

Intel’s Project Battlematrix represents a compelling offering to accessible AI infrastructure, bringing substantial GPU memory capacity to workstation chassis through a multi-GPU design. Built around the code-named Battlemage Arc Pro B60 professional GPU, this platform targets organizations seeking to deploy large language models locally without cloud subscription costs or data privacy concerns. With up to 192GB of VRAM across eight GPUs in a single system, Battlematrix positions itself as a relatively cost-effective alternative to other professional GPU ecosystems for AI inference workloads.
View this post on Instagram
What distinguishes Battlematrix from traditional workstation configurations is Intel’s dual-GPU card design, which places two full B60 GPUs on a single PCB requiring PCIe bifurcation support. This density-optimized approach enables configurations that would otherwise require server motherboards, while the Arc Pro B60’s 24GB of GDDR6 per GPU makes it particularly well-suited for memory-intensive transformer models. Early testing reveals promising potential, though software optimization still lags the hardware’s capabilities.

Disclosure
Testing was conducted with early software and driver revisions, including development branches of Intel LLM Scaler. Additionally, our test platform utilizes AMD EPYC processors rather than Intel’s Xeon platform. Intel positions Battlematrix as an all-Intel solution with Xeon 6 processors, and production systems with Intel CPUs may demonstrate higher performance than our results suggest. Readers should consider these results preliminary, with the understanding that software maturity and platform optimization should improve throughout 2026.
Specifications and Architecture
| Specification | Detail |
|---|---|
| Product Collection | Intel® Arc™ Pro B-Series Graphics |
| Code Name | Battlemage |
| GPU Architecture | Xe2 (TSMC N5) |
| Xe-cores | 20 |
| Render Slices | 5 |
| Ray Tracing Units | 20 |
| XMX Engines | 160 |
| Xe Vector Engines | 160 |
| Graphics Clock | 2400 MHz |
| Graphics Clock (LP Mode) | 2000 MHz |
| GPU FP32 Performance | 12.28 TFLOPS |
| GPU Peak TOPS (INT8) | 197 |
| Total Board Power (TBP) | 200 W |
| Memory | 24 GB GDDR6 |
| Memory Interface | 192-bit |
| Memory Bandwidth | 456 GB/s |
| Memory Speed | 19 Gbps |
| PCIe Interface | PCIe 5.0 x8 |
| Displays Supported | 4 |
| Graphics Output | HDMI 2.1 | DP2.1 (UHBR 13.5) | DP2.1 (UHBR 10) |
| Max Resolution (HDMI) | 7680 x 4320 @ 120Hz |
| Max Resolution (DP) | 7680 x 4320 @ 60Hz |
| HDMI Variable Refresh Rate | Yes |
| VESA Adaptive Sync | Yes |
| H.264 / H.265 / AV1 Encode/Decode | Yes |
| Ray Tracing Support | Yes |
| oneAPI Support | Yes |
| OpenVINO Support | Yes |
| Intel IPEX Support | Yes |
| Intel XeSS Support | Yes |
The Intel Arc Pro B60 shares its silicon foundation with the gaming-focused Intel Arc B580, both utilizing the same die manufactured on TSMC’s 5nm process. This 272mm² chip contains 19.6 billion transistors and integrates 20 Xe2 cores, advertised to deliver 12.28 TFLOPS of FP32 compute and 197 TOPS of INT8 AI performance per GPU. The critical differentiation lies in memory configuration: while the B580 ships with 12GB of GDDR6, the B60 doubles capacity to 24GB.

Each B60 GPU operates at 2,400MHz across a 192-bit memory interface, providing 456GB/s of bandwidth per GPU. The architecture features 160 XMX (Xe Matrix Extensions) AI engines per GPU, purpose-built for accelerating matrix operations in AI inference.

Dual GPU Design and PCIe Bifurcation
The Maxsun Arc Pro B60 Dual 48G Turbo exemplifies Intel’s density strategy: two complete GPUs mounted on a single dual-slot card, connected independently via PCIe 5.0 x8 interfaces. Unlike traditional dual-GPU designs that bridge chips to act as a single GPU, each B60 GPU presents as a discrete device to the system, requiring motherboard support for PCIe x8/x8 bifurcation. A single x16 slot splits electrically into two x8 connections, with each GPU receiving dedicated bandwidth.

PCIe 5.0 x8 delivers 128GB/s of bidirectional bandwidth per GPU, matching PCIe 4.0 x16. The dual-card configuration measures 300mm in length, occupies two slots with blower-style cooling, and draws 400W total board power via a single 12V-2×6 connector rated for 600W.

