

Earlier this year, we set a new record by computing 314 trillion digits of Pi. The calculation ran for months on a single Dell PowerEdge R7725, pushing modern CPU and storage infrastructure to the limit while demonstrating just how far enterprise hardware has come. When the run finally finished, however, the record itself turned out to be only part of the story. The computation produced a massive dataset comprising 628 files, each roughly 206 GB, totaling over 130 TB. Those files represent the full artifact of the calculation, and are often the most interesting part of a project like this. Mathematicians, developers, and data scientists often want to explore datasets like this further, whether to validate portions of the computation, experiment with new analytical methods, or work with unusually large numerical datasets.

That creates a practical problem that extends far beyond computing Pi. Modern computational workloads increasingly generate enormous output datasets that must remain accessible long after the compute job completes. Scientific simulations, genomic analysis, and large-scale AI training runs all produce results that can span tens or hundreds of terabytes. While a lab environment may be perfectly suited to generate that data, it is rarely the best place to host it indefinitely for a global audience.
For our Pi project, keeping more than 130 TB of results permanently mounted in the StorageReview lab wasn’t the right answer. Researchers had already begun requesting access, and making the dataset broadly available required infrastructure capable of reliably storing and efficiently distributing it.
That’s where Backblaze stepped in. The company is hosting the entire Pi dataset in Backblaze B2 Cloud Storage, making the results accessible to researchers and enthusiasts who want to work with them. Providing durable storage and global access for a dataset of this size is a meaningful commitment, and we appreciate Backblaze’s help in ensuring that the results of this record-setting computation remain available to the broader community.
The collaboration also illustrates a trend we increasingly see in modern infrastructure: the practical benefits of hybrid workflows that combine on-premises compute with cloud-based storage and distribution. The Pi calculation itself ran entirely in our lab on a single system, but once the work was complete, the cloud became the logical place to host and share the results.
Before that could happen, though, the data had to travel from our lab to Backblaze. Moving more than 130 TB of results is no small task, but with a healthy network pipe, the transfer was completed in under two weeks, maintaining a steady 2 Gbps throughput for much of the process. Large datasets still have gravity, and when you’re moving hundreds of gigabytes at a time, bandwidth quickly becomes the limiting factor.
Now that the dataset is safely stored in Backblaze B2, the results of the 314 trillion-digit computation can live beyond the confines of our lab. Researchers can download the files, experiment with them, verify sections of the computation, or explore the digits for their own projects. With Pi Day 2026 upon us, this is the perfect moment to make the dataset available.
Backblaze B2: Enterprise Cloud Storage for Large-Scale Data
Making the Pi dataset broadly available required infrastructure capable of reliably storing and distributing very large volumes of data. Backblaze B2 Cloud Storage is an enterprise object storage platform designed for exactly that type of workload. Object storage allows massive collections of files to be stored in scalable object buckets rather than forcing them into traditional file hierarchies, making it well-suited for large datasets, backups, and modern data pipelines. B2 also supports S3-compatible APIs, allowing organizations to interact with the service using familiar tools and workflows without redesigning existing applications or data processes.
Backblaze has focused its platform on delivering durable storage with straightforward economics and operational simplicity. The architecture is designed for 11 nines of data durability, distributing data across storage pods to ensure long-term reliability at scale. The company has also built a reputation for transparency, publishing detailed drive reliability reports and maintaining predictable pricing that many infrastructure teams appreciate. In our case, B2 provides a practical solution for hosting a very large dataset generated in our lab, ensuring the results remain accessible to anyone interested in exploring the data while demonstrating how cloud storage can extend the reach of on-premises compute environments. In addition to standard Backblaze B2 Cloud Storage, B2 Overdrive supports up to 1 Tbps throughput.
Hosting the Dataset in Backblaze B2
With the 314 trillion-digit PI computation complete and the data offloaded from the R7725 to NAS storage, the question of how to make the dataset publicly available required some thought. Serving 130 TB directly from the lab was not a practical option. Our WAN connection operates at a maximum of 2 Gbps up and 2 Gbps down and is shared across all lab operations. Sustained public downloads at any meaningful scale would have created contention with day-to-day work, and the bandwidth ceiling alone would have made large concurrent downloads slow and unreliable for anyone trying to access the data.
