

HPE has built a coordinated cyber resilience architecture around the Alletra Storage MP B10000. It extends the platform’s native security capabilities through an integrated stack that includes virtualization with Morpheus and VM Essentials, continuous data protection with Zerto, long-term backup retention with StoreOnce, and observability via vendor-agnostic security information and event management (SIEM) integration. Taken together, the architecture is designed to align directly with the NIST Cybersecurity Framework 2.0, with the B10000 serving as the operational center across every function of the framework. The whole design exists to answer the two questions a security practitioner will ultimately ask about any piece of infrastructure: Is it still under our control, and is the data on it still being protected?

Enterprise storage historically sits outside the broader security conversation. In most organizations, a chief information security officer who is worried about a misconfigured router in a branch office or an unpatched laptop on the corporate network pays little attention to the storage array in the data center. The array is behind layers of perimeter security, accessible to a small handful of administrators, and largely invisible to the broader IT organization. On paper, it is one of the safest assets in the building.
That assumption no longer holds. Modern ransomware operations have learned that the array is the highest-value target in the data center. Endpoints and servers can be reimaged. Primary storage is where the data actually lives, and an attacker who gains administrative control of the array can encrypt the data, delete the snapshots meant to recover it, and destroy the backups in a single coordinated motion. At that point, the organization is not dealing with an inconvenience; it is negotiating for its survival. The tools available to attackers, including AI-assisted variants that adapt faster than signature-based defenses can keep up with, are increasingly capable of reaching that target.
The stakes are no longer only operational. Regulators in the United States, the European Union, and the United Kingdom have moved infrastructure security from a best practice toward a legal obligation. Frameworks such as the EU’s Digital Operational Resilience Act and the NIS2 Directive require demonstrable controls for detection, recovery, and incident reporting, with accountability that extends to the executive level. The organizations carrying these obligations are exactly the ones running enterprise storage at scale: banks and financial services firms, hospitals and healthcare networks, utilities and critical infrastructure operators, government agencies, and the cloud and service providers that host all of the above. For them, failing to secure the infrastructure layer is not only a risk to the business but also a compliance failure with serious consequences.
The work of cyber resilience sits in the gap between storage and security teams that report to different leaders, measure success differently, and rarely share the operational language needed to coordinate during an incident. Storage administrators understand throughput, capacity, and recovery objectives. Security teams understand kill chains, attack vectors, and posture management. Most organizations discover the gap only after they have been forced to operate in it. The architecture HPE has assembled is designed to close that gap, and the sections that follow work through each NIST function to test how well it does, returning throughout to the two questions of control and protection.
Key Takeaways
- Full-stack resilience: HPE pairs the Alletra Storage MP B10000 with VM Essentials, Zerto, StoreOnce, and vendor-agnostic SIEM integration, mapping the coordinated stack to every NIST CSF 2.0 function.
- Fast block-level detection: The B10000’s built-in entropy-based ransomware engine, validated against 100+ strains, flagged a simulated encryption run in 4-5 minutes and auto-captured a forensic snapshot at the moment of detection.
- Immutability that survives admin compromise: Array-enforced Virtual Lock snapshots stay read-only through retention; even a compromised admin account can’t delete them, and any attempt becomes a logged, SIEM-visible event.
- Tiered recovery: Four tiers (Zerto for lowest RPO, VME snapshots, Virtual Lock promote, and StoreOnce Catalyst for long-term retention) were exercised in the lab, with clean restores from both Virtual Lock and Catalyst.
- Compliance-ready telemetry: Structured security syslog normalized to Elastic Common Schema feeds Elastic Security, CrowdStrike Falcon, or any modern SIEM, supporting DORA/NIS2 evidence and automated SOAR playbooks.
Architecture Overview
To provide a practical demonstration environment rather than an oversized enterprise deployment, the HPE team built out a compact but functional recovery and backup stack in their Fort Collins lab. At the center of the environment is a three-node HPE VM Essentials (VME) cluster running on HPE ProLiant DL325 Gen 11 Servers, which provides the compute layer for the demo infrastructure. These hosts are interconnected through the local IP network, which also provides connectivity to the NAS layer used within the environment.