Each dual card provides four display outputs: two DisplayPort 2.1 UHBR20 and two HDMI 2.1a ports, one set per GPU, enabling discrete video output configurations for virtualized desktop environments or multi-user systems. A key point to note is that only one of the two display outputs can be used at a time for each GPU.

View this post on Instagram
Eight GPU Battlematrix Configuration
Intel’s reference Battlematrix specification supports up to eight Arc Pro B60 GPUs in a workstation chassis, achieved by using four dual-GPU cards. This configuration delivers:
- 192GB total system VRAM (8 × 24GB)
- 1,280 XMX AI engines
- 1,576 INT8 TOPS aggregate compute
- 3.6TB/s combined memory bandwidth

The platform requires motherboards with four PCIe 5.0 x16 slots supporting bifurcation, and the Battlematrix spec will also include an Xeon 6 processor; however, other information about the Battlematrix configuration is currently unavailable.
Use Cases and Value Proposition
Target Audience
Intel’s Project Battlematrix targets three market segments: AI development teams requiring on-premise infrastructure, software engineering organizations implementing AI-assisted workflows with sensitive codebases, and organizations seeking cost-effective alternatives to cloud-based inference services. The platform’s core value proposition centers on data sovereignty and total cost of ownership advantages over multi-year cloud subscriptions.
Private AI and Agent Development
The Battlematrix platform’s primary strength lies in supporting development workflows for large language models that require extensive context windows and substantial parameter counts.
Development teams building agentic systems particularly benefit from the available memory headroom. RAG agent implementations typically maintain multiple components simultaneously in GPU memory: the base language model, embedding models for vector search, and reranking models. Additionally, agentic workflows perform multi-step reasoning, tool use, and self-correction, generating substantial context windows through iteration. A coding agent analyzing a large codebase may accumulate 100k+ tokens across its operational lifecycle.
Future VDI and Virtualized Gaming
Intel’s roadmap includes enabling SR-IOV (Single Root I/O Virtualization) support on Arc Pro B60 GPUs, transforming the hardware into a multi-user graphics platform. SR-IOV allows subdividing a physical GPU into multiple virtual GPUs, each of which can be assigned to separate virtual machines with direct hardware access and isolated memory spaces.
This capability unlocks license-free Virtual Desktop Infrastructure scenarios in which a single eight-GPU Battlematrix system supports dozens of concurrent users with dedicated GPU acceleration for CAD applications, video editing, or moderate gaming. Traditional VDI solutions require expensive licensing fees on top of hardware costs, which often necessitate more expensive professional or data center GPUs. Intel’s commitment to license-free virtualization eliminates this operational expense.
Pricing and Value Proposition
Intel announced that the Arc Pro B60 will be priced at around $600 per GPU. For initial testing and development, single or dual-card configurations ($600 to $1,200) offer accessible entry points. A single dual-GPU card with 48GB VRAM provides sufficient capacity for quantized models and covers a substantial portion of popular open-source LLM applications.
The Maxsun Dual Arc Pro B60 Dual 48G Turbo configuration we tested costs $1,200 directly from Maxsun, in line with Intel’s original announcement. However, recent fluctuations in memory prices may affect this.
Exceptional Value at Entry Price Points
The single- and dual-card configurations offer compelling economics for small teams, individual developers, and homelabbers. At $600 for 24GB of GPU memory and $1,200 for 48GB, this platform significantly undercuts professional GPU alternatives, which usually cost at least twice as much.
This value proposition particularly resonates for organizations exploring AI integration without committing enterprise budgets.
vLLM Online Serving Benchmark Performance
vLLM is the most popular high-throughput inference and serving engine for LLMs. The vLLM online serving benchmark is a performance evaluation tool that measures real-world serving performance under concurrent requests. It simulates production workloads by sending requests to a running vLLM server with configurable parameters such as request rate, input/output lengths, and number of concurrent clients. The benchmark measures key metrics, including throughput (tokens per second), time to first token (TTFT), and time per output token (TPOT), helping users understand how vLLM performs under different load conditions.
Test Platform:
- Server: Supermicro AS-4125GS-TNRT
- Processors: AMD EPYC 9374F
- Memory: 512GB Samsung 4800 MT/s DDR5
- GPUs: 4x Maxsun MS-Intel ARC Pro B60 Dual 48G Turbo
Quantization Support and Limitations
These GPUs should excel at low-precision inference targeting INT4 quantization for optimal performance. However, due to the very early development version of Intel’s LLM Scaler we were testing, only the GPT OSS models trained initially with the MXFP4 microscaling format functioned correctly. Other quantization formats, including standard INT4, FP8, and AWQ, failed to start entirely. This limitation significantly constrained our ability to thoroughly test these GPUs, though we expect broader support for quantization as the software stack matures.