The initial idea was to distribute the dataset over BitTorrent. While that would have worked technically, it is not the most accessible experience for most users. Downloading a 130 TB dataset via torrent requires a client, some familiarity with how torrenting works, and patience with a process that is not as straightforward as a direct download. For a dataset intended to be broadly accessible to researchers and the wider community, that friction was worth avoiding.
Backblaze B2 solved both problems cleanly. The dataset is hosted entirely in cloud infrastructure, so public downloads have no dependency on the lab WAN and place no load on lab operations. Connections to B2 are served over HTTPS directly from Backblaze infrastructure, meaning downloads are secure, consistent, and not subject to the availability of any third-party seeders. The full dataset now lives in the pi-314-trillion bucket as 628 objects totaling about 132 TB, organized under a single data path and accessible to anyone, with no impact on the lab.
The transfer from the lab NAS was handled with a simple Rclone configuration, routed through our UDM Pro Max, which serves as the lab gateway, at a sustained rate of just over 2 Gbps throughout the upload. At that throughput, moving 130 TB required approximately 10 days of continuous transfer. The charts below show what that looked like from both per-minute and cumulative perspectives.
WAN Utilization During Transfer
The UniFi network dashboard for the lab confirms the upload characteristics across the transfer window. The WAN interface shows Backblaze as the dominant application by traffic volume, with upload throughput at 2.27 Gbps and monthly WAN data usage logged at 90.9 TB for the period. The connection remained stable throughout with no significant packet loss events during the transfer.
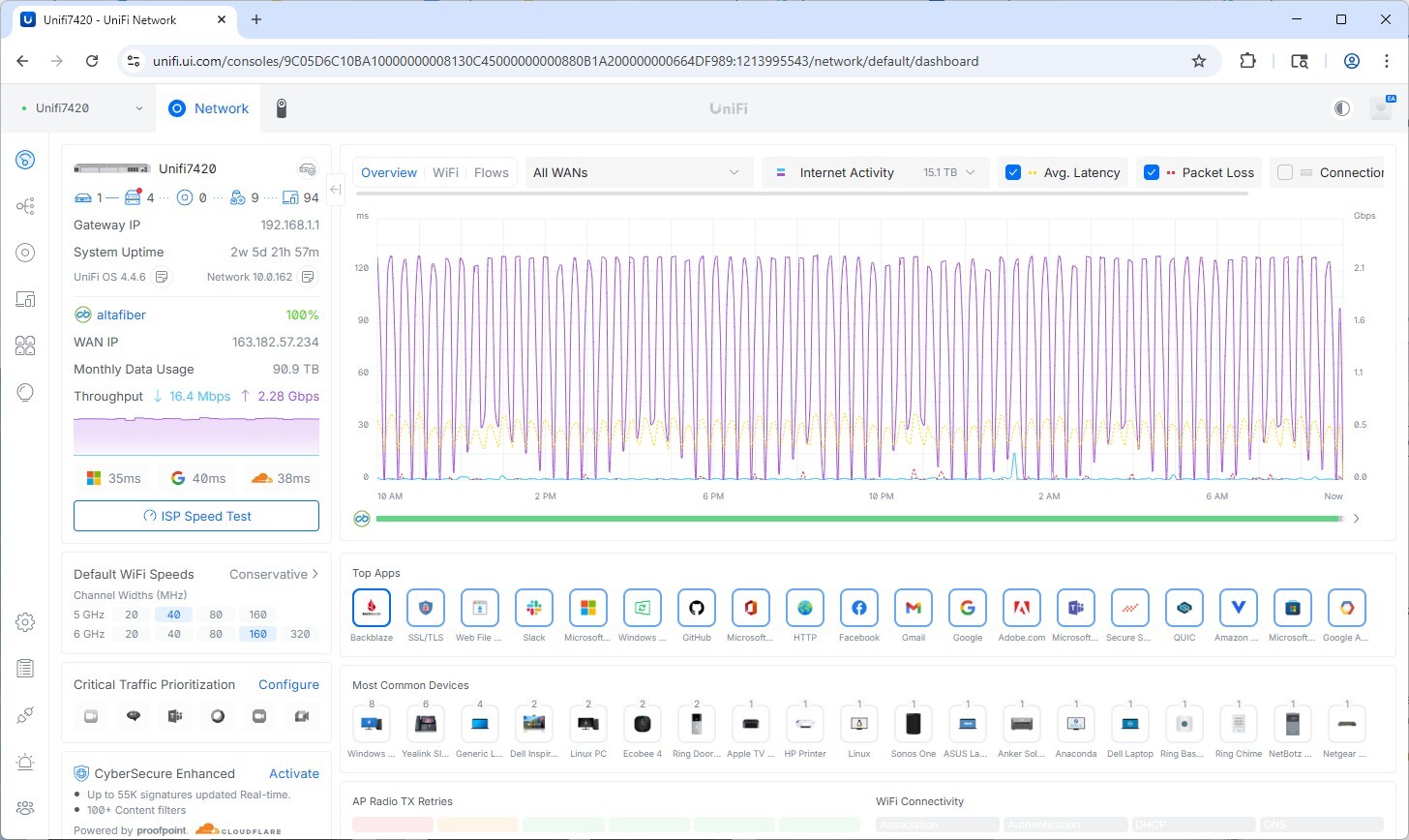
The UniFi dashboard shows sustained 2+ Gbps upload throughput with Backblaze as the top WAN application during the transfer period.
Per-Minute Transfer Throughput
The chart below shows transfer throughput sampled per minute across a representative window of the upload. Bars consistently reach between 15 and 16 gigabytes per minute, which aligns with a sustained ~2 Gbps line rate. The brief gaps visible in the chart correspond to checksum validation pauses run periodically throughout the transfer to confirm data integrity before continuing.
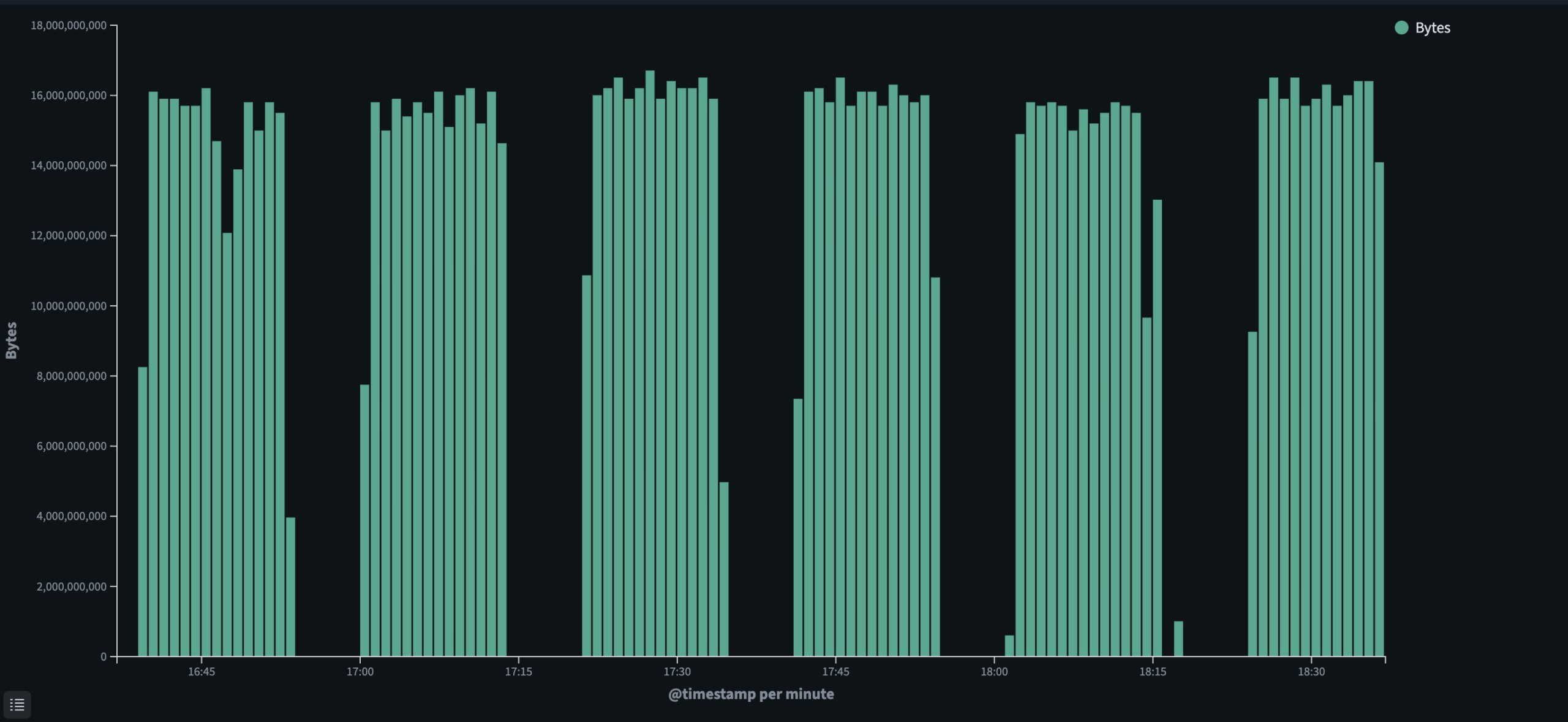
Per-minute byte transfer rate during upload, showing consistent throughput between 15 and 16 GB per minute across the active transfer window.
Cumulative Transfer Progress
The cumulative bytes chart tracks the total data transferred from February 4 through February 10, showing a consistent linear climb from 0 to approximately 100 TB over that period. The steady slope across the full period reflects the stability of the transfer with no major interruptions or rate drops.
