to dual Sharpa Wave tactile five-finger hands. The actuators are serious, with up to 120 Newton-meters of arm torque, up to 360 at the legs, and a rated 7kg payload that peaks at 15kg. For sensing, it carries a head-mounted stereo camera with a 140-degree horizontal field of view, wrist cameras for manipulation, an inertial measurement unit, and the usual Wi-Fi 6 and Bluetooth 5.2 connectivity. The brain is NVIDIA’s Jetson AGX Thor T5000, with a Blackwell GPU rated at 2,070 FP4 teraflops, a 14-core Arm CPU, and 128GB of unified memory, drawing a configurable 40 to 130 watts and running on a roughly 1kWh battery good for about three hours. The whole stack, from Isaac Teleop for data capture through Isaac Sim and Isaac Lab to the GR00T foundation models and Isaac ROS middleware for deployment, is open, and researchers keep control of their own data. Stanford, ETH Zurich, UC San Diego, and Ai2 are among the early adopters, with hardware available from Unitree in late 2026 and a Unitree G1 reference workflow due on GitHub and Hugging Face soon. Jensen pitched the stakes in characteristically large terms, calling humanoid robots a “multitrillion-dollar economic opportunity.”
Cosmos 3
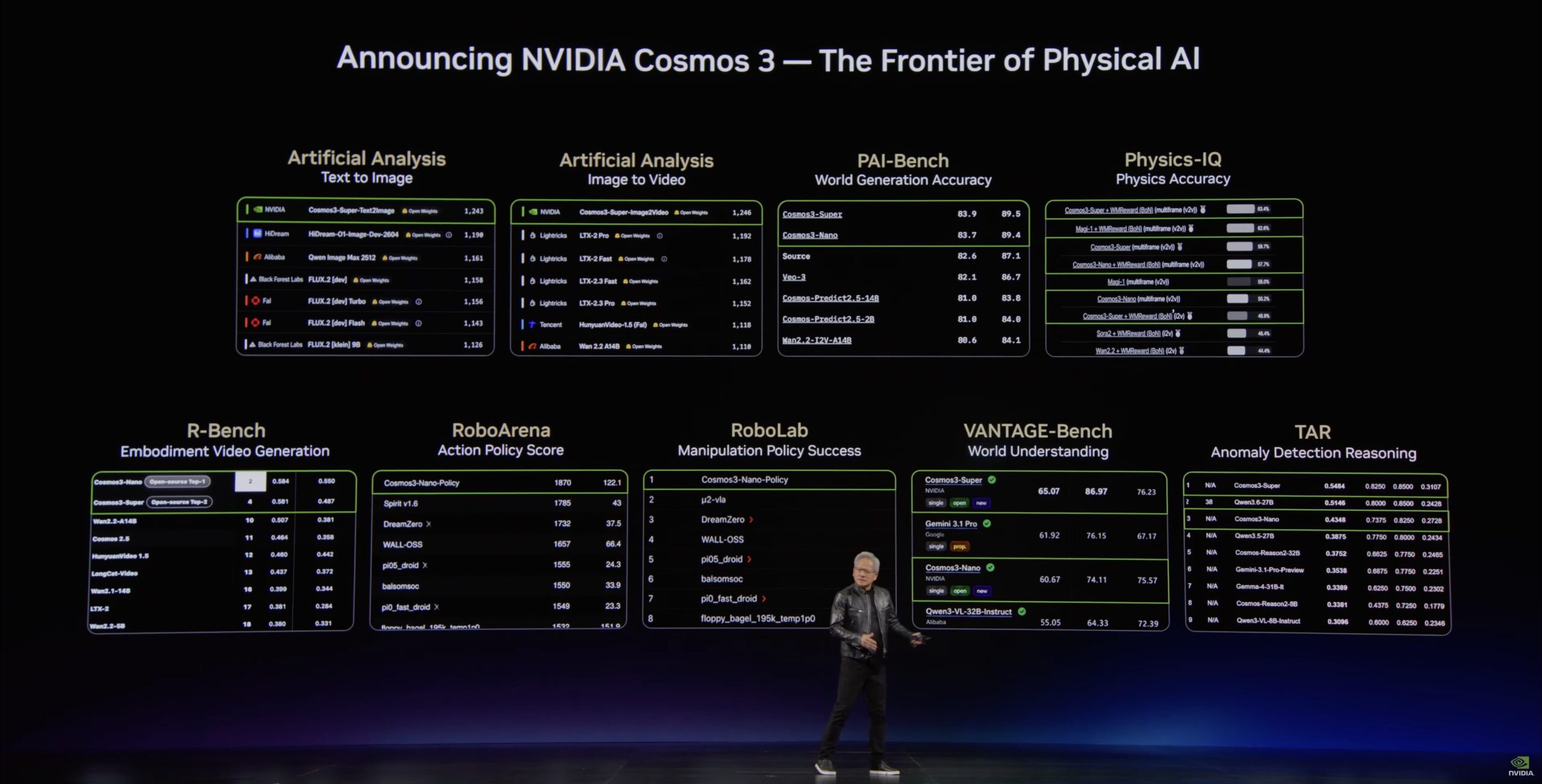
Cosmos 3 is NVIDIA’s open frontier foundation model for physical AI. This mixture-of-transformers omnimodel handles text, images, video, ambient sound, and actions in one stack, trained on billions of multimodal samples. It plays three roles: a vision-language model for multimodal reasoning, a world model for simulating physical environments, and a backbone for the world-action models that train robots on specific tasks. It comes as Cosmos 3 Super for high-accuracy robotics and AV post-training, Cosmos 3 Nano for fast video and action reasoning, and Cosmos 3 Edge for real-time inference coming soon. NVIDIA says it leads the open-model field on a long list of benchmarks, including Physics-IQ and R-Bench for world generation, RoboLab and RoboArena for action policy, and VANTAGE-Bench for vision understanding, and that it can cut physical AI training and evaluation cycles from months to days. It is available on Hugging Face, GitHub, and build.nvidia.com as NIM microservices, with a coalition around it that includes Agile Robots, Black Forest Labs, Runway, and Skild AI, and adopters such as Samsung, LG Electronics, Li Auto, and Doosan Robotics.
Alpamayo 2 Super
