

At CES 2026, NVIDIA unveiled the Rubin platform, anchored by the Vera Rubin NVL72 rack-scale system. This is NVIDIA’s third-generation rack-scale architecture, combining six co-designed chips into a single unified system. The platform will be available from partners in the second half of 2026, with all six chips already back from fabrication and currently undergoing validation with real workloads.
Vera Rubin NVL72: Six Chips, One Unified System
The Vera Rubin NVL72 uses what NVIDIA calls “extreme co-design,” in which six distinct chips are developed together to function as a unified system.

Vera CPU: ARM Silicon Designed for AI Factories
The first chip showcased was the NVIDIA Vera CPU, as NVIDIA continues its investment in custom ARM silicon for AI workloads. Built on 88 custom Olympus ARM cores with full Armv9.2 compatibility, Vera is designed specifically for the data movement and agentic processing demands of modern AI factories. It features NVLink-C2C connectivity, delivering 1.8 TB/s bandwidth to Rubin GPUs, doubling the C2C bandwidth over previous generations, and running seven times faster than PCIe Gen 6. The Vera CPU doubles the performance of data processing, compression, and code compilation compared to the previous-generation Grace CPU.

Generational Comparison: Blackwell Ultra vs. Vera Rubin NVL72
| Specification | GB300 NVL72 (Blackwell Ultra) | VR NVL72 (Vera Rubin) |
|---|---|---|
| GPU Count | 72 Blackwell Ultra GPUs | 72 Rubin GPUs |
| CPU Count | 36 Grace CPUs | 36 Vera CPUs |
| CPU Cores | 72 ARM cores per CPU | 88 Olympus ARM cores per CPU |
| FP4 Inference Performance | 1.44 ExaFLOPS | 3.6 ExaFLOPS |
| NVFP4 per GPU (Inference) | 20 PFLOPS | 50 PFLOPS |
| NVFP4 per GPU (Training) | 10 PFLOPS | 35 PFLOPS |
| GPU Memory Type | HBM3e | HBM4 |
| GPU Memory Bandwidth | ~8 TB/s | ~22 TB/s |
| NVLink Generation | NVLink 5 | NVLink 6 |
| NVLink Bandwidth (per GPU) | 1.8 TB/s | 3.6 TB/s |
| Rack-Scale NVLink Bandwidth | 130 TB/s | 260 TB/s |
| Scale-Out NIC | ConnectX-8 (800 Gb/s) | ConnectX-9 (1.6 TB/s) |
| CPU-GPU Interconnect | NVLink-C2C (900 GB/s) | NVLink-C2C (1.8 TB/s) |
Rubin GPU: Transformer Engines, NVFP4, and HBM4
Next up was the star of the show, NVIDIA Rubin GPU, which features a third-generation Transformer Engine with hardware-accelerated adaptive compression. This dynamically adjusts precision across transformer layers, achieving higher throughput where precision can be reduced while maintaining accuracy where it matters. This NVFP4 implementation delivers 50 petaflops of compute for inference (5x Blackwell) and 35 petaflops for training (3.5x Blackwell). The Rubin GPU is the first to integrate HBM4 memory with bandwidth up to 22 TB/s, a significant jump that addresses the memory bandwidth wall facing large MoE models.

NVLink 6: Rack-Scale All-to-All Communication
The NVIDIA NVLink 6 Switch doubles the per-GPU bandwidth to 3.6 TB/s, with the full rack providing 260 TB/s of scale-up networking—more than twice the cross-sectional bandwidth of the global internet. This scale-up fabric enables every GPU to communicate with every other GPU simultaneously (a requirement for MoE expert parallelism), where all experts must share results across the cluster. Built-in in-network compute accelerates collective operations and reduces congestion, offloading work that would otherwise consume GPU cycles.

ConnectX-9 SuperNIC: Redefining Scale-Out Networking
The NVIDIA ConnectX-9 SuperNIC handles scale-out networking, delivering 1.6 TB/s of RDMA bandwidth per GPU for communication beyond the rack. ConnectX-9 was co-designed with the Vera CPU to maximize data-path efficiency and introduces a fully software-defined, programmable, accelerated data path that enables AI labs to implement custom data-movement algorithms optimized for their specific model architectures.

BlueField-4 DPU and ASTRA Secure Architecture
BlueField-4 is NVIDIA’s fourth-generation data processing unit and represents a fundamental rethinking of storage and networking for AI workloads. The new DPU features a 64-core NVIDIA-grade CPU compared to BlueField-3’s 16 ARM Cortex-A78 cores, delivering 6x more compute performance. It includes a co-packaged ConnectX-9 SuperNIC versus ConnectX-7 in BlueField-3, doubling network bandwidth to 800 Gb/s. GPU access to data storage is 2x faster than the previous generation. Beyond the spec improvements, BlueField-4’s significance lies in what it enables: a new tier of AI-native storage infrastructure that NVIDIA is positioning as essential for agentic AI at scale.