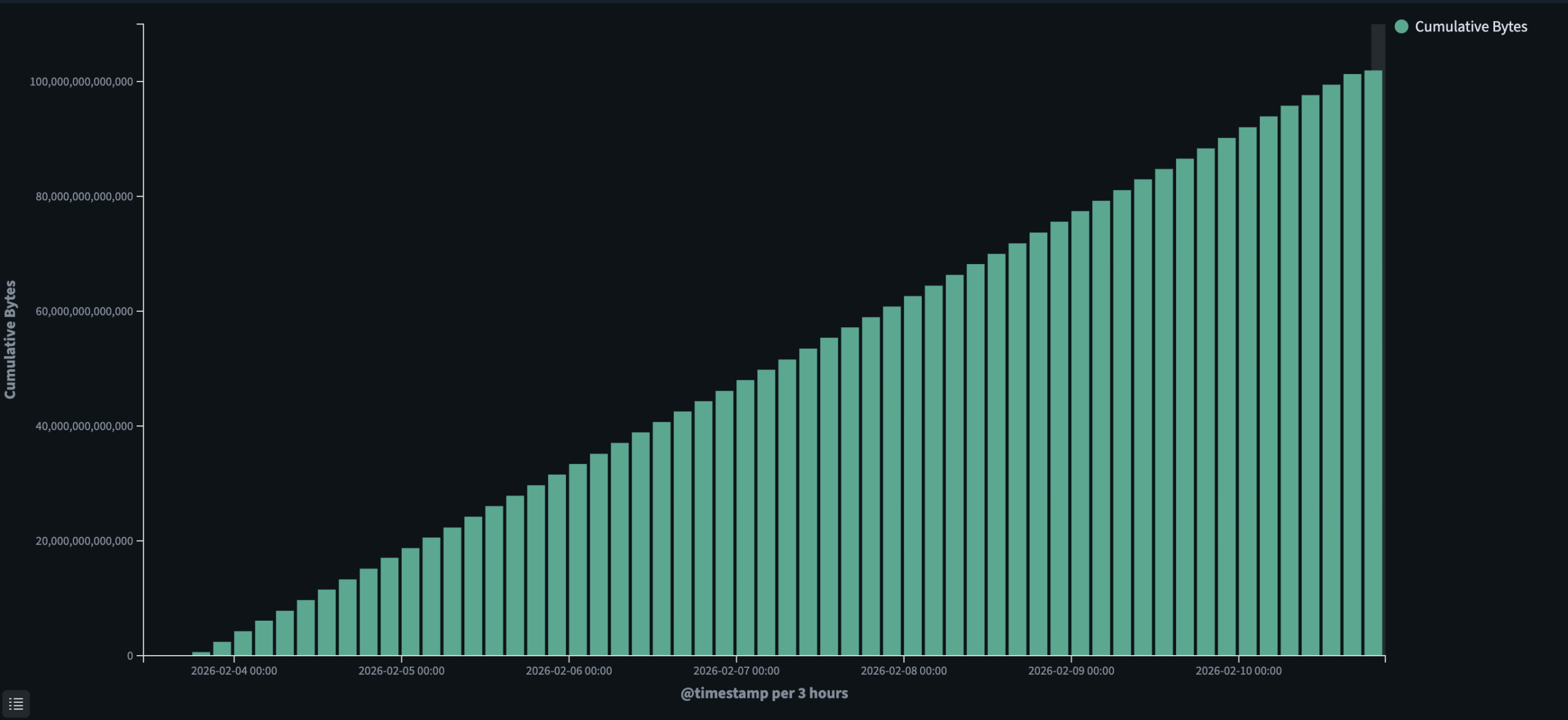
Final Bucket Layout
Backblaze created the pi-314-trillion bucket, which contains all 628 files and has a confirmed size of 132,210.5 GB. The bucket is configured as private with all file versions retained, and is accessible via the S3-compatible endpoint at s3.us-west-004.backblazeb2.com. Object storage makes managing a dataset of this scale straightforward. Every file is individually addressable, the full listing can be retrieved programmatically, and there are no file system hierarchies or volume limits to work around.
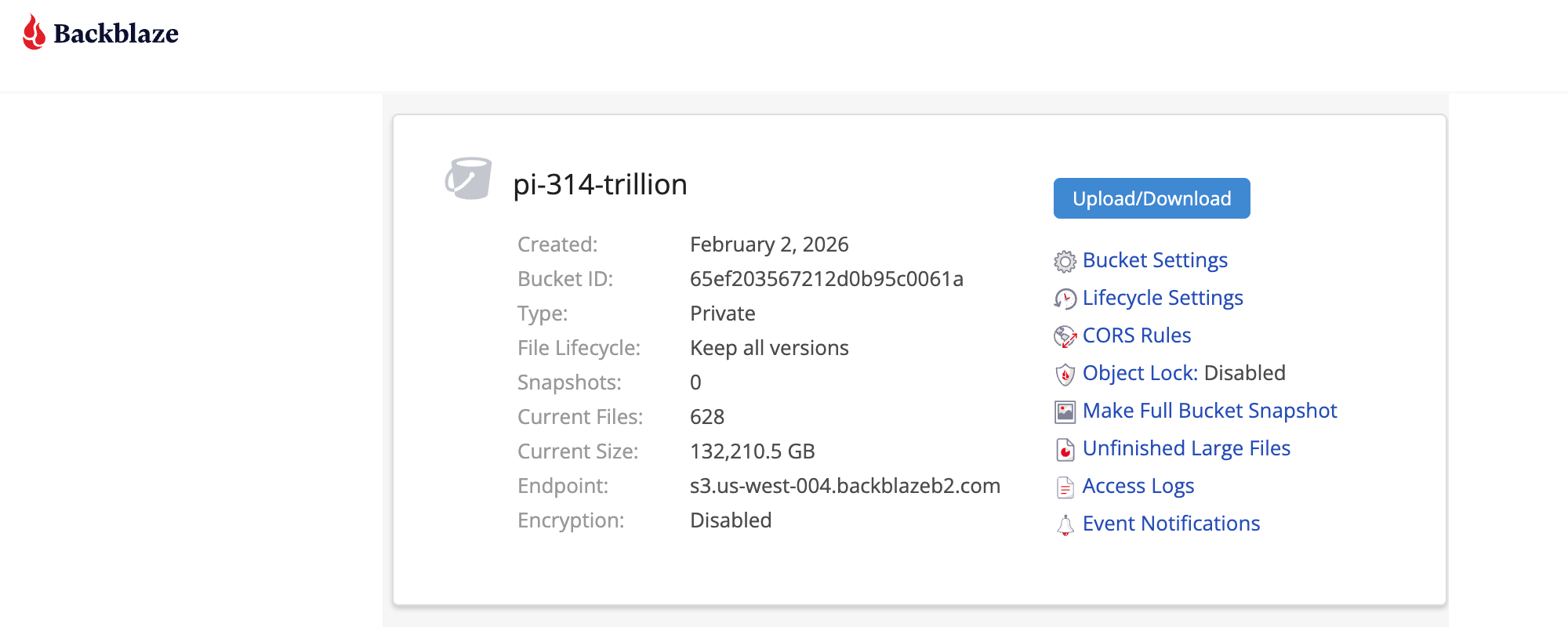
Backblaze B2 console showing the pi-314-trillion bucket confirming 628 files, 132,210.5 GB total size, and the S3-compatible endpoint.
Accessing the Dataset
Researchers have been asking us for access to this data; in fact, we already have a project in flight. Michael Kleber is a Principal Software Engineer at Google, but he has been playing with the digits of pi since he was a freshly-minted math Ph.D. in 1999. Mathematicians expect that pi is a normal number, so it’s reasonable to ask, “Out of the 10^d sequences of d digits, which one takes the longest to first appear in pi, and how many digits does it take?” Kleber ran the search up through d=7, and when Fabrice Bellard computed 2.7 trillion digits of pi in 2009, Kleber