We tested most models with two configurations: the full eight-GPU Battlematrix setup and the minimum number of GPUs required to fit the model in memory. This comparison reveals interesting scaling characteristics, particularly around communication overhead at lower batch sizes.
Microscaling Datatypes
Microscaling represents an advanced quantization approach that applies fine-grained scaling factors to small blocks of weights rather than uniform quantization across large parameter groups. The MXFP4 format implements this technique using a blocked floating-point representation, where each microscale block shares a common exponent as a scaling factor, preserving numerical precision while achieving 4-bit precision. A key benefit of the MXFP4 data type is that quantizing models to INT4 doesn’t severely degrade response quality, unlike quantizing from higher-precision formats like BF16. The GPT OSS models are run with INT4 quantization on the B60s as they do not natively support MXFP4.
OpenAI GPT-OSS 20B
The 20B parameter model clearly demonstrates the communication overhead phenomenon. At a batch size of 1, a single GPU delivers 49.22 tok/s per user, compared to just 22.83 tok/s when distributed across all eight GPUs. The single-GPU configuration outperforms by over 2x. However, the eight-GPU setup excels at higher concurrency, achieving a total throughput of 511.99 tok/s at a batch size of 16.
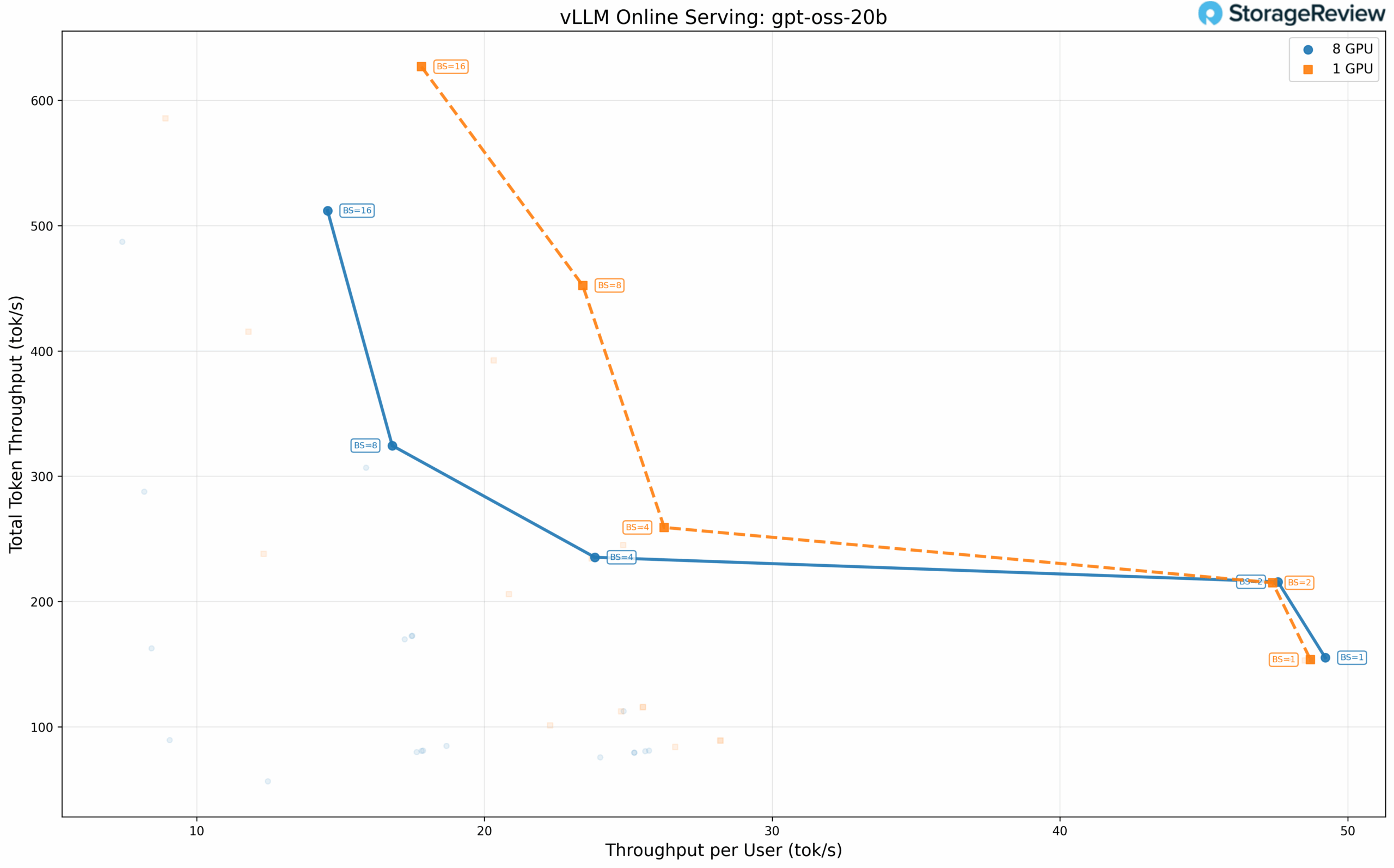 The minimum GPU configuration actually achieves higher total throughput at batch size 16: 626.84 tok/s with TP=4 versus 511.99 tok/s with TP=8. This counterintuitive result underscores that for models and context lengths that fit comfortably on fewer GPUs, adding more hardware introduces communication overhead without proportional performance gains.