For autonomous driving, NVIDIA introduced Alpamayo 2 Super. It’s an open 32-billion-parameter reasoning vision-language-action model built on the Cosmos world foundation models, that reasons, plans, and acts across the full driving stack for Level 4 development. It scales up from the prior 10-billion-parameter versions and expands to full 360-degree surround perception. It also produces both macro driving decisions and chain-of-causation traces that explain them, and its reasoning auto-labeling can compress annotation cycles from months to days. NVIDIA positions it as a teacher model that distills into smaller networks for in-vehicle deployment on DRIVE AGX Thor, and pairs it with supporting tools in AlpaGym for closed-loop reinforcement learning, OmniDreams for generative scenario creation, and Neural Reconstruction built on Omniverse NuRec for turning fleet data into 3D scenes. Earlier versions of Alpamayo were downloaded close to 400,000 times. The new model won a COMPUTEX Best Choice award and is expected to be available on GitHub and Hugging Face this summer.
DRIVE Hyperion
If Alpamayo is the brain, DRIVE Hyperion is the car it runs in. We covered Hyperion previously, so we will not relitigate the platform here, other than to note that it is NVIDIA’s Level-4-ready reference built on the Halos safety system and DriveOS, with DRIVE AGX compute. The more interesting story this time is who is lining up behind it. Uber is integrating several Hyperion-powered fleets, including a Munich robotaxi program launching later this year. Foxconn and Foxtron are targeting a 2028 robotaxi launch in Taiwan, starting in Kaohsiung and expanding across Asia. VinFast is bringing Level 4 vehicles to Southeast Asia, Autobrains is working with both VinFast and Uber, and HUMAIN is taking it to Saudi Arabia. That partner roster, more than any single spec, is what makes Hyperion worth watching.
Closing Thoughts
NVIDIA has the silicon and is now pushing it everywhere, from a 14mm laptop to a deskside GB300 to a humanoid’s chest, and that part we believe. What a spec sheet cannot tell us is whether Microsoft can make Windows on Arm worth the hardware cost, whether OEMs let the Spark chip stretch its legs or choke it in a too-thin chassis, and whether the petaflop and battery claims hold up once we can measure them. We are optimistic about the hardware and skeptical of the software (Microsoft, not Linux), and we will hold both positions until the machines reach the lab. When they do, the benchmarks will be ready.


 Amazon
Amazon