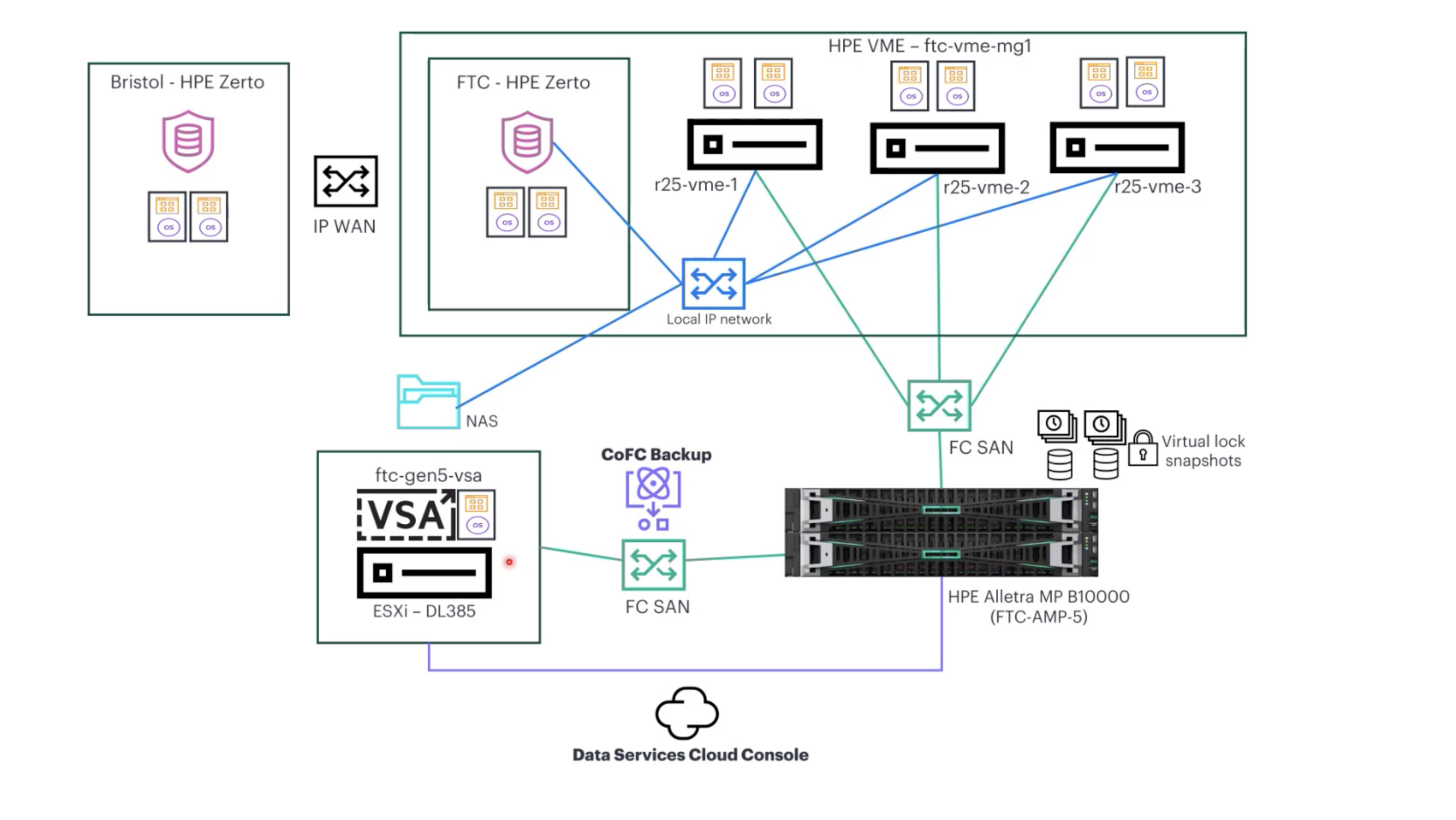
Running inside the VME cluster are the HPE Zerto virtual machines, configured similarly to how many organizations currently deploy Zerto in a traditional VMware environment. While the underlying infrastructure here uses HPE VME, the operational flow and recovery functionality remain familiar for administrators experienced with VMware-based disaster recovery workflows.

A WAN-connected secondary Zerto environment is available in the Bristol lab in the UK, with firewall rules and network paths in place to support replication from Fort Collins. The intent of this topology is multi-site recovery: continuous replication and disaster-recovery orchestration across geographically separated sites. This would allow workloads protected in Fort Collins to fail over to Bristol if the primary site became unavailable.