The minimum GPU configuration actually achieves higher total throughput at batch size 16: 626.84 tok/s with TP=4 versus 511.99 tok/s with TP=8. This counterintuitive result underscores that for models and context lengths that fit comfortably on fewer GPUs, adding more hardware introduces communication overhead without proportional performance gains.
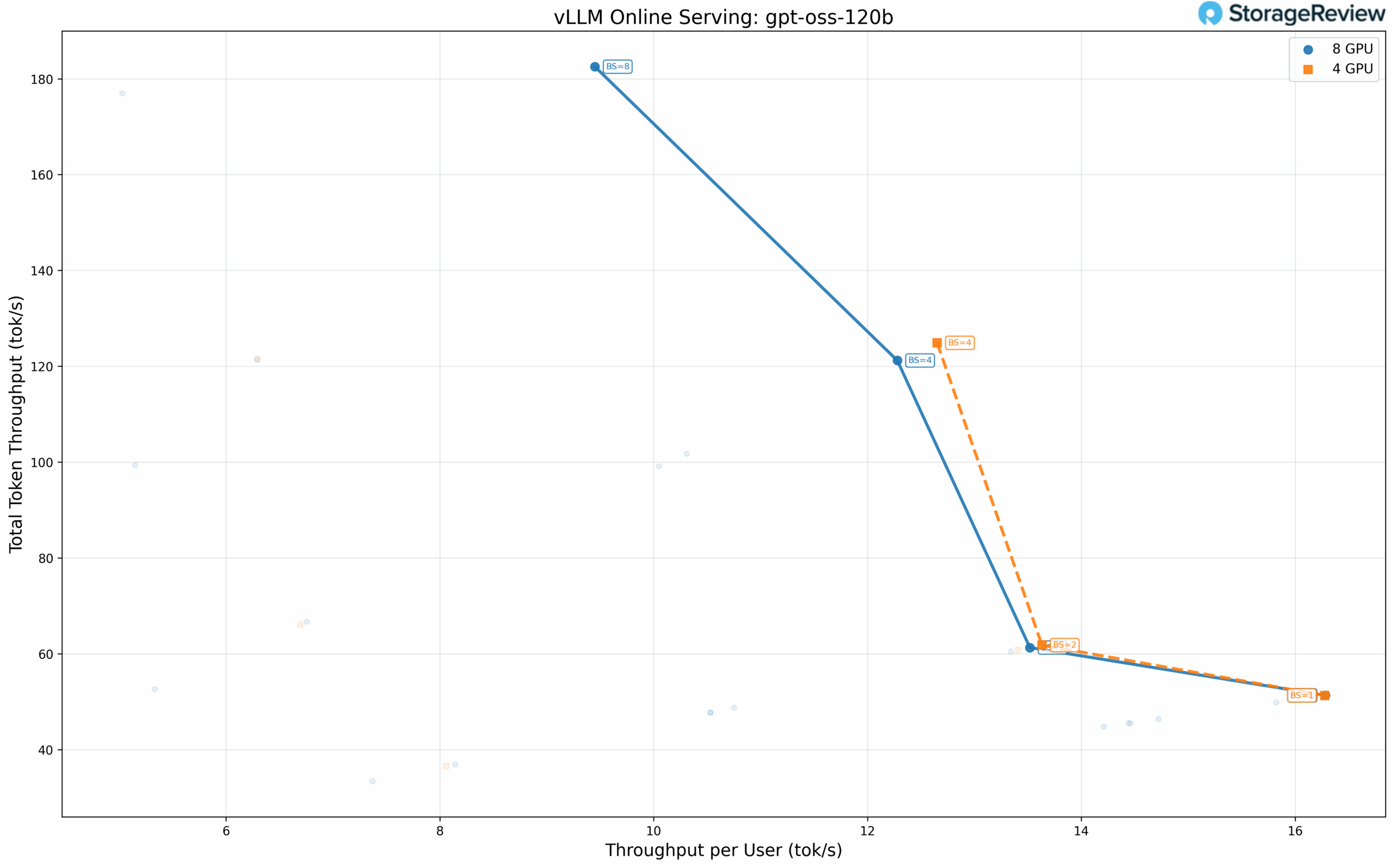
OpenAI GPT-OSS 120B
The larger 120B model requires at least 4 GPUs, eliminating the single-GPU comparison. Performance between four and eight GPU configurations converges more closely, with per-user throughput nearly identical at batch size 1 (16.28 tok/s for both). The eight-GPU configuration provides modest gains at higher batch sizes through data parallelism.
