

Supermicro’s JumpStart program has established itself as one of the more useful tools in the pre-purchase evaluation toolkit for AI infrastructure. Rather than a scripted demo in a shared environment, JumpStart gives qualified users free, time-boxed, bare-metal access to real production servers via SSH, IPMI, and VNC, enabling them to run workloads on actual hardware. We covered the program in depth last November using an X14 system with an NVIDIA HGX B200, and came away with a clear picture of what a week of focused access can and cannot tell you. This time, Supermicro provided access to an H14 8U system with a very different accelerator story.
We tested the AS-8126GS-TNMR system, an 8U air-cooled platform built around dual AMD EPYC 9575F processors and eight AMD Instinct MI350X GPUs. The MI350X is AMD’s current flagship data center accelerator, built on the 4th Gen CDNA architecture at TSMC’s 3nm node and featuring 288GB of HBM3e per GPU. Across eight GPUs interconnected via AMD Infinity Fabric, the server offers 2.3 TB of total GPU memory in a single node, with an aggregate bandwidth of 1,024 GB/s. The full system uses six 5,250W Titanium-level power supplies in a 3+3 redundant configuration, and Supermicro has provisioned dedicated 400 Gbps networking per GPU for scale-out deployments.

AMD’s position in the data center GPU market has shifted meaningfully in the past two years, and the MI350X generation represents a more serious competitive challenge to NVIDIA than any prior Instinct product. ROCm 7, released in September 2025 and now at version 7.2, brought native MI350X support alongside dramatically improved inference performance, HIP API updates that close the CUDA compatibility gap, and broadened framework support, including PyTorch, JAX, TensorFlow, ONNX Runtime, vLLM, and SGLang.
The vLLM project added a dedicated AMD ROCm CI pipeline in late December 2025, making AMD hardware a first-class platform in that inference stack rather than a downstream port. The ecosystem’s adoption is also hard to ignore: AMD and Meta announced a multi-year, multi-generation 6-gigawatt GPU deployment agreement in February 2026, building on Meta’s existing production deployments of MI300 and MI350 series hardware. That level of commitment from one of the world’s largest AI infrastructure operators is no marketing footnote.
For organizations currently evaluating AI accelerator infrastructure, the lead time for NVIDIA hardware remains a concern. The question is whether AMD is a credible alternative rather than a fallback. Based on a week of testing with ROCm 7.2.0 and the current vLLM, the answer is meaningfully different from what it was 18 months ago.

Our testing covered a selection of popular models; the 2.3TB of HBM3e across a single node enabled single-server inference on large-parameter models, including Moonshot’s Kimi K2.5 and MiniMax M2.5.
AMD Instinct MI350X: Architecture and Generational Improvements
The MI350X represents AMD’s most architecturally ambitious generational leap in the Instinct product line to date. Understanding the engineering decisions behind it provides important context for interpreting the subsequent performance results.
CDNA 4 Architecture and Process Node Transition
The foundational shift from the MI300 series to the MI350 series centers on adopting TSMC’s N3P process node for the Accelerator Compute Chiplets (XCDs), moving from the 5nm fabrication used in the prior generation. The total transistor count reaches approximately 185 billion, a roughly 21% increase over the MI300 generation, achieved without a corresponding increase in power consumption.
The MI350X retains AMD’s proven multi-chiplet packaging strategy. At its core, the GPU package features eight Accelerator Compute Chiplets (XCDs) as the primary computational engines. Each XCD houses four shader engines, each with eight active CDNA 4 compute units, yielding 32 CUs per XCD and a total of 256 CUs for the full accelerator.
The I/O Die layer was also consolidated from four tiles to two in the CDNA 4 package design. This reorganization enabled AMD to double the Infinity Fabric bus width, improving bi-sectional bandwidth while lowering the bus frequency and operating voltage to reduce power consumption.
Redesigned Compute Units and Expanded Precision Support
With the CDNA 4 compute unit matrix math capabilities, there is a substantial boost: MI350 CUs deliver a 2x increase in throughput per CU for 16-bit (BF16, FP16) and 8-bit (FP8, INT8) operations compared to their MI300 counterparts.
Beyond raw throughput gains, CDNA 4 introduces hardware support for lower-precision data types absent from the MI300 series, specifically FP6 and FP4, alongside the existing FP8 support carried forward from the prior generation.
In addition to these standard formats, the MI350X adds native hardware support for the OCP microscaling variants: MXFP4, MXFP6, and MXFP8. Microscaling formats are designed to deliver the throughput advantages of lower-precision compute while maintaining output quality closer to higher-precision baselines than standard quantization typically allows. This is not an AMD-specific development. NVIDIA’s NVFP4 format operates on the same microscaling principles and has seen broad adoption across frontier model deployments, with the GPT-OSS family from OpenAI as one of the most prominent examples built around these formats. The MI350X’s native MXFP4 support allows it to serve these and similar quantized model families without falling back to software emulation or precision promotion.
The MI350X delivers 9.2 PFLOPs at MXFP4 and MXFP6, compared with 4.6 PFLOPs at OCP-FP8, with FP16 at 2.3 PFLOPs and a peak engine clock of 2,200 MHz. For inference-optimized deployments where microscaling quantization is viable, the compute headroom effectively doubles relative to FP8 workloads. A new vector ALU has also been added to the CDNA 4 compute unit, supporting 2-bit operations and capable of accumulating BF16 results into FP32, providing additional flexibility for low-precision vector workloads outside the primary matrix compute path.
Memory Subsystem: HBM3e, Infinity Cache, and Bandwidth Efficiency
The MI350 series features a substantially upgraded memory subsystem with eight HBM3e memory stacks, providing a total capacity of 288GB per GPU. Each 36GB stack, composed of 12-high 24Gbit devices, operates at the full HBM3e pin speed of 8Gbps per pin. The architecture retains AMD’s Infinity Cache, a memory-side cache positioned between the HBM and the Infinity Fabric/L2 caches. It comprises 128 channels, each backed by 2 MB of cache, for a total of 256 MB per GPU. AMD has widened the on-die network buses within the IODs and operates them at a reduced voltage, enabling approximately 1.3x higher memory bandwidth per watt compared to the MI300 series.
The increase in memory capacity from the MI300X’s 192GB to 288GB extends AMD’s lead in per-GPU memory headroom, with direct implications for large-model inference. Each MI350X GPU can independently host models with more than 500 billion parameters. Across an eight-GPU server, the aggregate 2.3TB of HBM3e eliminates the multi-node distribution requirements that complicate trillion-parameter deployments, as the Kimi K2.5 and MiniMax M2.5 results in this review demonstrate.
Flexible Partitioning and Deployment Architecture
The MI350 series supports flexible GPU partitioning per socket, with memory split into two separate clusters. This flexibility also applies to the XCDs, where the quad XCD cluster can be split into dual or single blocks, enabling the chip to support configurations such as 8 instances of 70B models in CPX+NPS2. For organizations running heterogeneous inference workloads across shared infrastructure, this partitioning capability reduces the need for dedicated hardware per model tier and improves utilization economics across mixed deployment environments.
The MI350 series also maintains drop-in compatibility with the UBB (Universal Base Board) infrastructure used in MI300 Series systems. Existing server chassis, power delivery, and cooling infrastructure carry forward without modification, reducing upgrade friction for organizations with active MI300 deployments.