During this engagement, HPE ran Zerto replication locally in Fort Collins due to bandwidth and distance constraints, and because a second parallel VME cluster was not available to exercise the full cross-site flow. The Bristol leg is documented here as configured and available infrastructure, not as a cross-site failover performed in this session.

Storage connectivity in the environment is split between IP and Fibre Channel networking, depending on the workload. The FC SAN fabric connects the VME hosts directly to the HPE Alletra MP B10000 platform, providing shared access to enterprise storage across the cluster. The B10000 also presents Catalyst over Fibre Channel to the StoreOnce Virtual Storage Appliance (VSA), which is the path used for application-consistent backups between the array and the backup target. Virtual Lock snapshots play a central role in the ransomware resilience and immutability workflows on the platform and are exercised in detail in the Protect and Recover sections.

For backup infrastructure, HPE deployed a StoreOnce Gen5 VSA running on a single HPE server in the lab. The VSA exposes the same core StoreOnce functionality as the dedicated appliance. Deduplication, backup target presentation, replication behavior, and integration with the broader HPE data protection stack remain fundamentally the same whether deployed as a VSA or on dedicated hardware. The VSA is well-suited for labs, branch offices, testing environments, and smaller production use cases, making this compact demonstration practical to deploy.
The physical StoreOnce appliance carries an advantage that goes beyond scale and throughput, and it matters specifically in the ransomware context this paper examines. A VSA runs as a guest on a hypervisor. If an attacker compromises the virtualization layer, every workload on it, including a VSA backup target, is within reach. A physical StoreOnce appliance has no such dependency. It runs on dedicated hardware outside the hypervisor that an attacker would have to traverse, keeping the backup of last resort on infrastructure the attacker has not already breached. For production deployments where StoreOnce is the long-term retention tier in a cyber resilience design, the physical appliance is the stronger choice for exactly this reason.
Both the HPE Alletra MP system and the StoreOnce VSA were onboarded to HPE’s Data Services Cloud Console, providing centralized, cloud-based management and visibility across the environment. Through Data Services Cloud Console, the infrastructure can be monitored, managed, and integrated into broader HPE data services workflows from a single interface, tying together storage, backup, and recovery operations.
Govern: Implementing Your Strategy
HPE does not write your governance plan. Your organization, your insurer, and your legal team arrive at the policy. HPE provides the interfaces (APIs, CLIs, Data Services Cloud Console, and the published hardening guides) that let you implement that policy, evidence it, and audit against it.
That distinction matters because most storage vendors quietly assume the opposite. They ship opinionated defaults dressed up as best practices and treat configuration drift as a support problem rather than a governance signal. The B10000 inverts that posture. Every administrative action is logged. Every policy-relevant setting is exposed through the API. The security syslog stream is structured to feed the same SIEM where the rest of the organization’s governance evidence already lives. When an auditor asks who changed the password policy on a specific date, the answer sits in the same pane of glass as every other governed system in the estate.
Two governance disciplines deserve specific call-outs. The first is regulatory alignment. The B10000’s audit logging and SIEM integration architecture supports the operational controls required by the EU’s Digital Operational Resilience Act and the NIS2 Directive, covering detection, response, and recovery activities, incident reporting workflows, and the executive-oversight visibility expected of leadership. Centralizing the audit and security telemetry in the SIEM operationalizes those obligations. The controls the auditor expects to see are not bolted on. They are the same controls that the security operations center (SOC) already uses to operate the platform day-to-day.
The second is executive oversight. Regulatory frameworks increasingly require that leadership demonstrate timely, consolidated visibility into information and communication technology (ICT) risk. A storage array that hides its audit trail behind a vendor-only support portal cannot satisfy that requirement. One that streams audit and security events directly into the customer’s SIEM can. The B10000 was designed for the second pattern.
The platform provides several concrete capabilities. Documented hardening guides define the starting posture. Role-based access controls and dual-authorization mechanisms enforce separation of duties. Multi-factor authentication is built in. Defense Information Systems Agency Security Technical Implementation Guide (DISA STIG) hardening guidance is published for environments that require it. The security syslog stream turns every governance-relevant action into a queryable event. The plan is the customer’s. Instrumentation is the platform’s responsibility.