Mixture of Experts: Qwen3 Coder 30B-A3B
Sparse MoE architectures maintain large parameter counts while activating only a subset during inference. Qwen3 Coder 30B-A3B activates approximately 3B parameters per token from its full 30B parameter pool, making it popular for local coding assistant deployments.
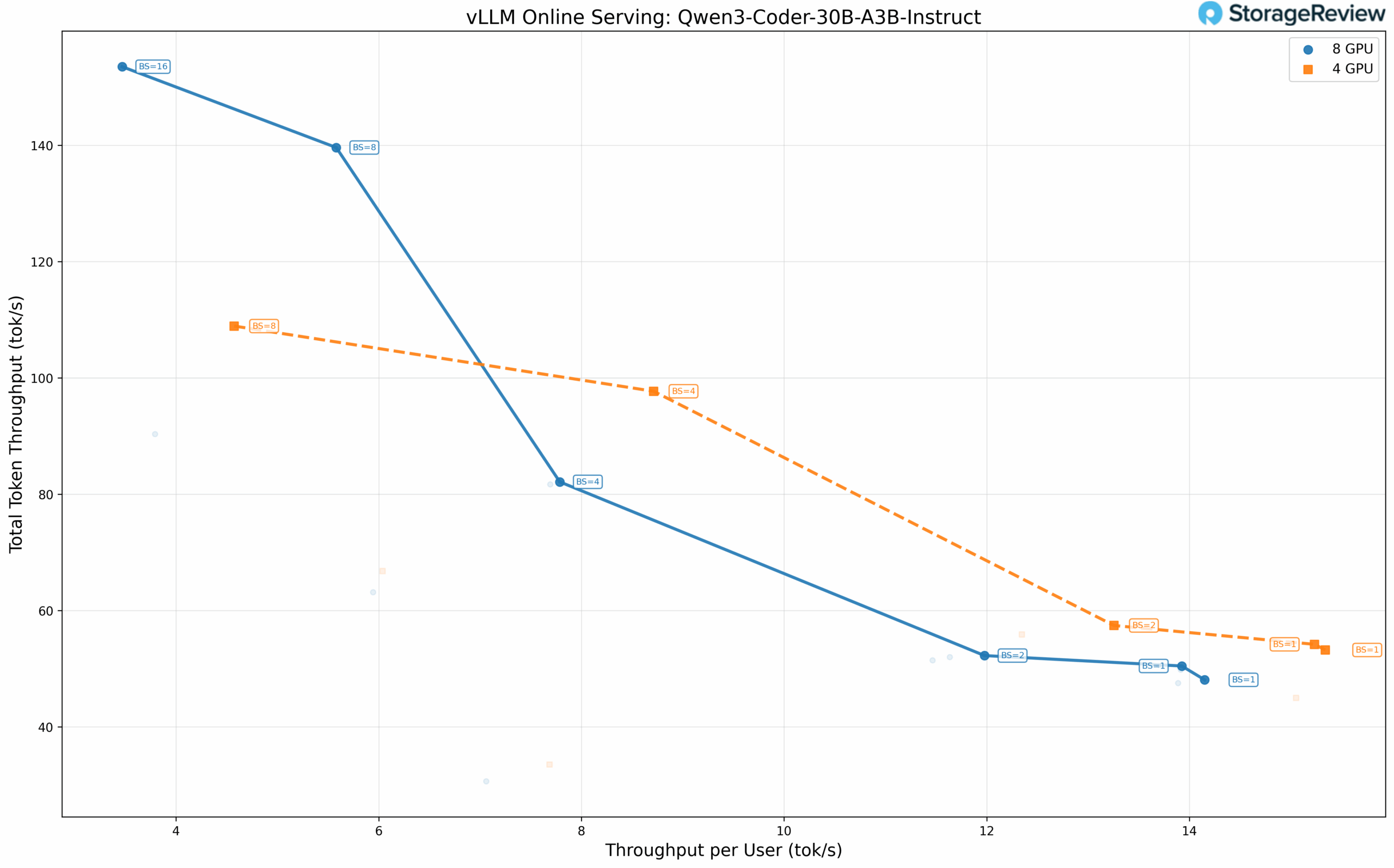
Testing at BF16 precision, the four-GPU configuration again demonstrates advantages at lower batch sizes. Per-user throughput reaches 15.34 tok/s with TP=4, versus 14.15 tok/s with TP=8, at a batch size of 1.