MI355X: The Liquid-Cooled Sibling
The MI350 series ships in two variants built on identical underlying silicon and optimized for different thermal operating envelopes. The MI350X tested here is the air-cooled variant, while the MI355X is its liquid-cooled counterpart, designed for higher-density deployments where direct liquid-cooling infrastructure is available.
While both variants are built on the same fundamental hardware, the MI355X’s higher operational power envelope enables higher sustained clock frequencies, resulting in an approximate 20% performance advantage in real-world, end-to-end workloads compared to the MI350X. The MI355X carries a TBP ceiling of 1,400W versus the MI350X’s 1,000W, with clock speed topping out at 2.4 GHz compared to 2.2 GHz on the air-cooled variant.
In generational terms, the MI355X platform delivers up to 4x peak theoretical performance improvement over the MI300X, with real-world inference gains of approximately 4.2x in agentic and chatbot workloads and about 3x in content generation scenarios. For organizations evaluating MI350X deployments, the 20% performance differential between the two variants represents a clear ceiling. Facilities with DLC infrastructure should evaluate the MI355X to determine whether the thermal investment yields sufficient throughput uplift for their specific workload profile before committing to air-cooled configurations at scale.
Accessing the AMD Instinct MI350X via Supermicro JumpStart Program
Getting started with JumpStart requires registering on Supermicro’s portal, where qualified users can browse available systems and schedule a reservation window. Once approved, the portal provides SSH credentials, IPMI access, and a web-based remote console for the duration of the booking. The system arrives preinstalled with Ubuntu and ready to use. There is no provisioning delay and no support interaction required to get started. Our reservation ran from March 23 through March 27, 2026, giving us a full week on the platform, consistent with our prior JumpStart engagement on the HGX B200.
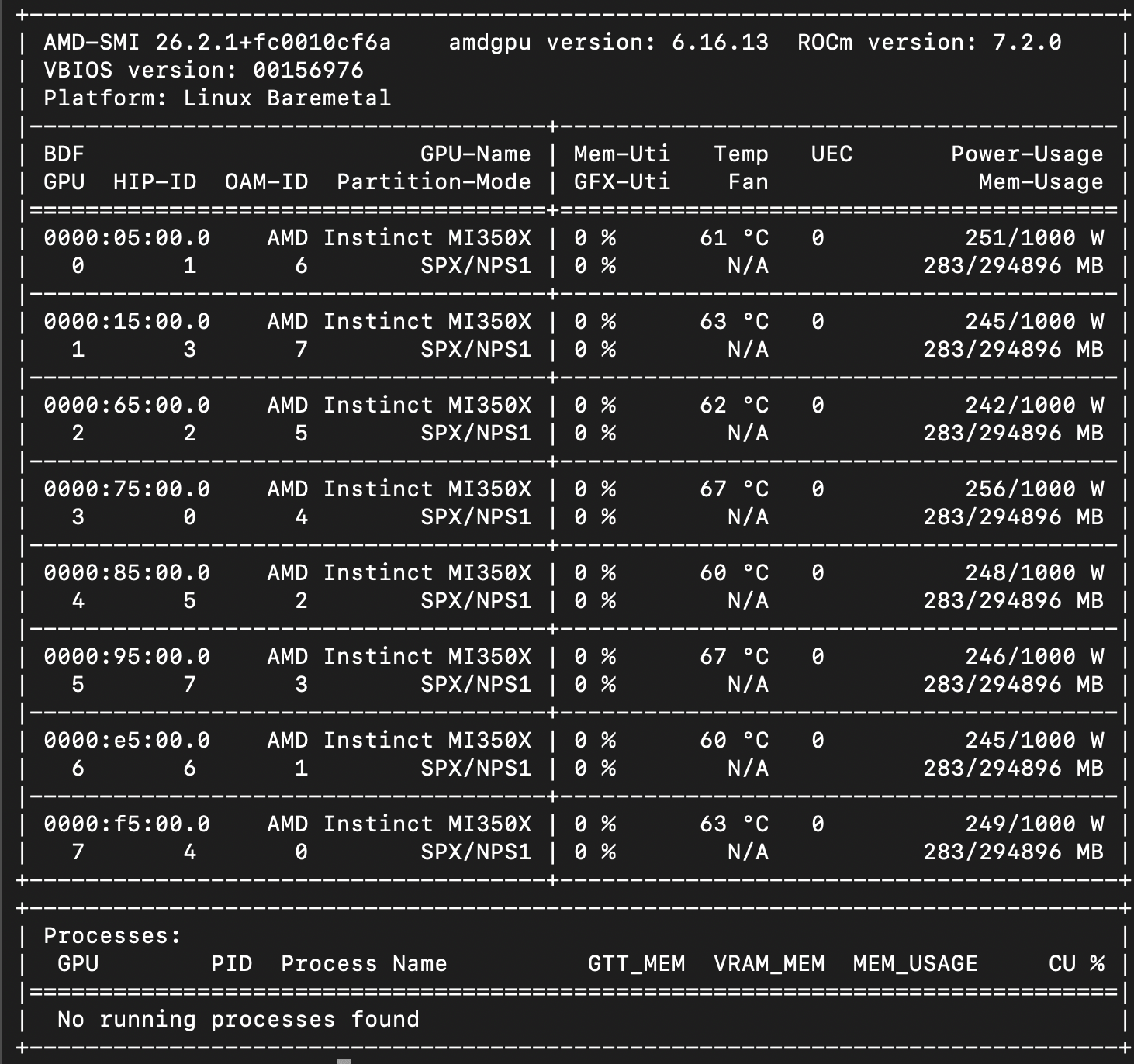
The screenshot below shows our terminal output from jumpstart for the H14 system, with the AMD-SMI tool displaying the eight AMD Instinct MI350X GPUs and their running software versions.
AMD Instinct MI350X Performance Testing Results
System Configuration
- Chassis: Supermicro H14
- CPU: Dual AMD EPYC 9575F
- Memory: 3TB DDR5
- GPU: eight AMD Instinct MI350X
- Storage: 2x 3.8TB PCIe 4.0 M.2 NVMe SSD and 1 x 1.92TB NVMe M.2
Summary of Results
| Model | Precision | Equal (256/256) | Prefill-Heavy (8k/1k) | Decode-Heavy (1k/8k) |
|---|---|---|---|---|
| GPT-OSS 20B | NVFP4 | 62,247 | 123,714 | 32,468 |
| GPT-OSS 120B | NVFP4 | 33,538 | 84,018 | 20,602 |
| Llama 3.1 8B Instruct | BF16 | 51,467 | 77,658* | 19,326 |
| Mistral Small 3.1 24B | FP8 | 40,742 | 56,093 | 14,557 |
| Mistral Small 3.1 24B | BF16 | 30,530 | 53,740 | 13,559 |
| Qwen3 Coder 30B A3B | BF16 | 34,980 | 51,550 | 11,782 |
| Qwen3 Coder 30B A3B | FP8 | 25,928 | 47,179 | 11,014 |
| MiniMax M2.5 | Block-Scaled FP8 | 14,391 | 23,689 | 6,068 |
| Kimi K2.5 | INT4 QAT + BF16 | 6,527 | 11,256 | 2,513 |
| All values in tok/s, peak throughput at BS=256. *Llama 3.1 8B prefill-heavy peaked at BS=128 (77,658 tok/s); BS=256 was 76,893 tok/s. | ||||
Claude Code Serving – MiniMax M2.5
Beyond traditional raw LLM inference benchmarks, we wanted to evaluate how well this hardware performs in an agentic coding workflow, specifically serving multiple concurrent Claude Code sessions with a locally hosted model. This use case maps directly to development team productivity: how many engineers can simultaneously use an AI coding assistant served from a single node before the experience degrades?