BlueField-4 offloads networking, storage, and security processing so that Rubin GPUs and Vera CPUs remain focused on model execution. It is fully integrated into the NVIDIA Enterprise AI Factory validated design, with ecosystem support from Red Hat, Palo Alto Networks, Fortinet, and others.
BlueField-4 also introduces ASTRA (Advanced Secure Trusted Resource Architecture). This system-level trust architecture provides a single control point for securely provisioning, isolating, and operating large-scale AI environments without compromising performance.
Confidential Computing Across the Entire Rack
Vera Rubin NVL72 is the first rack-scale platform to deliver NVIDIA Confidential Computing across the entire system. Third-generation confidential computing maintains data security across CPU, GPU, and the entire NVLink domain, with every bus encrypted in transit. This addresses a growing concern among enterprises and AI labs running proprietary models on shared infrastructure: the ability to guarantee that models, training data, and inference workloads remain protected even when deployed on third-party systems.
The NVIDIA Spectrum-6 Ethernet Switch powers Nvidia’s scale-out networks. It is built on 200G SerDes technology with co-packaged optics (CPO), achieving 102 TB/s switching capacity and powering east-west traffic across VR NVL72 racks. The move to CPO is significant. By integrating optics directly with the switch silicon, NVIDIA claims 10x greater reliability, 5x longer uptime, and 5x better power efficiency compared to traditional pluggable optics.

Cost and Efficiency Improvements for MoE Models
NVIDIA states that the VR NVL72 delivers one-seventh the token cost for large Mixture-of-Experts model inference at the same latency as Blackwell. It requires only one-fourth as many GPUs to train the same large MoE model in the same amount of time. The platform achieves 8x the inference compute per watt.
These improvements address the requirements of MoE models, which activate only a subset of their experts for any given token. Models like Kimi K2 Thinking employ 384 experts but activate only eight at a time, requiring massive all-to-all GPU communication. The VR NVL72’s 260 TB/s of scale-up networking handles this communication pattern.
A Cable-Free Rack Designed for Massive Scale
The VR NVL72 introduces a modular, cable-free, fan-free, and hose-free tray design that uses only PCBs and connectors, rather than internal cabling. The compute trays connect via blind-mate connectors when inserted into the rack, eliminating the need for manual cable routing. The only external connections are two liquid inlet and outlet hoses that connect to the liquid cooling blocks.

Previous systems, such as the GB300 NVL72, required approximately 100 minutes to assemble a single compute tray. Each cable connection was a potential failure point, which becomes significant at the scale of hundreds of thousands of GPUs. Cable routing constrained cooling pathways and consumed space, while fans added mechanical complexity and noise.

The new design reduces assembly and servicing time by 18x. The platform also features a second-generation RAS (Reliability, Availability, Serviceability) engine spanning GPU, CPU, and NVLink, providing real-time health checks, fault tolerance, and proactive maintenance. NVLink switch trays now support zero-downtime maintenance, allowing racks to remain operational while switch trays are removed or partially populated. At the scale of hundreds of thousands of GPUs, these serviceability improvements translate directly to cluster uptime and goodput.
This architecture enables future higher-density configurations. This is also key to allowing the previously teased Vera Rubin CPX rack designs we covered at the AI Infra Summit, which further add Context Processing GPUs to the same compute sled in an already dense design.
Inference Context Memory Storage Platform
NVIDIA announced the Inference Context Memory Storage Platform at CES 2026, a new class of AI-native storage infrastructure built specifically for KV cache. The platform is powered by BlueField-4 and Spectrum-X Ethernet networking. It delivers up to 5x higher tokens per second than traditional network storage used for inference context, up to 5x better performance per TCO dollar, up to 5x better power efficiency, and a 20x improvement in time-to-first-token. BlueField-4’s hardware-accelerated KV cache placement eliminates metadata overhead and reduces data movement, while Spectrum-X Ethernet provides the high-bandwidth, low-latency fabric for RDMA-based access.