Dense Models
Dense models follow the conventional LLM architecture, where all parameters and activations are used during inference, resulting in more computationally intensive processing than their sparse counterparts. Without working INT4 quantization during our testing window, these models ran at BF16 precision.
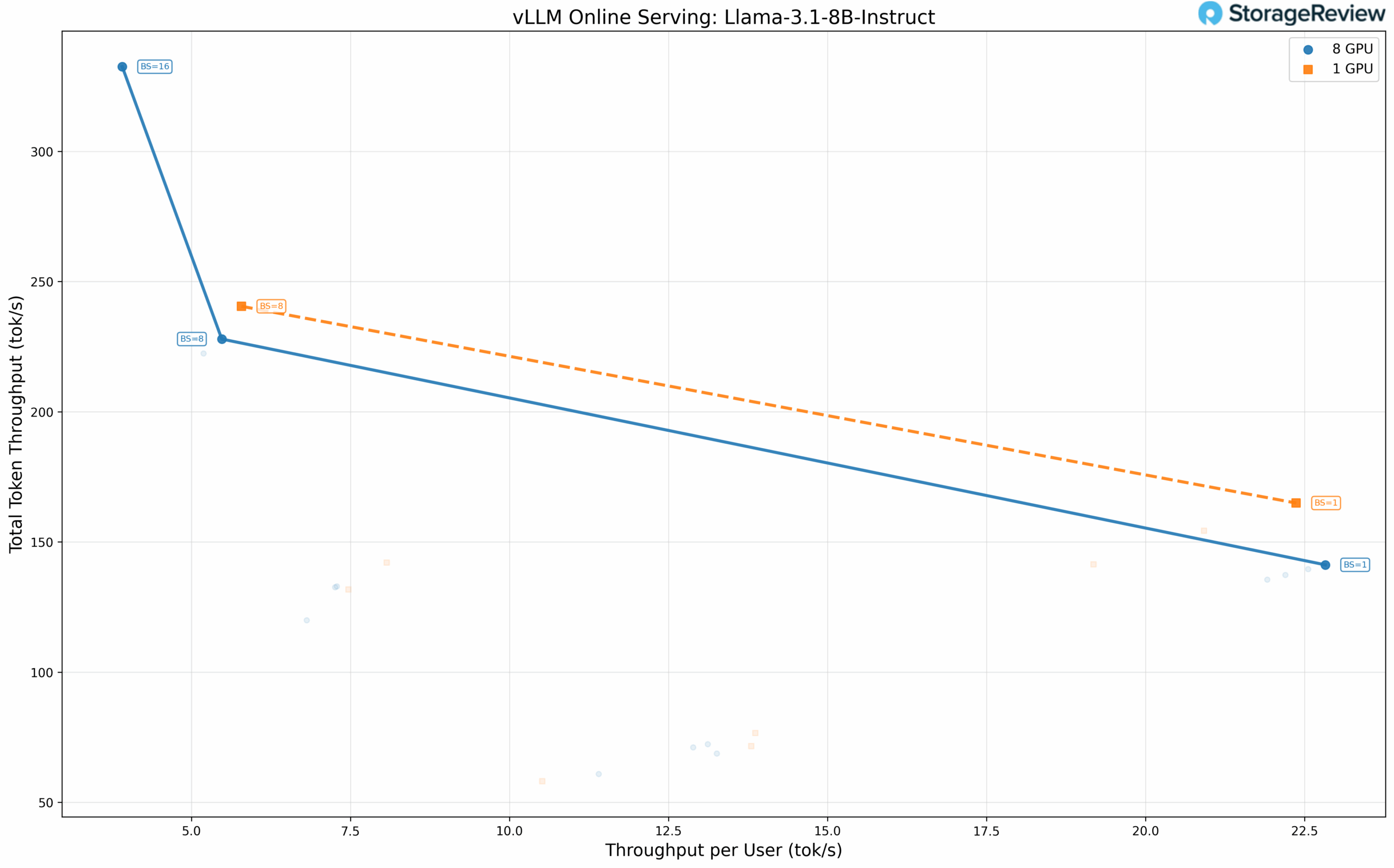
Llama 3.1 8B Instruct
The compact 8B model fits comfortably on a single GPU but was tested across configurations to characterize scaling behavior. Results confirm the pattern: four GPUs deliver 240.48 tok/s total throughput at batch size 8 compared to 227.90 tok/s with eight GPUs at the same batch size. Per-user throughput at batch size 1 remains nearly identical (22.37 tok/s vs. 22.83 tok/s).