To test this, we built a benchmark harness that generates a dataset of moderately difficult coding problems (tasks like implementing an LRU cache, building a CLI todo application, writing a markdown converter, and constructing a REST API) and runs each Claude Code session in its own Docker container against the local vLLM server. A transparent proxy sits between the sessions and the inference endpoint, capturing per-request metrics for each Claude code instance. The model used was MiniMax M2.5, served via vLLM on the eight MI350X GPUs. While not the top-ranked coding model on public leaderboards, M2.5 is a capable model that many users run locally, including many of our developer friends.
For a baseline reference point, we use Anthropic’s Claude Opus 4.6 average output throughput via OpenRouter.ai, one of the most popular routing services for production API access. That baseline comes in at approximately 37 tokens per second per API request.
We measured two key metrics: the average output tokens per second per Claude Code session (what each developer experiences) and the aggregate output tokens per second across all sessions (the total work the server is producing).
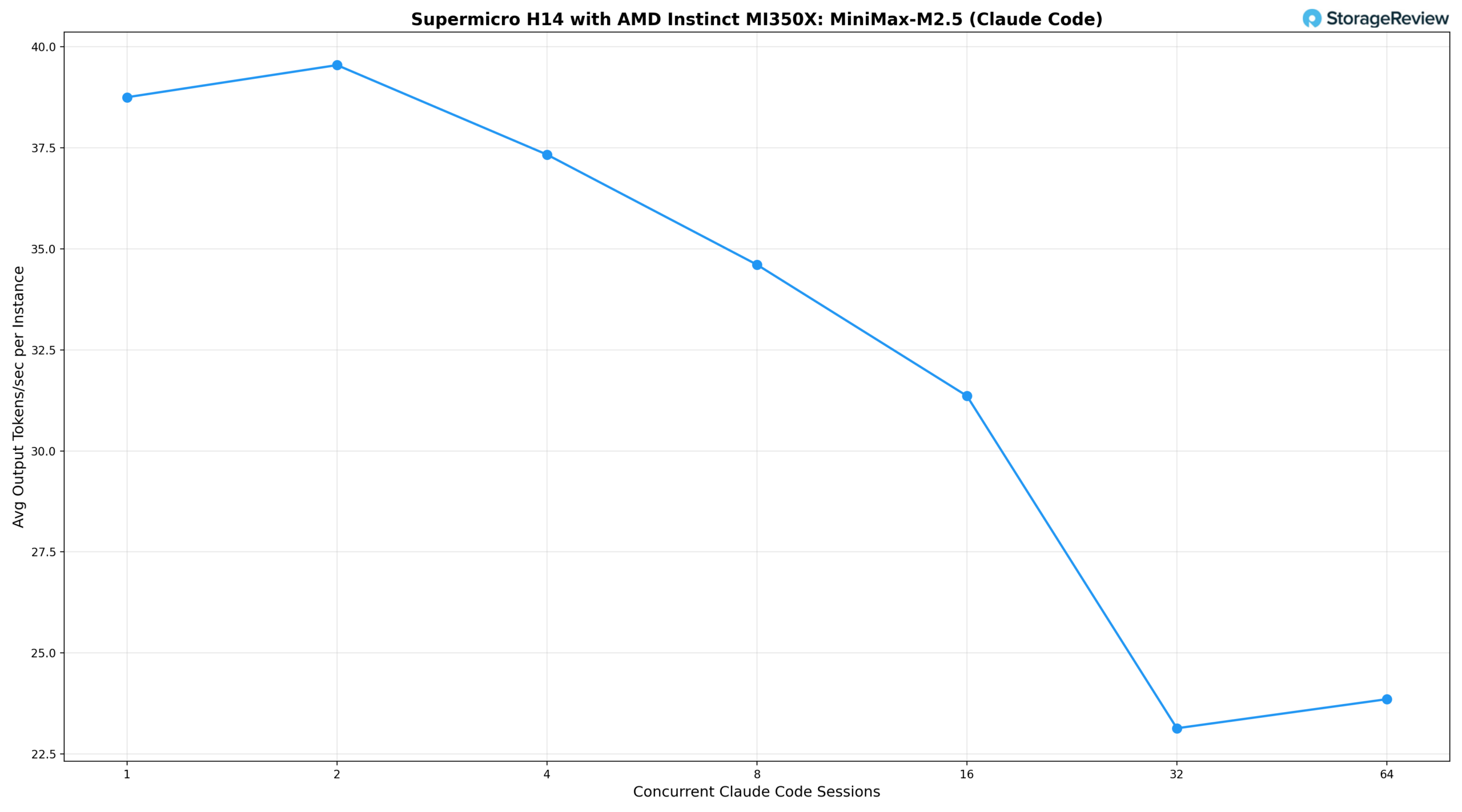
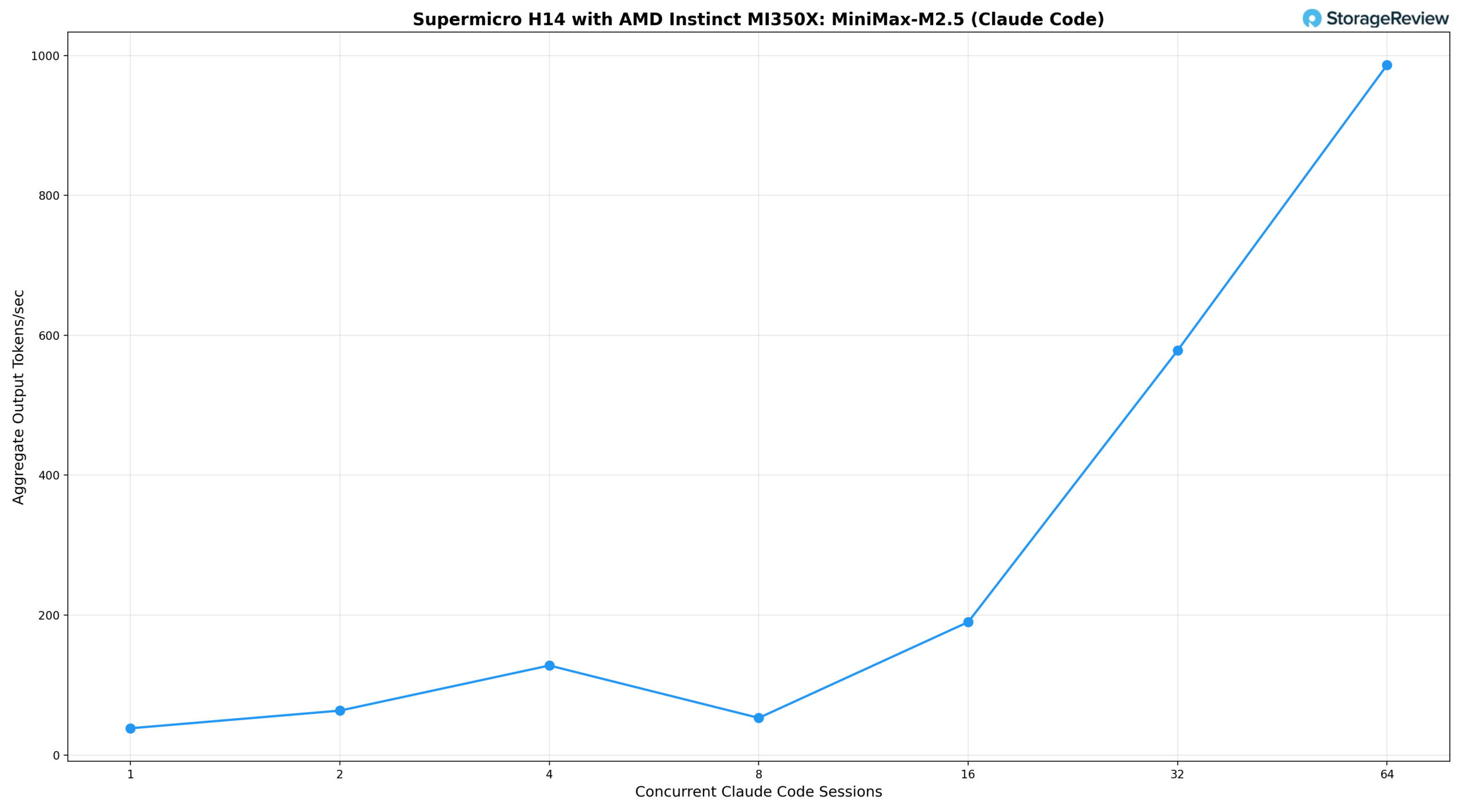
Looking at the results, a single concurrent session delivers 38.8 tok/s per user and 38 tok/s aggregate, slightly above the OpenRouter cloud baseline. At two sessions, the system edges up to 39.5 tok/s per user as vLLM’s batching begins to amortize overhead, with aggregate throughput climbing to 63 tok/s. Four concurrent sessions are held at 37.3 tok/s per user, matching the cloud baseline while serving four developers simultaneously, with aggregate throughput reaching 128 tok/s. From eight sessions onward, per-instance throughput begins to decline: 34.6 tok/s per user at eight sessions, 31.4 tok/s at sixteen with an aggregate of 190 tok/s, and settles around 23 tok/s per user at 32 and 64 sessions, while aggregate throughput climbs to 578 tok/s and 986 tok/s, respectively. This is the classic batching-throughput-versus-interactivity trade-off: the system can achieve significantly higher total throughput by batching more requests, but each user experiences slower response times. Even at 64 concurrent users, each developer still sees a usable interactive experience, though noticeably slower than the cloud baseline.