Identify: Trust in the Platform
Identify, in NIST CSF 2.0 framing, is about understanding what the organization has, where it came from, and what risks it carries. For a storage platform, that translates to supply chain integrity, secure development practices, and a verifiable starting posture.
HPE’s hardware and software supply chain is the foundation. Components are sourced through audited channels, firmware is signed, and platforms ship with tamper-evident packaging and seals that the receiving team can verify against shipment manifests. The supply chain assessment is a documented process that the HPE Cybersecurity Center of Excellence uses to verify that a B10000 leaving the factory in one week has the same provenance as a B10000 leaving in another week.
Secure development practices extend that chain into the software. The B10000 operating system undergoes structured penetration testing, including internal red-team exercises and third-party engagements, with findings fed back into the release cycle. Identify is not a one-time activity completed at install. It is the ongoing verification that the platform trusted on day one is still the platform present on day 400. The B10000 provides the artifacts (signed firmware, hash-verified downloads, hardening guides, secure development documentation, and the audit log stream) that enable that verification. What the security team does with those artifacts is, again, the security team’s decision.
Protect: Maintaining Posture
Protection on the B10000 rests on four mechanisms: immutable Virtual Lock snapshot scheduling, a deliberate separation between array snapshots and hypervisor snapshots, replication to a second site through both array-native Remote Copy and Zerto, and continuous drift detection through the audit log stream.
Immutable Virtual Lock snapshot scheduling
Virtual Lock snapshots are created on a schedule defined at the array and enforced directly by the B10000 storage platform. The snapshots remain immutable and read-only throughout their configured retention window, preventing modification or deletion until expiration. Administrative actions against protected snapshots are recorded in the audit log. They can be forwarded to external SIEM platforms, providing visibility into attempted policy violations, including deletion attempts against protected recovery points.
B10000 snapshots versus VME snapshots
Snapshots come from two places in this environment, and policy design depends on keeping them distinct.
B10000-scheduled snapshots are immutable and read-only and are governed by Virtual Lock retention. VME snapshots, taken by HPE Morpheus VM Essentials at the hypervisor tier, are mutable and read-write for VM-level operational workflows.
If an attacker gains access to the hypervisor, VME snapshots become accessible. Virtual Lock snapshots are not. The Virtual Lock schedule defines the retention floor. VME snapshots fill in the operational layer above it.
Replication: array-native and application-level
A Virtual Lock snapshot at the primary site does not protect against site-level events, and the architecture provides two distinct replication paths to address that. The first is native to the array: B10000 Remote Copy asynchronously replicates volumes to a second B10000 at another site, and, when combined with Virtual Lock snapshot schedules at the target, results in an immutable, physically separate vault that does not depend on the hypervisor or any application-layer software. The second is Zerto, operating at the application level with near-synchronous replication and continuous journal logging, providing the granular, low recovery point objective (RPO) recovery path described in the Recover section.
The two are complementary rather than redundant. Remote Copy preserves the array-enforced immutability guarantees across sites, while Zerto provides checkpoint granularity and orchestrated VM-level failover. In this engagement, the topology was configured to support Zerto replication from Fort Collins to HPE’s Bristol, UK, facility, but during the test session, the replication ran locally in Fort Collins due to bandwidth and parallel-cluster constraints. The Bristol leg is in place as an available topology and a follow-up activity, not as a demonstrated cross-site recovery.
Configuration drift detection
The hardening guide defines a baseline. The continuous audit log stream lets a SIEM verify, in near real time, that the baseline has not drifted. Password policy changes, lockout policy changes, new accounts, role elevations, schedule modifications, and replication target changes all surface as queryable events. The lab environment did not include a SIEM, so drift detection in this engagement was observed at the B10000 audit log level rather than in a centralized correlation tool. In a customer environment with a SIEM in place, the same audit events are fed to the SIEM via the syslog integration described in the Detect section.
Detect: Visibility and Early Warning
The B10000 ships with a built-in ransomware detection engine that monitors storage I/O patterns in real time and raises an alert when the statistical signature of large-scale encryption appears in writes to the array. The HPE Cybersecurity Center of Excellence has validated the engine against more than 100 leading ransomware strains.