This platform addresses a growing bottleneck in LLM inference: KV cache management. Transformer models use an attention mechanism where each generated token must attend to all previous tokens. Without caching, this requires recomputing key and value vectors for every token, resulting in O(n²) complexity. KV caching stores these precomputed matrices in memory for reuse, reducing complexity to O(n). The problem is that the KV cache size grows linearly with sequence length and batch size. A single long-context conversation can consume gigabytes of memory. In multi-tenant environments, handling thousands of concurrent requests across context windows that extend to millions of tokens, GPU HBM becomes exhausted. Operators must either reduce batch sizes, shorten context windows, or purchase more GPUs.
Traditional network storage was not designed for KV cache access patterns, which require low-latency random access to potentially terabytes of transient data spread across many concurrent sessions. The Inference Context Memory Storage Platform provides a dedicated storage tier optimized for this workload, sitting between GPU HBM and conventional storage. This allows AI factories to scale context capacity independently from GPU compute. We previously covered how KV cache offloading works with NVIDIA Dynamo using a KV Cache accelerator from Pliops. NVIDIA scales it up with the NVIDIA Inference Context Memory Storage Platform and ties it into their open-source Dynamo project. This provides the software framework that ties together the disaggregated prefill/decode phases, smart routing, and tiered storage offloading of this new platform.
Storage partners, including VAST Data, NetApp, DDN, Dell Technologies, HPE, Hitachi Vantara, IBM, Nutanix, Pure Storage, and WEKA, are building platforms with BlueField-4. These will be available in the second half of 2026.
Alpamayo: Reasoning-Based Physical AI for Autonomous Vehicles
NVIDIA announced the Alpamayo family of open AI models, simulation tools, and datasets designed to accelerate safe, reasoning-based autonomous vehicle (AV) development. The Alpamayo family introduces chain-of-thought, reasoning-based vision-language-action models that bring human-like thinking to AV decision-making. The NVIDIA Halo safety system underpins these systems.
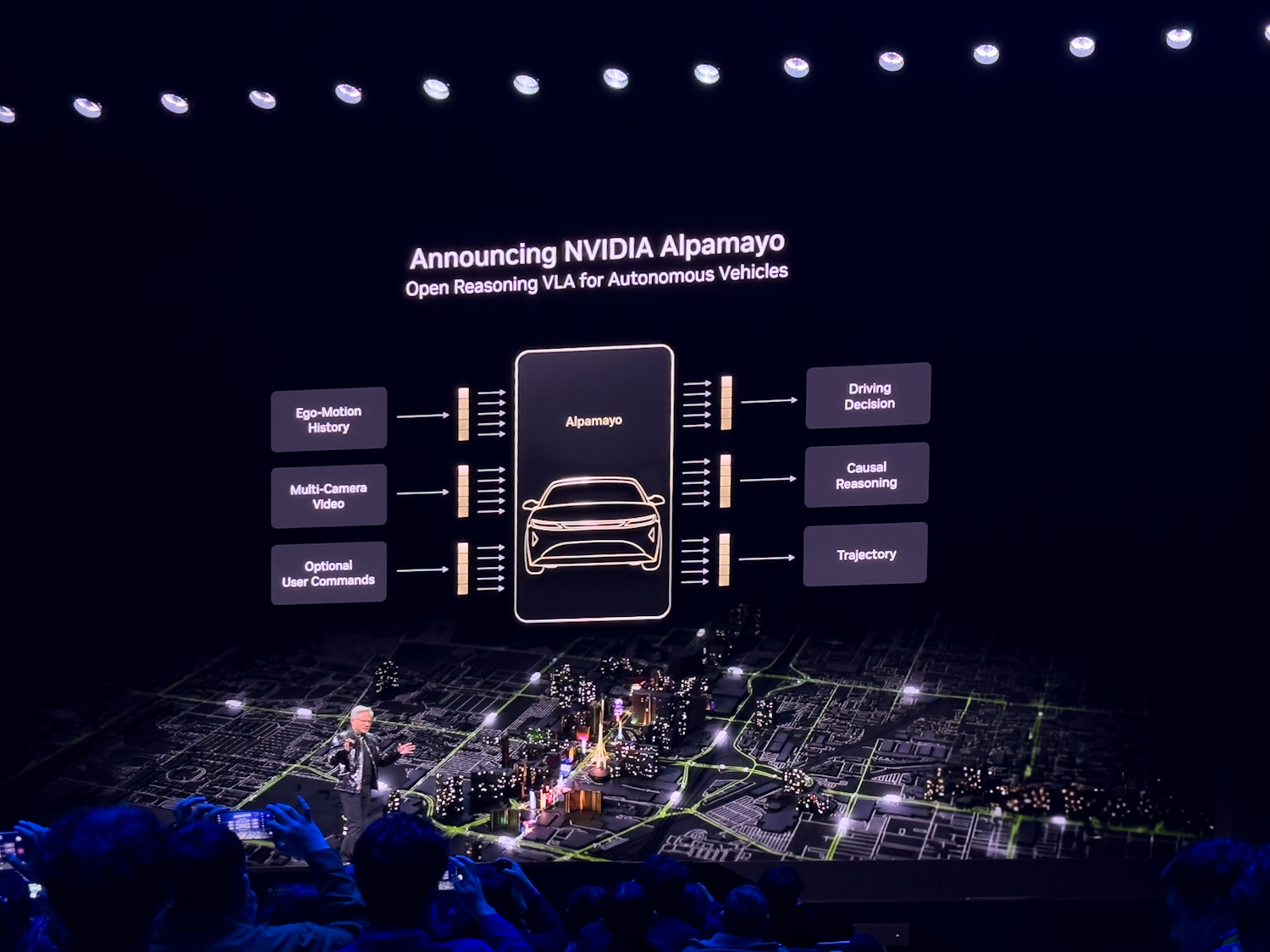
Traditional AV architectures separate perception and planning, which can limit scalability when new or unusual situations arise. The “long tail” of rare, complex scenarios remains one of the toughest challenges for autonomous systems to master safely. Alpamayo addresses this by enabling models to reason about cause and effect, thinking through novel scenarios step by step to improve driving capability and explainability.
Rather than running directly in-vehicle, Alpamayo models serve as large-scale teacher models that developers can fine-tune and distill into the backbones of their complete AV stacks. Developers can adapt Alpamayo into smaller runtime models for vehicle development, or use it as a foundation for AV development tools such as reasoning-based evaluators and auto-labeling systems.
Alpamayo Models, Simulation, and Open Datasets
Alpamayo 1 is the industry’s first chain-of-thought reasoning VLA model designed for the AV research community, available on Hugging Face. With a 10-billion-parameter architecture, Alpamayo 1 uses video input to generate trajectories alongside reasoning traces, showing the logic behind each decision. Alpamayo 1 provides open-source model weights and inference scripts. Future models in the family will feature higher parameter counts, more detailed reasoning capabilities, greater input and output flexibility, and options for commercial use.
AlpaSim is a fully open-source, end-to-end simulation framework for high-fidelity AV development, available on GitHub. It provides realistic sensor modeling, configurable traffic dynamics, and scalable closed-loop testing environments, enabling rapid validation and policy refinement.
Physical AI Open Datasets contain 1,700+ hours of driving data collected across the broadest range of geographies and conditions, covering rare and complex real-world edge cases essential for advancing reasoning architectures. These datasets are available on Hugging Face.
Developers can fine-tune Alpamayo model releases on proprietary fleet data, integrate them into the NVIDIA DRIVE Hyperion architecture built with NVIDIA DRIVE AGX Thor accelerated compute, and validate performance in simulation before commercial deployment.
NVIDIA DRIVE, Redundant AV Stacks, and Mercedes-Benz CLA
NVIDIA has been working on self-driving cars for eight years with a team of several thousand people. The company built the full stack: chips (dual Orins, next-generation dual Thors), infrastructure (Omniverse and Cosmos), models (Alpamayo), and the application layer. Mercedes-Benz partnered with NVIDIA five years ago to deploy this stack.
The first NVIDIA full-stack autonomous vehicle, the Mercedes-Benz CLA, launches in Q1 2026 in the United States, Q2 in Europe, and Q3/Q4 in Asia. Euro NCAP rated the CLA with the highest active safety score of any car submitted in 2025. Every line of code and every chip in the system is safety-certified.