For organizations weighing the cost of dozens of simultaneous commercial API subscriptions against self-hosted infrastructure, the tradeoff is clear: a single MI350X node can serve a development team of 16 to 32 engineers, maintaining per-user response speeds within 60-85% of the cloud baseline while delivering aggregate output of 600 to 1,000 tok/s, with added benefits of data locality, no per-token API charges, and full control over model selection.
vLLM Online Serving – LLM Inference Performance
vLLM is one of the most popular high-throughput inference and serving engines for LLMs. The vLLM online serving benchmark evaluates the real-world serving performance of this inference engine under concurrent requests. It simulates production workloads by sending requests to a running vLLM server, with configurable parameters such as request rate, input/output lengths, and the number of concurrent clients. The benchmark measures key metrics, including throughput (tokens per second), time to first token, and time per output token (TPOT), helping users understand how vLLM performs under different load conditions.
We tested inference performance across a comprehensive suite of models spanning various architectures, parameter scales, and quantization strategies to evaluate throughput under different concurrency profiles.
GPT-OSS 120B and 20B
The GPT-OSS model family was tested in both 120B and 20B configurations on the Supermicro H14.
GPT-OSS 120B
The 120B model under an equal workload (256/256) delivers 313.42 tok/s at BS=1, reaches 11,261.72 tok/s at BS=64, and peaks at 33,538.23 tok/s at BS=256. Prefill-heavy (8k/1k) starts at 1,724.84 tok/s, climbs to 36,156.80 tok/s at BS=32 and 79,247.76 tok/s at BS=128, peaking at 84,018.79 tok/s at BS=256. Decode-heavy (1k/8k) grows from 288.90 tok/s at BS=1 to 20,602.52 tok/s at BS=256, with latency remaining well-controlled at lower concurrency levels.
GPT-OSS 20B
The 20B model delivers 485.17 tok/s at BS=1 under the equal workload, reaching 17,986.36 tok/s at BS=64 and peaking at 62,247.52 tok/s at BS=256. Prefill-heavy starts at 3,120.72 tok/s, climbs to 48,132.52 tok/s at BS=32 and 83,968.71 tok/s at BS=64, peaking at 123,714.50 tok/s at BS=256—the highest absolute prefill throughput recorded across both model sizes. Decode-heavy grows from 378.20 tok/s at BS=1 to 32,468.67 tok/s at BS=256, delivering roughly 1.6× the decode throughput of the 120B at peak concurrency while maintaining tighter latency characteristics throughout.
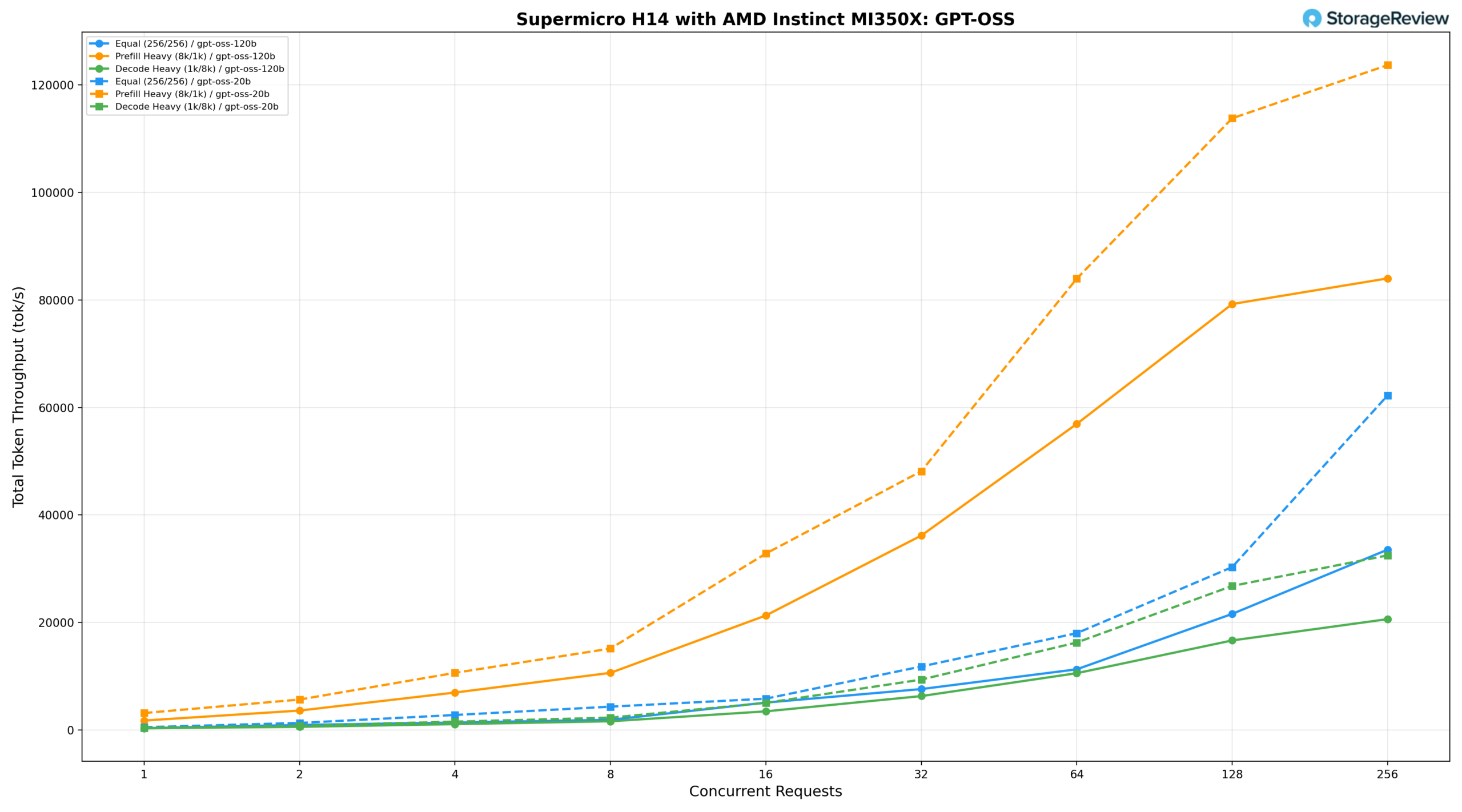
Qwen3 Coder 30B A3B Instruct and FP8 Instruct
The Qwen3-Coder-30B-A3B-Instruct on the Supermicro H14 was tested at both standard (BF16) and FP8 precisions.