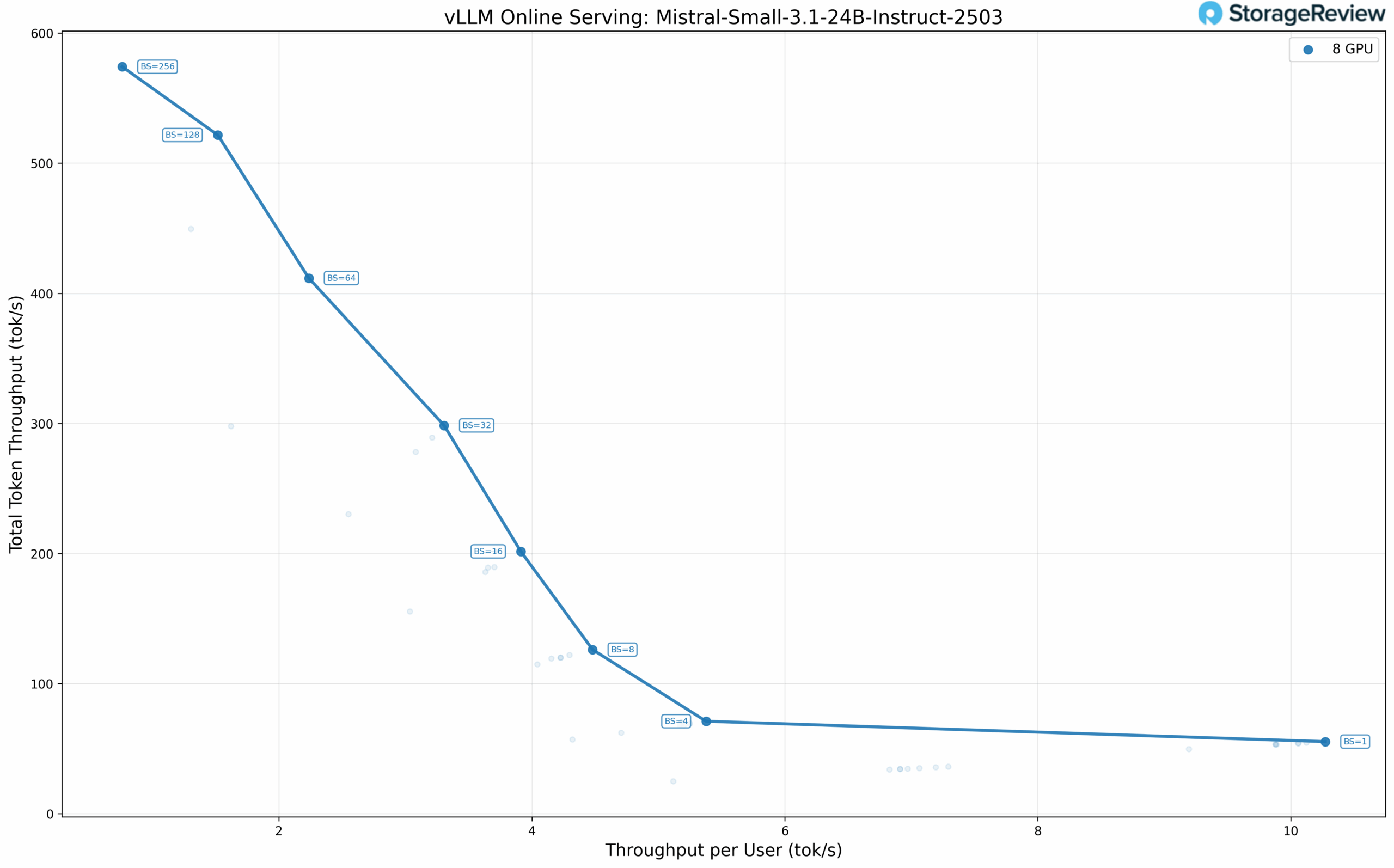
Mistral Small 3.1 24B Instruct
The 24B parameter Mistral model represents a more demanding workload. At BF16 precision, the model achieves strong throughput scaling at higher batch sizes, reaching 574.16 tok/s at a batch size of 256 across all eight GPUs.