encouraged him to extend to d=11, the limit of what was possible at the time. “With 314 trillion random digits, there is around a 79% chance of seeing all strings of length 13″, Kleber says, “so I hope we get lucky!” We expect much more of this now that Backblaze has made the data available to all.
The PI dataset is hosted on Backblaze B2 and available for download by anyone interested in working with the data. Access is provided via a request link, through which users can obtain credentials or download instructions to retrieve files from the bucket. Backblaze will host the dataset to ensure the data remains available for research and verification throughout that window.
Download Options
Users can retrieve either individual files from the dataset or the full 130 TB collection, depending on their needs. The bucket is structured so that individual objects can be addressed and downloaded directly without pulling the entire dataset. For those who want to retrieve everything, a full sync of the bucket can be performed using the tools outlined below. For this option, 135 TB of free space is recommended.
Recommended Tools
- Rclone is the recommended tool for accessing the dataset. It integrates seamlessly with Backblaze B2 and allows users to tune the download process to match their available bandwidth needs.
- S3-compatible API, so any download tool with S3 capability can be used to retrieve the data. The one requirement is that the tool must allow overriding the default S3 endpoint URL to point at the B2 endpoint rather than AWS.
A Real Example of Hybrid Infrastructure
Our 314-trillion-digit Pi computation is a clear example of what hybrid infrastructure looks like in practice. The calculation ran entirely on a single Dell PowerEdge R7725 in the StorageReview lab, but with the system needing to be reallocated to other projects and tasks once the run completed, keeping 130 TB of results permanently hosted in the lab was never a sustainable option.
The desire to get the data out to those who want to use it, whether for serious scientific work or to satisfy curiosity about the digits, is real. But hosting a dataset of that size within the lab quickly becomes a burden on operations. Bandwidth gets consumed, infrastructure stays tied up, and the lab’s day-to-day work competes with every incoming download request.
A solution like Backblaze B2 removes all of that friction. The data lives in a cloud infrastructure purpose-built for datasets of this scale, with throughput that scales with demand, multiple points of redundancy to ensure nothing gets lost, and the security and operational expertise that comes with an enterprise storage platform. The compute was on-premises because the job required it. The storage is in the cloud because that is simply the better tool for everything that comes after.


 Amazon
Amazon