Qwen3-Coder-30B-A3B-Instruct (BF16)
At BF16, the equal workload (256/256) delivers 240.53 tok/s at BS=1, reaching 13,312.70 tok/s at BS=64 and 21,333.79 tok/s at BS=128, with peak throughput of 34,980.97 tok/s at BS=256. Prefill-heavy (8k/1k) starts at 1,276.76 tok/s, climbs to 25,069.32 tok/s at BS=32 and 50,198.94 tok/s at BS=128, peaking at 51,550.66 tok/s at BS=256. Decode-heavy (1k/8k) grows steadily from approximately 188 tok/s at BS=1 to 11,782 tok/s at BS=256, maintaining the tightest latency profile of the three scenarios.
Qwen3-Coder-30B-A3B-Instruct (FP8)
The FP8 variant delivers 188.92 tok/s at BS=1 under the equal workload, reaching 10,866.27 tok/s at BS=64 and 17,617.60 tok/s at BS=128, peaking at 25,928.77 tok/s at BS=256—running slightly behind BF16 results across the full range. Prefill-heavy starts at 860.07 tok/s, climbs to 20,513.77 tok/s at BS=32 and 44,205.46 tok/s at BS=128, peaking at 47,179.15 tok/s at BS=256. Decode-heavy grows from 133.79 tok/s at BS=1 to 11,014.95 tok/s at BS=256, scaling consistently and remaining close to BF16 throughout.
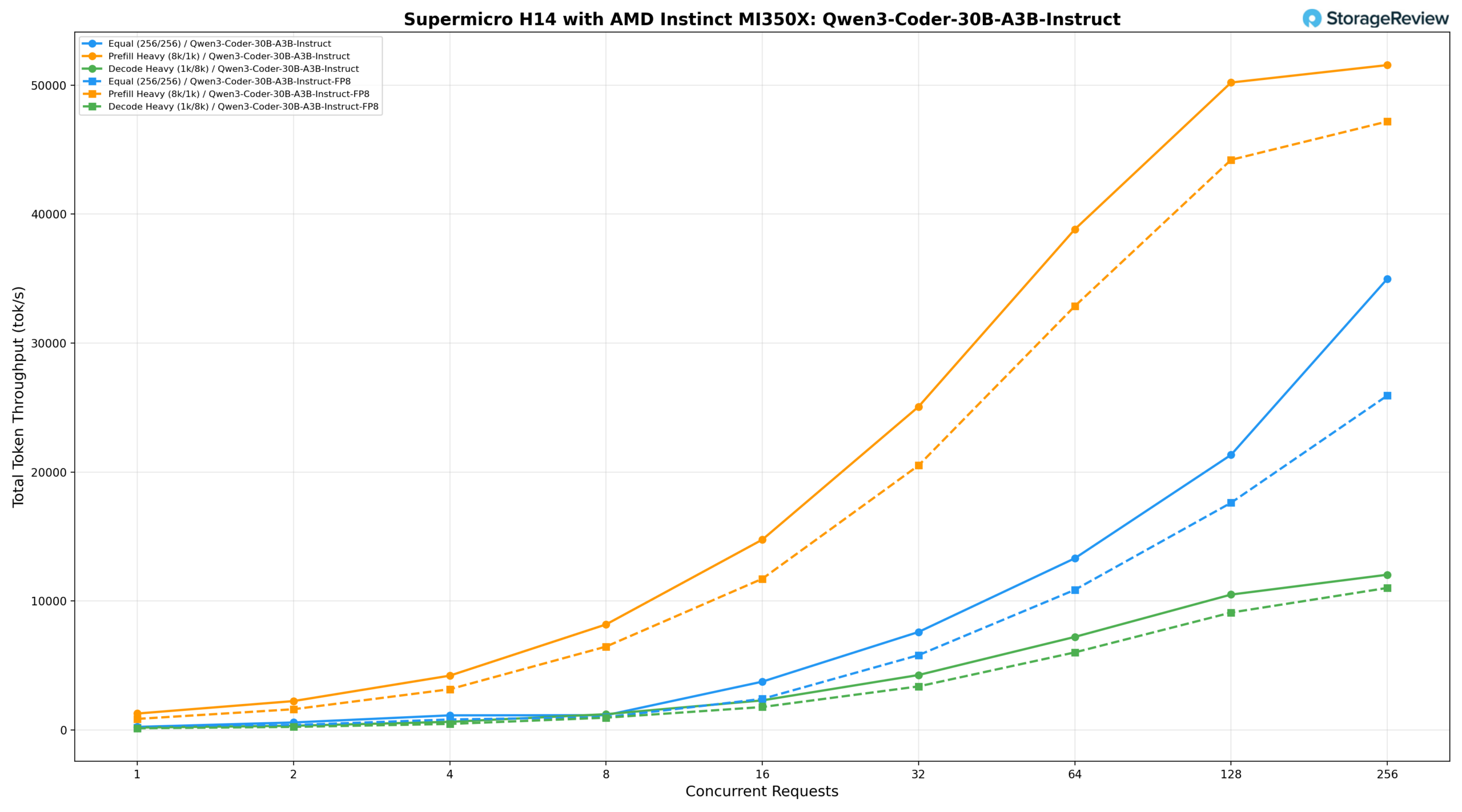
Mistral Small 3.1 24B Instruct 2503
The Mistral-Small-3.1-24B-Instruct-2503 on the H14 was tested with both standard and FP8-dynamic precision, showing consistent scaling across all three workload profiles.
