

IBM introduced a content-aware storage (CAS) architecture that integrates AI data processing directly into the storage layer. The approach targets retrieval-augmented generation (RAG) workflows by embedding document vectorization within the storage system, reducing the need for external preprocessing pipelines.
CAS shifts a core RAG function, document embedding using large language model-based techniques, into storage infrastructure. This enables enterprises to process and index data in place, aligning storage systems with AI-driven workloads and reducing data movement across infrastructure tiers. IBM positions this as a way to simplify deployment while improving performance and data locality for AI applications.
Vector Database at Scale
At the center of IBM’s CAS implementation is a vector database optimized for semantic search. Vector databases support approximate nearest-neighbor search, enabling AI systems to retrieve relevant data chunks based on similarity metrics such as cosine similarity or L2 distance. This capability is foundational to RAG, where user queries are converted into vectors and matched against indexed enterprise data to provide context-aware responses.
Source: IBM
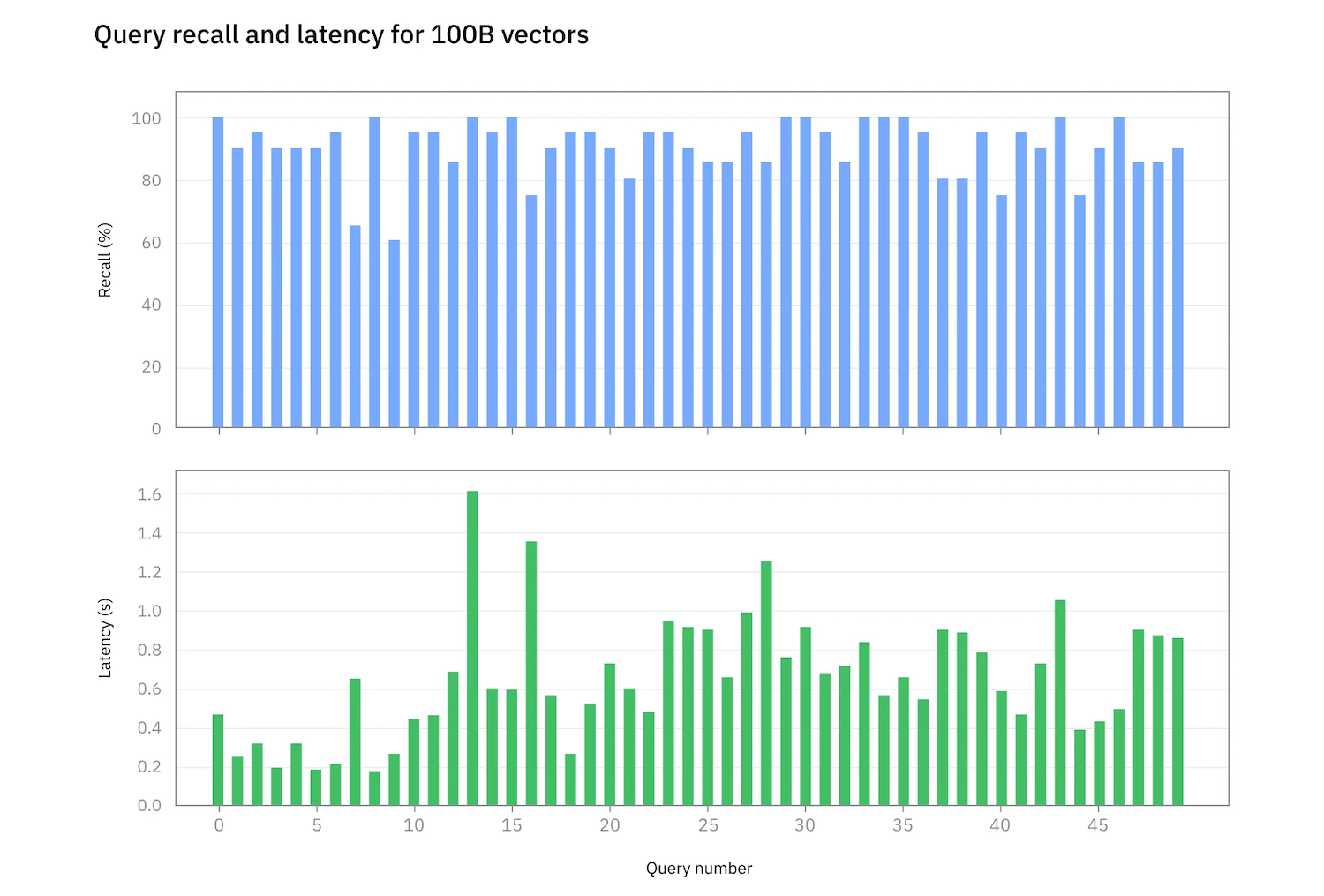
IBM Research, working with Samsung and NVIDIA, demonstrated a prototype system capable of scaling to 100 billion vectors on a single server. The system achieved over 90 percent recall and precision, with an average query latency under 700 milliseconds. This scale targets enterprise environments where datasets can span billions of files and, once fully indexed, reach hundreds of billions of vectors.
