

Qumulo announced the Cloud AI Accelerator, a new architecture designed to improve the efficiency of enterprise AI infrastructure by eliminating data movement bottlenecks. The platform presents distributed datasets to GPU resources in real time across regions, clouds, and hybrid environments without requiring replication or staging.
The release builds on a well-documented inefficiency in enterprise AI infrastructure. Citing Cast AI’s 2026 State of Kubernetes Optimization Report, Qumulo points to average enterprise GPU utilization of around 5 percent, with the remaining 95 percent of accelerated compute sitting idle because data must be staged, replicated, and moved into position before workloads can begin. Qumulo CEO Doug Gourlay framed the problem in the announcement: “Every enterprise we talk to is focused on GPU availability, but availability is only half the problem. The deeper issue is utilization, and the culprit is data gravity.”
Rethinking Data Placement for AI Workloads
Traditional approaches to AI infrastructure co-locate storage with GPU clusters, often using high-performance flash systems tightly coupled to compute. While effective during active training or inference, this model does not handle idle periods due to data preparation. It also creates fragmented storage silos as enterprises replicate datasets across environments to keep them close to compute.
Qumulo’s approach shifts the model by decoupling data location from compute location. Instead of moving data to GPUs, the Cloud AI Accelerator enables GPUs to access data in place. This is achieved through a distributed data fabric that provides consistent, real-time access to datasets, regardless of their physical location.
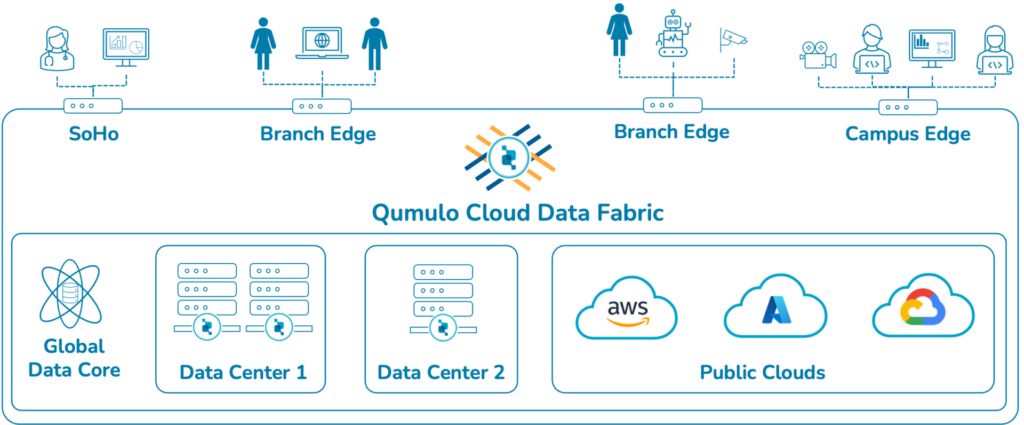
The company frames this capability as enabling “GPU liquidity,” allowing workloads to be scheduled based on available compute capacity rather than data locality constraints. In practice, this enables enterprises to use GPU resources across multiple clouds or regions without pre-positioning data.
Architecture: Data Fabric and Caching Layer
Cloud AI Accelerator is an integration of three Qumulo products that previously shipped separately. Cloud Native Qumulo (CNQ) is Qumulo’s file system that runs natively on AWS, Azure, Google Cloud, and Oracle Cloud Infrastructure. Cloud Data Fabric (CDF), launched in February 2025, provides a central file and object repository with coherent caches at the edge. NeuralCache, added to CDF in April 2025, applies machine learning to predictive read and write caching, and Qumulo claims it reduces GPU data load times by up to 64 percent. Cloud AI Accelerator itself first appeared in November 2025; the May 26 release adds direct connectivity to Microsoft AI Foundry, AWS Bedrock, and Google Vertex AI, formalizes the “GPU liquidity” positioning, and pairs the product with Cisco for hybrid deployments.