Mistral-Small-3.1-24B-Instruct-2503 (BF16)
With BF16 precision, the equal workload (256/256) delivers 236.15 tok/s at BS=1, reaching 15,494.56 tok/s at BS=64, 24,216.52 tok/s at BS=128, and peaking at 30,530.54 tok/s at BS=256. Prefill-heavy (8k/1k) starts at 1,429.41 tok/s, climbs to 29,631.68 tok/s at BS=32 and 54,871.74 tok/s at BS=128, peaking at 53,740.04 tok/s at BS=256. Decode-heavy (1k/8k) grows from 242.66 tok/s at BS=1 to 13,559.19 tok/s at BS=256, scaling steadily across the full range.
Mistral-Small-3.1-24B-Instruct-2503 (FP8-dynamic)
The FP8-dynamic variant delivers 184.25 tok/s at BS=1 under the equal workload, reaching 16,113.95 tok/s at BS=64 and 26,409.01 tok/s at BS=128, peaking at 40,742.04 tok/s at BS=256. Prefill-heavy starts at 1,210.06 tok/s, climbs to 28,773.52 tok/s at BS=32 and 57,765.02 tok/s at BS=128, peaking at 56,093.09 tok/s at BS=256, leading the standard precision result from BS=64 onward. Decode-heavy grows from 183.94 tok/s at BS=1 to 14,557.94 tok/s at BS=256, tracking closely through mid-range before pulling slightly ahead at BS=128 and BS=256.
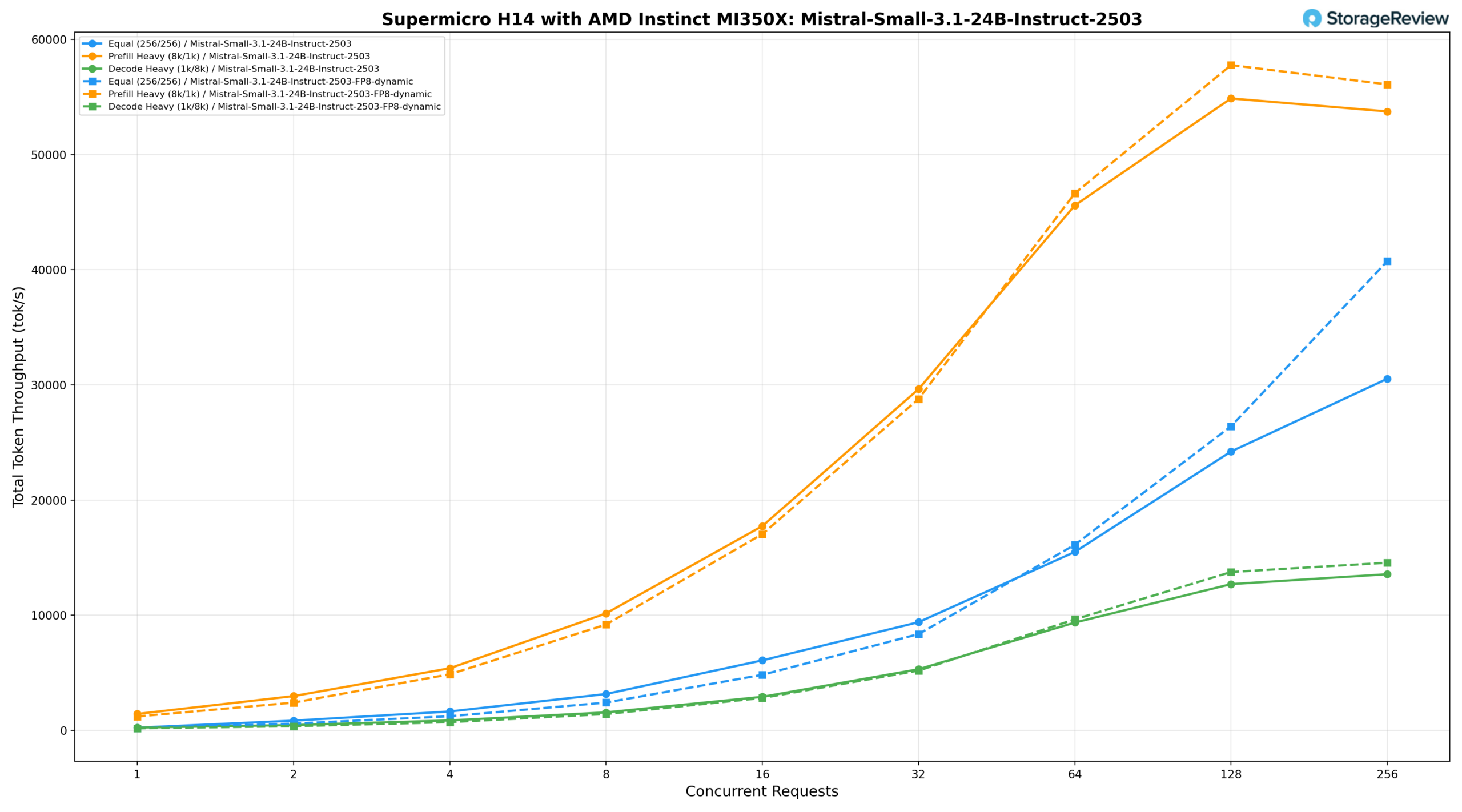
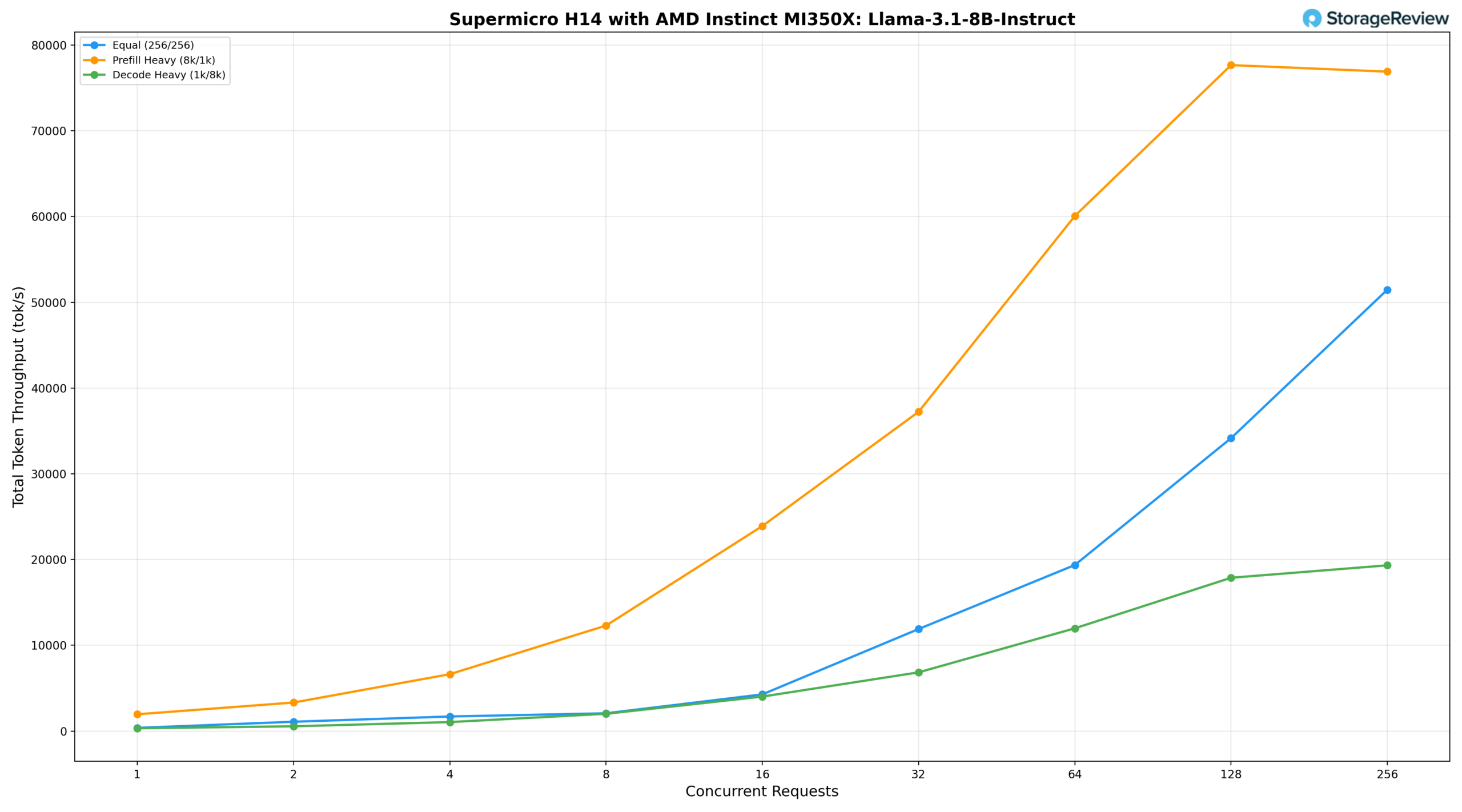
Llama 3.1 8B Instruct
