
Supermicro Data Center Building Block Solutions (DCBBS) delivers end-to-end solutions from the rack to the row to the site.
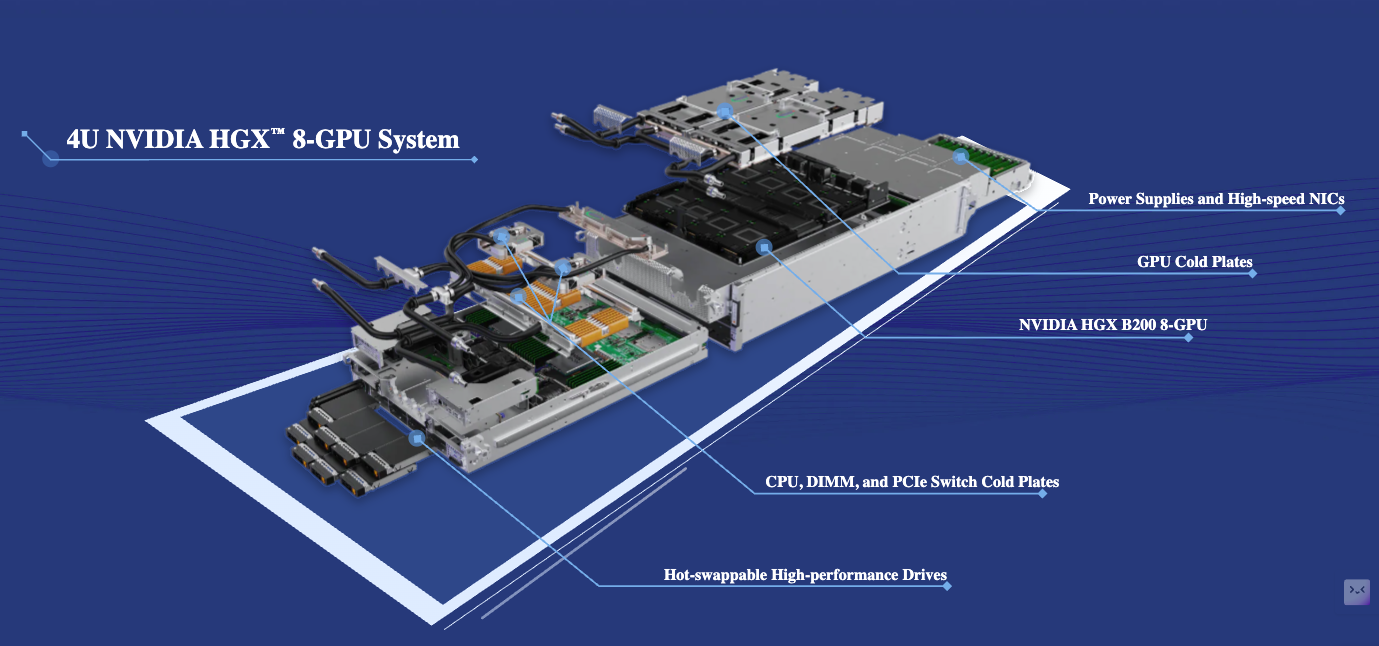

Supermicro Data Center Building Block Solutions (DCBBS) delivers end-to-end solutions from the rack to the row to the site.

Dell adds significant updates to the AI Data Platform, designed to help customers change distributed, siloed data into fast, repeatable AI outcomes.

Micron’s 192GB SOCAMM2 LPDDR5X module boosts AI data center performance with higher bandwidth, lower power use, and a compact design.

Waterless cooling has been redefined for AI with a turnkey server and cold plate, thanks to the collaboration between ZutaCore and ASRock Rack on B300 clusters.

NVIDIA previews Vera Rubin NVL144, an MGX-generation open-architecture rack server.