RAG Pipeline Integration
RAG is emerging as a preferred approach for enterprise AI because it improves output accuracy without requiring model retraining. It operates by augmenting prompts with enterprise-specific data retrieved from a vector database.
The pipeline begins with data ingestion, where documents such as PDFs and presentations are parsed, chunked, and converted into embeddings. These embeddings are stored in a vector database that organizes data for efficient similarity search. During query time, user input is embedded and matched against stored vectors, with relevant content passed to the language model as context. This grounding mechanism reduces hallucinations and improves trust in AI-generated outputs.
IBM’s CAS integrates this pipeline directly into storage, consolidating ingestion, indexing, and retrieval closer to the data.
Addressing Scale and Cost Challenges
Enterprise storage systems already operate at the petabyte scale. When extended to CAS, each file can generate hundreds of vectors, rapidly increasing the dataset size. Traditional vector databases typically scale out across multiple servers, introducing cost and operational complexity. Indexing and reindexing large datasets also become time-intensive.
IBM’s approach focuses on improving vector density and reducing indexing overhead to limit infrastructure sprawl. The architecture decouples vector and index storage from query compute, allowing independent scaling of storage and compute resources. This is enabled by IBM Storage Scale and its high-performance parallel file system.
Storage and Hardware Architecture
The CAS implementation leverages the IBM Storage Scale System 6000 (ESS 6000), an all-flash platform designed for AI and high-performance workloads. The system supports up to 48 NVMe drives per 4U enclosure, with capacities ranging from 7 TB to 60 TB per drive. It integrates PCIe Gen5, 400 Gb InfiniBand, or 200 Gb Ethernet connectivity and delivers up to 340 GB/s read and 175 GB/s write throughput per node, with up to 7 million IOPS.
The platform also supports NVIDIA GPUDirect Storage, enabling direct data paths between storage and GPUs, as well as BlueField-3 DPUs for offloading network and data processing.
Samsung PM9D3a PCIe Gen5 NVMe SSDs provide high-throughput, high-density storage. Based on eighth-generation TLC V-NAND, these drives deliver up to 30.72 TB per device, with sequential read speeds up to 12 GB/s and write speeds up to 6.8 GB/s. The use of commercially available enterprise SSDs allows the architecture to scale using standard components.
Hierarchical Indexing and GPU Acceleration
To address indexing at scale, IBM developed a hierarchical indexing model comprising multiple sub-indexes that can be optimized independently. This structure allows incremental updates and localized reindexing without disrupting the entire dataset, improving both availability and operational efficiency.
GPU acceleration significantly reduces indexing time compared to CPU-only approaches. Tasks that would take hours on CPUs can be completed in minutes using NVIDIA GPUs. In testing, building indexes for 100 billion vectors took 4 days with 6 NVIDIA H200 GPUs, compared to an estimated 120 days on a dual-socket CPU system.
The full dataset, including vectors and indexes, consumed approximately 153 TiB of storage. Initial data loading and partitioning took nine days. The resulting system delivered an average query latency of 694ms with 90% recall, validated against brute-force ground-truth calculations.
Roadmap
IBM and NVIDIA continue to optimize the platform, focusing on reducing indexing and query latency. Current targets include indexing 100 billion or more vectors within a day, reducing data ingestion time from nine days to one day, and lowering query latency to the 50-100 millisecond range while maintaining 90 percent recall.
Integrating vector indexing into standard file systems aims to simplify deployment and lower barriers to enterprise AI adoption. By embedding RAG capabilities directly in storage, IBM is positioning CAS as a foundational layer for AI-enabled infrastructure.


 Amazon
Amazon