Findings
A consistent pattern emerges across all tested models: at low batch sizes with our 256 input/output token configuration, using the minimum number of GPUs required to fit the model delivers better per-user performance than distributing across all eight GPUs. The inter-GPU communication overhead via PCIe, even at PCIe 5.0 speeds, introduces latency that exceeds the parallelization benefits for single-user or low-concurrency scenarios.
This finding has practical implications for deployment planning. Organizations running single-user coding assistants or low-concurrency agent workflows can get away with smaller GPU configurations and still get acceptable performance. The full eight-GPU Battlematrix configuration is most advantageous for batch inference workloads, synthetic data generation, or high-concurrency serving scenarios where total throughput matters more than per-request latency, especially when using bigger models that require more memory.
Experience with Arc Pro B60s
In the limited testing we conducted, the experience was remarkably painless. Getting the cards up and running was simple, and setting up LLM-Scaler, the development branch of vLLM with Battlemage support, proved equally straightforward. However, the software remains very early in development. When we began testing, we were unable to retrieve any GPU statistics, and beyond tensor parallelism, we had no luck with other parallelism strategies, such as expert parallelism or pipeline parallelism, for scaling across multiple systems. That said, we expected these limitations going in, given the software stack’s pre-release state.
Cooling generated considerable discussion following our initial YouTube short, with many commenters expressing concern that the cards might overheat on our open test bed. Without thermal monitoring available, we ultimately relocated the cards to a server chassis to ensure adequate airflow. We do intend to test cooling performance in the workstation configuration for our full review, since the final Battlematrix build, as shown in Intel’s marketing renders above, places these cards in a workstation chassis stacked close together.
Regarding form factor, these cards are slightly longer than standard workstation GPUs, which may create case-compatibility challenges. However, they fit without issue in server chassis, as most server enclosures provide extra space toward the leading edge of the card for support brackets.
Future Testing Plans
We plan to revisit the Intel Battlematrix and do a more extensive review after the full release and general availability of B60s. We will evaluate LLM inference performance through additional vLLM testing across a wide range of models and deployment configurations. Although not shown in this preview, we observed that these GPUs, in their current software state, perform better on prefill than on decode operations. The full review will dive deeper into prefill-heavy and decode-heavy inference workloads to characterize this behavior.
The homelab community expressed interest in using these GPUs for one of the most popular homelab workloads: media servers. We look to test these with Plex and possibly Jellyfin with members in our Discord. Professional workloads are also on our radar, including SolidWorks and Autodesk for CAD performance testing. We also plan to look at SR-IOV with Proxmox to deploy a multi-user VDI server for Discord members to evaluate concurrent desktop density and cloud gaming.
Conclusion
Intel’s Arc Pro B60 Battlematrix is an exciting platform that makes high-capacity GPU memory accessible at workstation price points. The dual-GPU card design addresses density constraints, the 24GB per GPU allocation suits LLM inference workloads, and the pricing structure creates compelling alternatives to established professional GPU ecosystems. For organizations prioritizing data sovereignty and cost efficiency over bleeding-edge performance, the platform merits consideration.
Software maturity remains the primary constraint. Intel’s investment in framework optimization via LLM Scaler and ongoing driver refinement indicates a commitment to maintaining the Arc line of GPUs as a considerable value.
It is unknown how popular the eight-GPU battlematrix configuration will be compared to the incredible performance delivered by NVIDIA DGX Spark. The real story may be the single- and dual-card configurations, where $600-1,200 entry points dramatically lower barriers to private AI infrastructure exploration.
We will continue expanding our testing as driver updates arrive and software frameworks mature. If you would like to try these yourself, join our Discord server, where we have a community server with limited B60 access.


 Amazon
Amazon