AMD and IBM collaborate to deliver advanced AI infrastructure to open-source AI research company Zyphra.
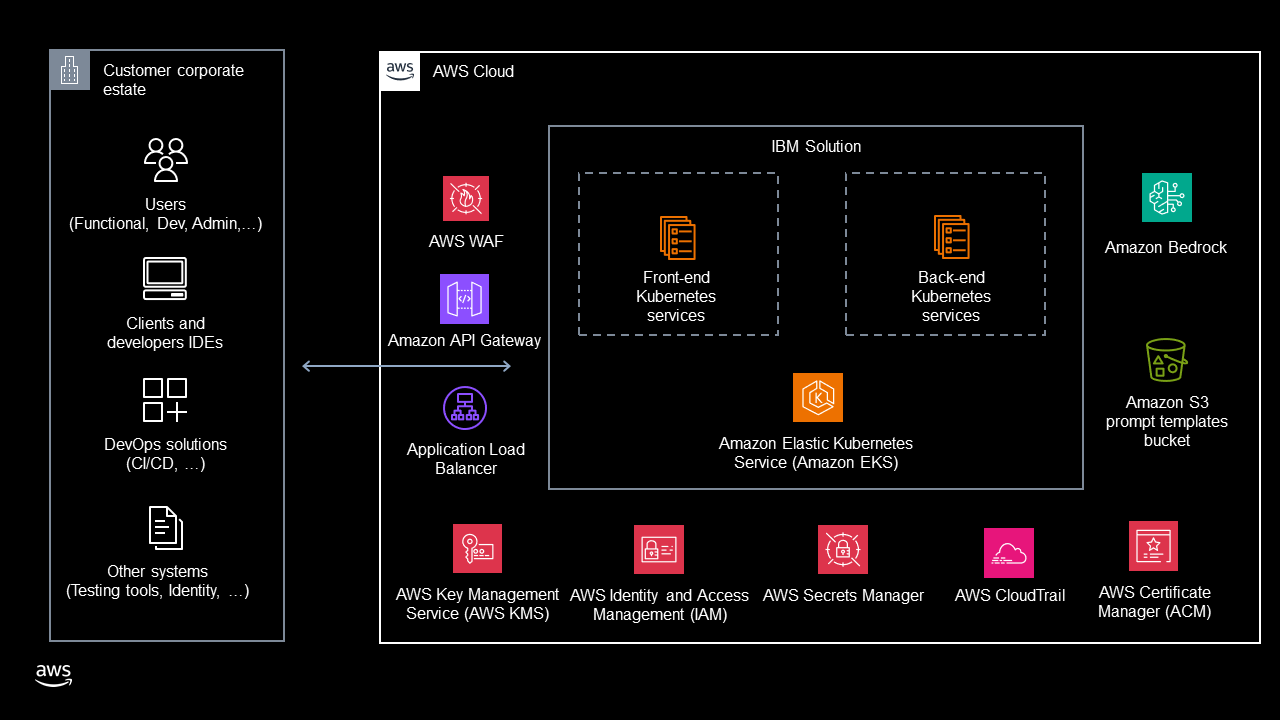
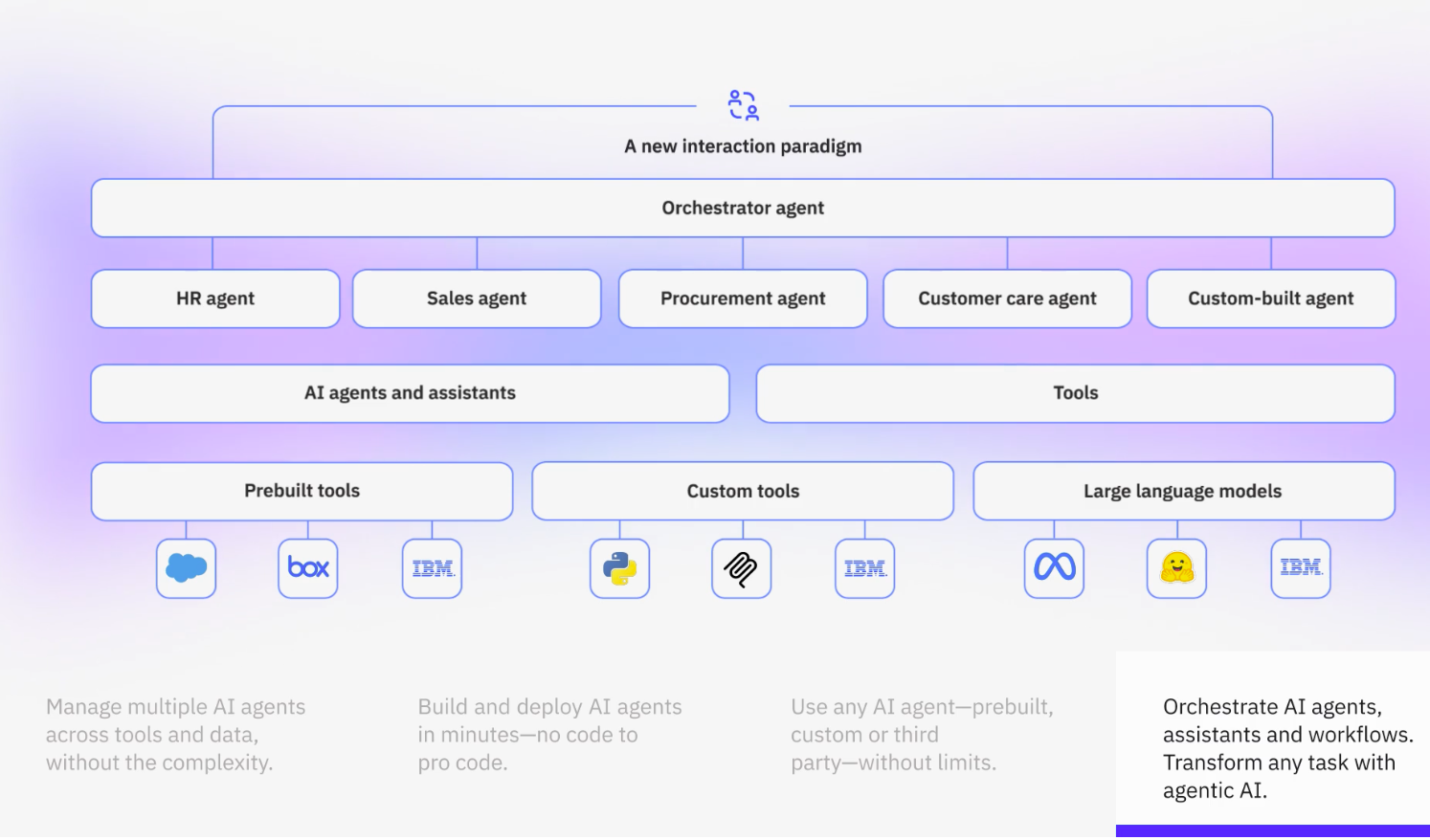
IBM announces updates across agentic AI orchestration, hybrid/multi-cloud observability, mainframe operations, and AI-first developer tooling.
The IBM and Anthropic partnership will integrate Claude into select internal and external development tools and enterprise products.

IBM Granite 4.0 ushers in open-weight language models that run faster, are more cost-effective, and include increased governance.

Fujitsu and NVIDIA collaborate to co-develop a full-stack AI infrastructure to advance enterprise-scale deployment.


 Amazon
Amazon