

WEKA announced integration of its NeuralMesh platform with the NVIDIA STX reference architecture, positioning its Augmented Memory Grid as a core component for next-generation AI infrastructure. The combined solution targets one of the primary constraints in large-scale inference environments: memory limitations that impact performance, cost, and scalability.
Running on NeuralMesh, WEKA’s Augmented Memory Grid extends GPU memory by externalizing and persisting key-value cache. In NVIDIA STX deployments, this architecture supports high-throughput context memory storage for agentic AI workloads, enabling long-context reasoning across sessions, tools, and workflows. The company states that configurations leveraging NVIDIA Vera Rubin NVL72 systems, BlueField-4 DPUs, and Spectrum-X Ethernet can increase context memory token throughput by 4x to 10x. The platform is also expected to deliver at least 320 GB/s read and 150 GB/s write throughput, more than doubling the performance of conventional AI storage systems.

Memory Infrastructure Becomes the Inference Bottleneck
WEKA frames the integration around a growing constraint in AI deployments: the memory wall. In modern inference pipelines, limited high-bandwidth memory on GPUs leads to frequent KV cache evictions, resulting in recomputation and reduced efficiency. As concurrency increases, these inefficiencies compound, driving higher infrastructure costs and reducing system predictability.
The company advocates for shared KV cache infrastructure as a solution. By maintaining persistent context across users and sessions, shared cache eliminates redundant computation and stabilizes token throughput. NVIDIA STX provides a reference architecture for implementing this model, with WEKA supplying the storage and memory extension layer.
NeuralMesh and Augmented Memory Grid Architecture
NeuralMesh serves as WEKA’s distributed storage platform, designed to operate across the full NVIDIA STX stack. The system provides high-performance data services tailored for AI workloads, while the Augmented Memory Grid functions as a dedicated memory extension layer that pools KV cache outside GPU memory.
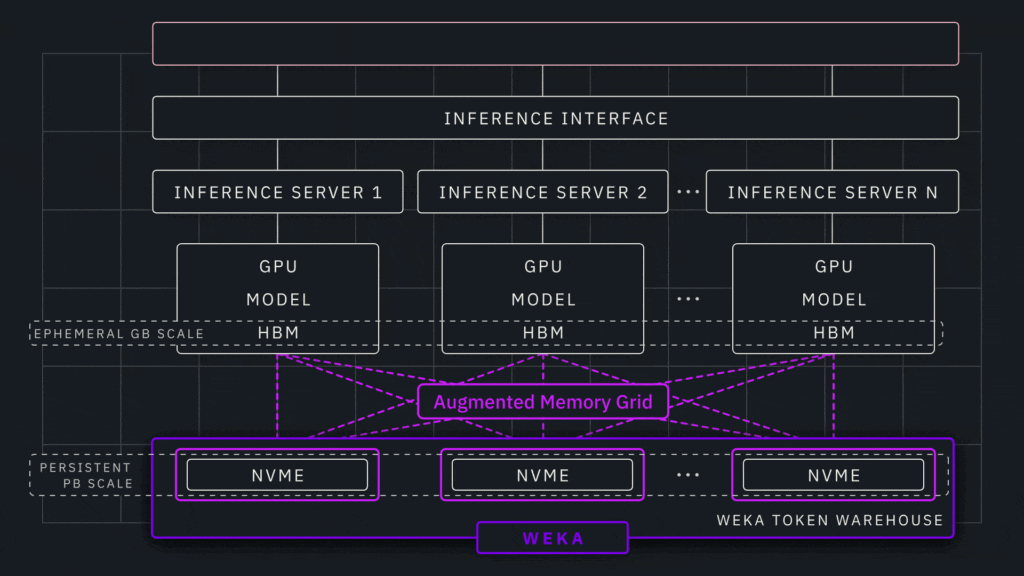
This approach allows inference environments to maintain long-context sessions without exhausting GPU resources. By preserving cache state and enabling reuse across workloads, the platform aims to sustain high utilization and consistent performance as deployments scale.
WEKA reports that Augmented Memory Grid, initially introduced at GTC 2025 and now generally available, has been validated on NVIDIA Grace CPU platforms with BlueField DPUs. The architecture delivers measurable improvements in inference efficiency, including significantly faster time-to-first-token, higher token throughput per GPU, and sustained performance as concurrency increases. Offloading the storage data path to BlueField-4 further reduces CPU overhead and minimizes I/O bottlenecks.
Performance and Efficiency Gains
In production-aligned environments, the platform is designed to improve responsiveness and infrastructure efficiency. WEKA indicates that Augmented Memory Grid can reduce time-to-first-token by up to 4x to 20x, while increasing token output per GPU by up to 6.5x. These gains are driven by higher KV cache hit rates and reduced recomputation, allowing systems to maintain performance as context windows and user counts grow.
Firmus, an AI infrastructure provider, is cited as an early adopter using NeuralMesh with NVIDIA-aligned infrastructure. The company reports improved token throughput and reduced latency at scale, attributing the gains to more efficient use of existing GPU resources rather than an expansion of the hardware footprint.
Implications for AI Infrastructure Design
The integration underscores a shift in AI system architecture, in which memory and storage design increasingly dictate overall performance and cost efficiency. As agentic AI workloads expand and context windows grow, DRAM-only approaches become less viable due to escalating recomputation overhead and underutilized GPUs.
WEKA positions persistent, shared KV cache as a foundational capability for AI factories. Organizations that adopt this model can maintain higher GPU utilization, reduce energy consumption per inference task, and achieve more predictable scaling characteristics. Conversely, environments that continue to rely solely on local GPU memory are likely to face increasing operational costs and diminishing returns as workloads scale.
Availability
WEKA’s Augmented Memory Grid is generally available as part of the NeuralMesh platform.


 Amazon
Amazon