

MinIO has announced MemKV, a context memory store designed to address a growing bottleneck in large-scale AI inference environments. Positioned as the second core component of the company’s portfolio alongside AIStor, MemKV extends MinIO’s data infrastructure into the memory tier, targeting persistent, shared context for agentic AI workloads operating across GPU clusters.
As AI systems evolve from single-response interactions to multi-step reasoning and task execution, maintaining context across inference cycles has become critical. In current architectures, context is frequently lost due to limited capacity in GPU-adjacent memory tiers such as HBM and DRAM. This forces GPUs to recompute previously generated context, increasing latency, compute utilization, and energy consumption. MinIO characterizes this as a recompute tax that compounds at scale, particularly in hyperscale and cloud environments.
MemKV is designed to mitigate this issue by providing a shared, persistent memory layer capable of microsecond retrieval at the petabyte scale. By maintaining context across inference operations, the platform reduces redundant computation and improves overall system efficiency. In internal benchmarks, MinIO reports improvements in time-to-first-token at production concurrency levels. In a representative deployment with 128 GPUs and 128K-token context windows, GPU utilization increased from about 50 percent to over 90 percent, resulting in significant annual compute cost savings.
MinIO’s leadership noted that recompute overhead has historically been masked in smaller deployments but becomes a structural inefficiency at scale. As GPU clusters grow, the cost of repeatedly regenerating context rises in both power consumption and infrastructure requirements, making purpose-built memory systems necessary for sustainable AI operations.
Addressing the Memory-Scale Tradeoff
Traditional AI infrastructure forces a tradeoff between speed and scale. High-performance memory tiers such as HBM and DRAM provide microsecond latency but are capacity-constrained and expensive. Conversely, storage systems offer scale but introduce millisecond latency, which is unsuitable for real-time inference and long-context reasoning.

MemKV is designed to bridge this gap by introducing a shared memory tier that combines low-latency access with large-scale capacity. Built to run on NVIDIA BlueField-4 STX and integrated with NVIDIA Dynamo and NIXL, the platform enables an entire GPU cluster to access a common pool of context data at speeds aligned with inference requirements. This approach eliminates the need to shuttle context between disparate memory and storage layers, reducing latency and improving throughput.

Architecture Optimized for Inference Workloads
MemKV is purpose-built for the inference data path and aligns with MinIO’s description of the G3.5 layer in the GPU memory hierarchy. It delivers petabyte-scale capacity on NVMe-based infrastructure while maintaining microsecond-level access characteristics, effectively decoupling memory scale from GPU compute resources.
The system avoids traditional storage abstractions by moving data directly from NVMe into the AI data path via end-to-end RDMA transport. This eliminates overhead from HTTP protocols, file-system translation, and intermediary storage servers, which are common in object- and file-based architectures.
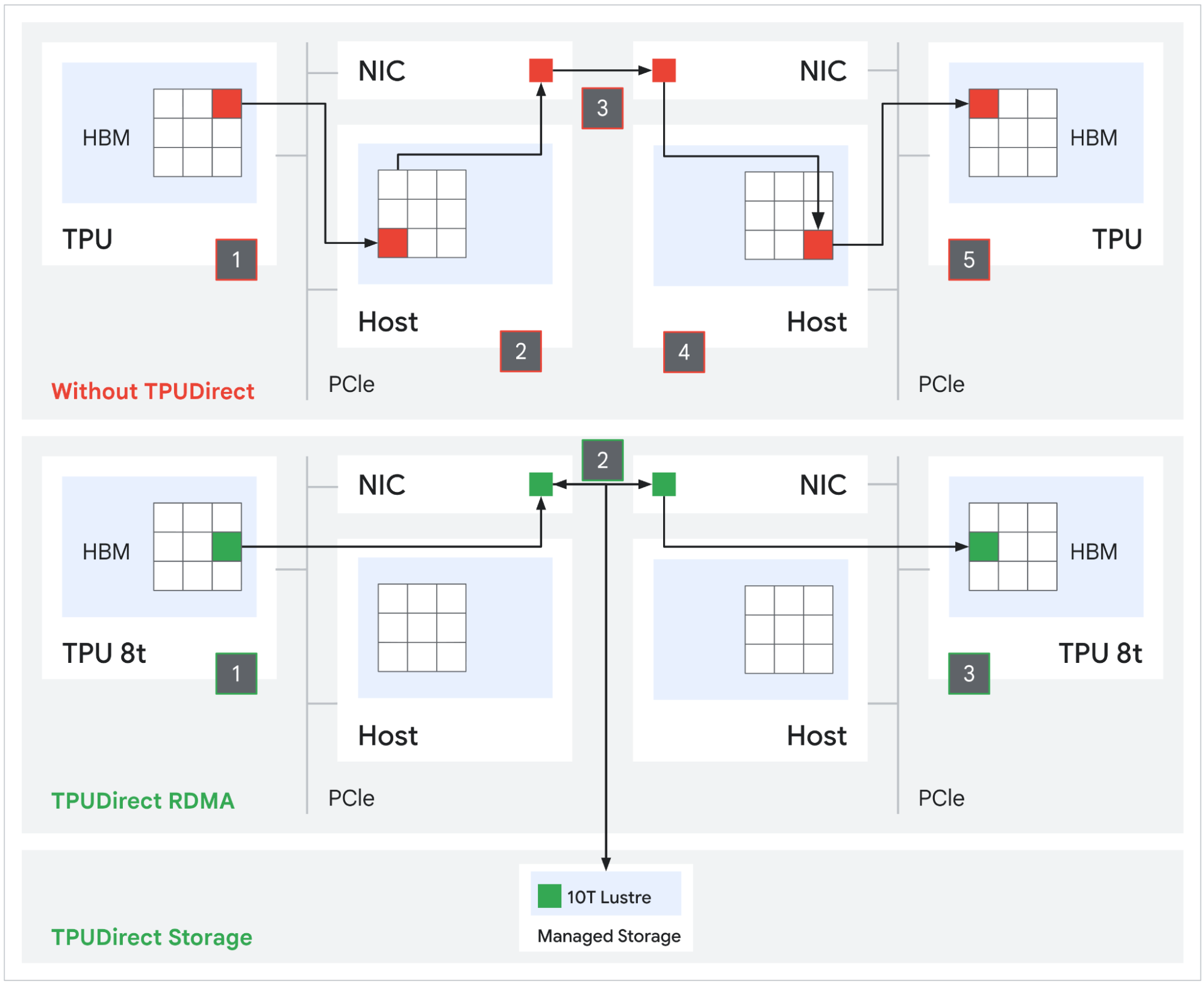
Source: Google
Key architectural elements include native execution on NVIDIA BlueField-4 STX as an ARM64 binary embedded in the storage layer, reducing reliance on external x86 storage nodes. Data transfers occur over RDMA from GPU memory to NVMe, bypassing conventional storage stacks. MemKV also uses larger block sizes, ranging from 2 MB to 16 MB, optimized for GPU throughput patterns rather than legacy 4 KB storage blocks. Networking performance is aligned with modern high-speed fabrics, including NVIDIA Spectrum-X Ethernet and PCIe Gen6, enabling near wire-speed data movement across the cluster.
Availability
MinIO MemKV is available immediately.


 Amazon
Amazon