For the Llama-3.1-8B-Instruct, we saw the equal workload (256/256) delivers 373.26 tok/s at BS=1, reaching 19,363.33 tok/s at BS=64, 34,155.70 tok/s at BS=128, and peaking at 51,467.30 tok/s at BS=256. Prefill-heavy (8k/1k) starts at 1,959.04 tok/s, climbs to 37,227.63 tok/s at BS=32 and 60,062.40 tok/s at BS=64, peaking at 77,658.50 tok/s at BS=128 before tailing off slightly to 76,893.77 tok/s at BS=256. Decode-heavy (1k/8k) starts at 326.48 tok/s, reaching 17,877.52 tok/s at BS=128 and 19,326.35 tok/s at BS=256, maintaining lower per-token latency further into the concurrency range than any of the larger models tested.
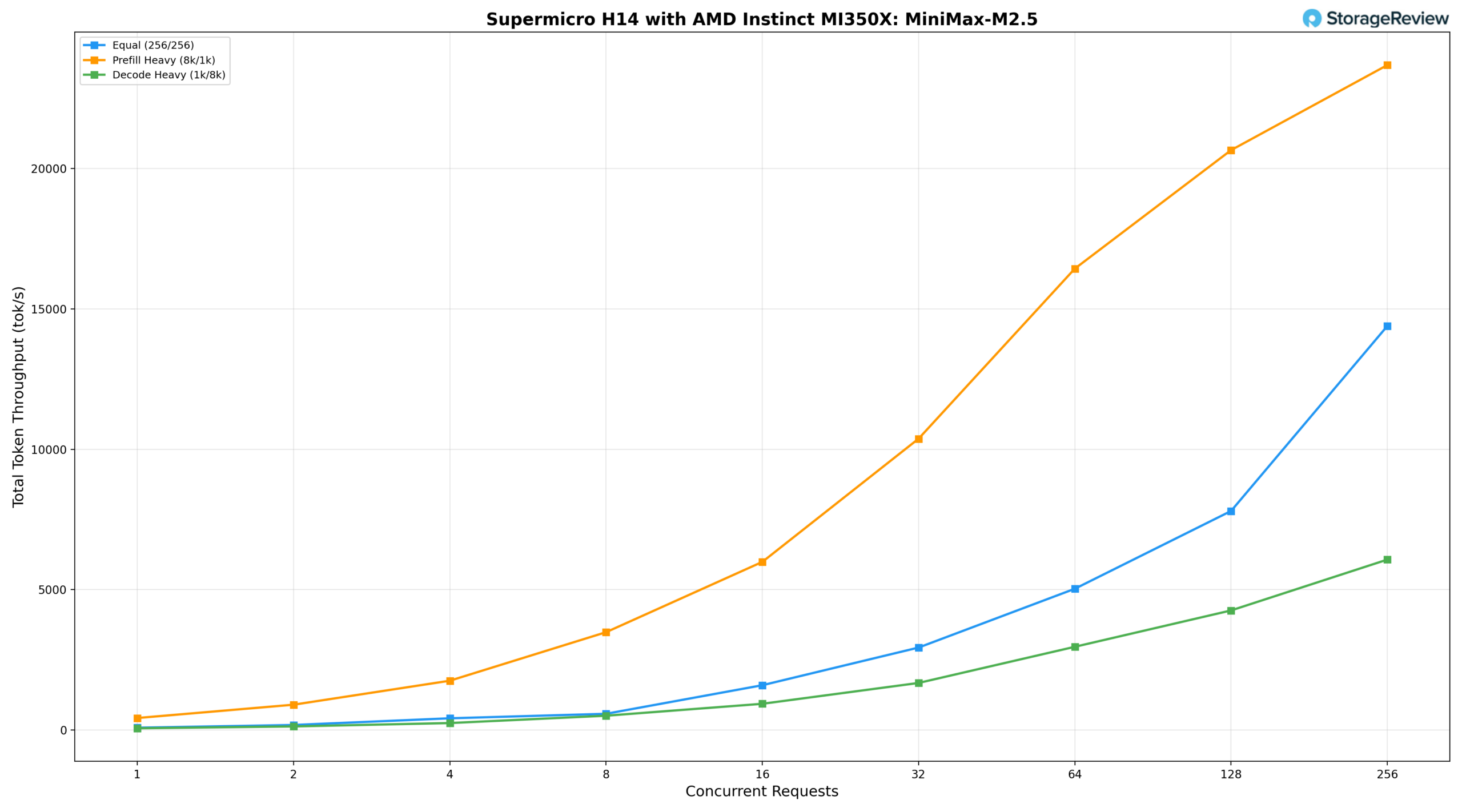
MiniMax M2.5
The MiniMax-M2.5 on the H14 rounds out the model lineup, sitting between the Kimi K2.5 and the mid-sized models in terms of throughput profile, with characteristics that reflect its mixture-of-experts architecture. The equal workload (256/256) delivers 79.31 tok/s at BS=1, reaching 5,029.76 tok/s at BS=64, 7,801.10 tok/s at BS=128, and 14,391.98 tok/s at BS=256. Prefill-heavy (8k/1k) shows the strongest scaling of the three scenarios, starting at 424.41 tok/s and climbing to 10,376.75 tok/s at BS=32 and 20,658.57 tok/s at BS=128, peaking at 23,689.18 tok/s at BS=256. Decode-heavy (1k/8k) scales steadily to 4,257.68 tok/s at BS=128 and 6,068.70 tok/s at BS=256, offering the most consistent latency growth across the full concurrency range.