The system runs two complete AV stacks in parallel. The Alpamayo stack uses chain-of-thought reasoning and handles complex driving scenarios. A second classical AV stack underneath is fully traceable and took six to seven years to build. A policy and safety evaluator decides which stack to use based on confidence level. If Alpamayo encounters a scenario where it is not confident, the system falls back to the classical stack. This diversity and redundancy in the software mirrors how safety-critical systems handle hardware redundancy.
NVIDIA will continue updating the system with new versions of Alpamayo. Mobility partners, including JLR, Lucid, Uber, and Berkeley DeepDrive, are using Alpamayo for the development of reasoning-based level 4 autonomy.
New Physical AI Models and Robotics Announcements
Alongside its infrastructure and systems announcements, NVIDIA also used CES 2026 to advance its Physical AI strategy by releasing new open models, frameworks, and edge platforms to accelerate robotics development. The company introduced updates to its Cosmos world models and GR00T reasoning models for robot learning, along with new open-source tooling (including Isaac Lab-Arena), for large-scale robot evaluation. OSMO is an edge-to-cloud orchestration framework designed to simplify training workflows across heterogeneous compute environments.

NVIDIA highlighted broad industry adoption of its robotics stack, with partners including Boston Dynamics, Caterpillar, LG Electronics, and NEURA Robotics, showcasing next-generation autonomous machines built on NVIDIA technologies. The company also announced tighter collaboration with Hugging Face to integrate NVIDIA Isaac and GR00T models into the open-source LeRobot framework, further expanding access for the global robotics developer community.
At the edge, NVIDIA confirmed availability of the Blackwell-powered Jetson T4000 module, delivering a significant increase in AI compute and energy efficiency for autonomous machines and industrial robotics. Together, these announcements reinforce NVIDIA’s push to extend its full-stack AI platform beyond the data center, spanning simulation, models, edge compute, and real-world deployment across robotics and autonomous systems.


 Amazon
Amazon