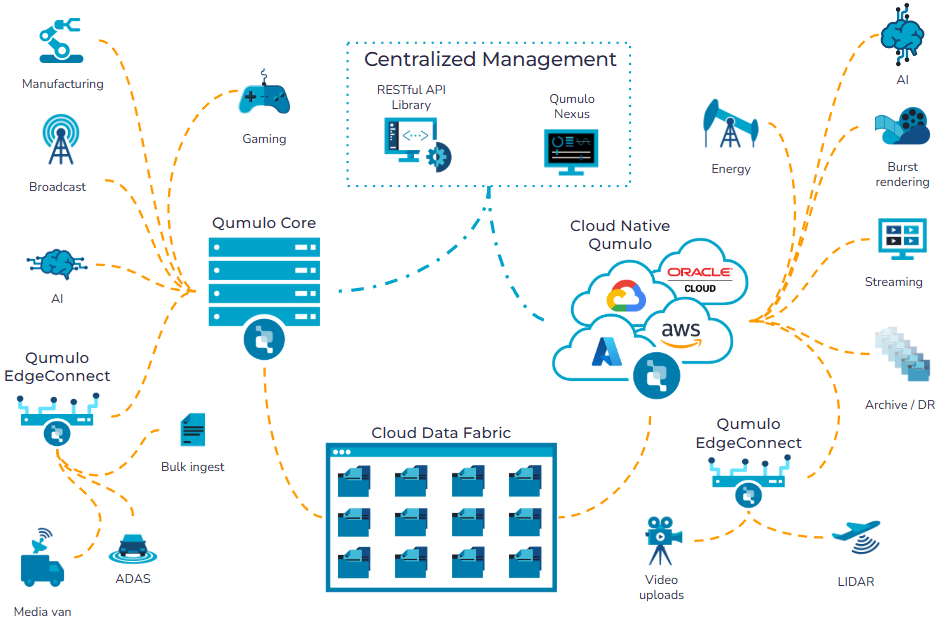
The data path runs at the block level from source sites (on-premises clusters, cloud regions, cross-region replicas, or CNQ S3-backed storage) into the Accelerator’s CPU DRAM cache, then directly to the GPUs. The architecture maintains a single source of truth across on-premises, edge, and multi-cloud environments and avoids bulk replication, which reduces both storage overhead and synchronization complexity.
This design also supports integration with managed AI services. Enterprises can connect existing datasets directly to platforms such as Microsoft AI Foundry, AWS Bedrock, and Google Vertex AI without copying data into those environments.
Operational Impact: Reducing Idle Time and Complexity
The primary operational benefit is the elimination of data staging delays. In many AI workflows, data preparation can take days or weeks, delaying model training and reducing effective GPU utilization. By enabling immediate access to datasets, the Cloud AI Accelerator allows workloads to start as soon as compute is available.
This also reduces the need to maintain multiple storage environments. Instead of creating separate data silos for each GPU cluster or cloud region, organizations can operate from a single logical dataset. This simplifies data management and reduces infrastructure sprawl.
From a cost perspective, the model targets idle GPU spend. By eliminating the need to preload data into GPU-attached storage, enterprises can reduce the time GPUs spend waiting for data, improving the overall return on investment for accelerated compute.
Cisco Integration for Hybrid AI Infrastructure
Cisco is the joint go-to-market partner for the hybrid deployment story, with Cisco UCS providing the on-premises compute footprint and Cisco networking and security wrapping the data fabric. Together, Qumulo and Cisco position the offering as infrastructure that adapts in minutes to changing GPU availability, which they argue is what makes GPU liquidity practical at enterprise scale.
The pairing is critical in both directions. It gives Qumulo a validated path into Cisco UCS environments and provides Cisco with a storage answer for hybrid AI customers who want data to stay on-premises while compute scales across hyperscalers. High-throughput, low-latency networking is the load-bearing element here, since data access in place depends on consistent transport between sites.
Availability and Deployment Model
Qumulo Cloud AI Accelerator is now available on AWS, Microsoft Azure, Google Cloud, and Oracle Cloud Infrastructure, with hybrid deployment support in Cisco UCS environments. Qumulo and Cisco will be at Cisco Live 2026 in Las Vegas, at booth #4018, from May 31 through June 4, where the joint offering will be on display.
The release reflects a broader shift in AI infrastructure design toward data-centric architectures. As accelerated compute capacity continues to outpace the infrastructure that feeds it, improving utilization will depend on reducing the time GPUs spend waiting for data. Qumulo’s bet is that making the dataset universally accessible, rather than mobile, is the more durable approach than adding more flash to every GPU cluster.


 Amazon
Amazon