Kimi K2.5
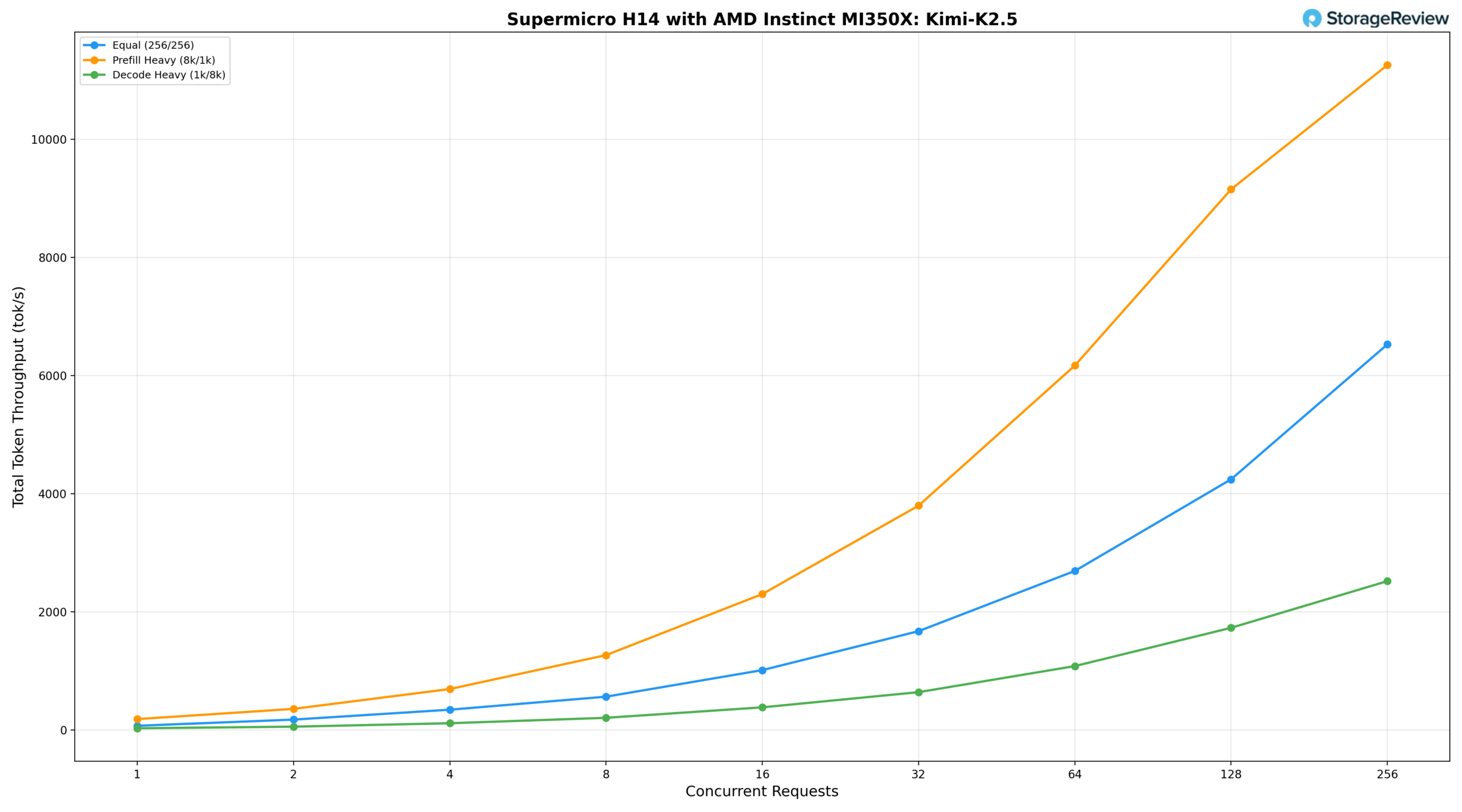
The Kimi K2.5 1-trillion-parameter model on the H14 is the largest and smartest model tested in this review, and its throughput reflects that weight.
The equal workload (256/256) delivers 72.06 tok/s at BS=1, reaching 2,693.07 tok/s at BS=64, 4,244.27 tok/s at BS=128, and peaking at 6,527.62 tok/s at BS=256. Prefill-heavy (8k/1k) scales more aggressively, starting at 185.29 tok/s and reaching 3,798.85 tok/s at BS=32 and 9,153.12 tok/s at BS=128, with peak throughput of 11,256.69 tok/s at BS=256. The step increase from BS=128 to BS=256 carries a significant latency cost, indicating the system is approaching its memory and compute limits at full batch depth for this model size. Decode-heavy (1k/8k) grows from 29.88 tok/s at BS=1 to 2,513.85 tok/s at BS=256, delivering the tightest scaling curve of the three scenarios while demonstrating consistent throughput gains across the full range.
Conclusion
The AMD Instinct MI350X delivers very competitive inference performance across the workload profiles tested here, and the Supermicro AS-8126GS-TNMR provides a well-engineered platform to take advantage of it. With 288GB of HBM3e per accelerator and eight GPUs interconnected over Infinity Fabric, the 2.3TB of aggregate GPU memory available in a single node is sufficient to serve trillion-parameter models like Kimi K2.5 and MiniMax M2.5 without requiring multi-node distribution or model-partitioning workarounds. This capability materially simplifies deployment architecture for large-scale inference.
Smaller models also delivered strong results. Llama 3.1 8B exceeded 77,000 tok/s under prefill-heavy workloads, and mid-range architectures such as Mistral Small 3.1 24B and Qwen3 Coder 30B sustained high throughput with well-controlled latency across the concurrency range. Across the board, the results indicate a hardware platform that scales predictably under load rather than falling off a cliff at higher batch depths.

ROCm 7.2 brings significant improvements to the AMD inference software stack, particularly when paired with vLLM 0.18. This pairing delivers a noticeably more stable and higher-performing serving experience than prior ROCm generations, with broader framework support and fewer of the rough edges that characterized earlier Instinct deployments. The ecosystem momentum around AMD hardware is also worth noting: upstream vLLM now maintains a dedicated AMD ROCm CI pipeline, and Meta’s multi-generation deployment commitment at the 6-gigawatt scale reinforces that production validation extends well beyond controlled benchmarking environments.
The Claude Code serving evaluation adds a practical lens to the raw throughput numbers. A single MI350X node sustained near-cloud-baseline response speeds for up to 16 concurrent coding sessions and remained interactive with up to 64 simultaneous users while producing nearly 1,000 tok/s of aggregate output. For organizations weighing the cost of commercial API subscriptions against self-hosted infrastructure, the economics become straightforward at that density, with additional advantages in data locality, elimination of per-token costs, and unrestricted model selection.
Supermicro’s JumpStart program continues to earn its place in the infrastructure evaluation process. Bare-metal access to production hardware, with no provisioning overhead, allowed us to run real workloads under real-world conditions throughout the full test window. For teams conducting accelerator procurement evaluations, this level of hands-on access remains far more informative than spec sheet comparisons or curated vendor demonstrations.


 Amazon
Amazon