Detection is enabled on a per-data-store basis from the VME side. When a data store is created or edited in VME against a B10000 storage server, the Ransomware Detection toggle is enabled by default for every volume provisioned in that data store, with per-volume customization available after creation. The capability requires B10000 OS version 10.5.0 or later. In the Fort Collins lab, the ftc-vme-mg1 data store was configured to connect to the FTC-AMP-5 B10000 over Fibre Channel, with ransomware detection enabled, which is the configuration used for the simulated ransomware run later in this section.
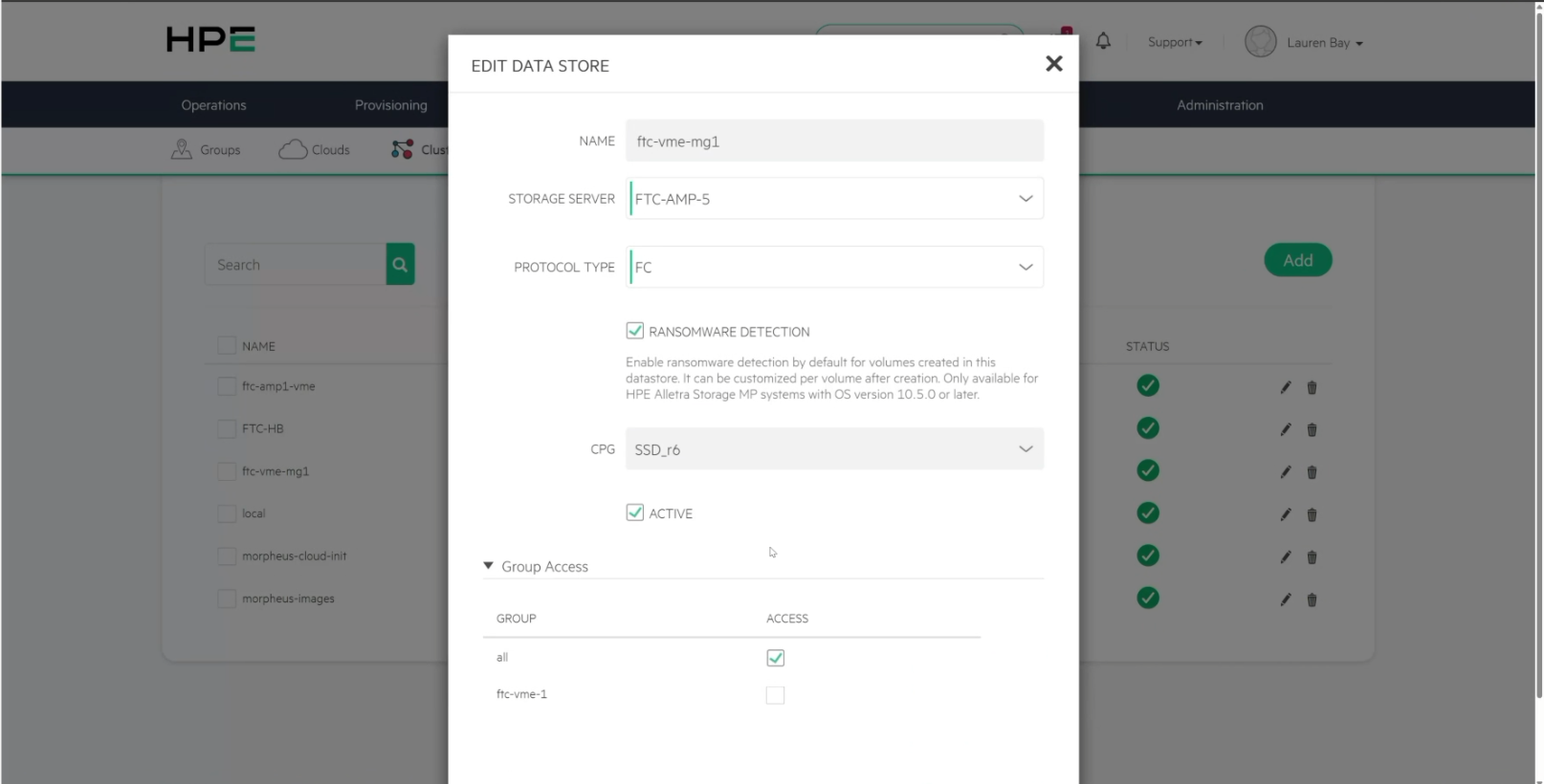
VME data store configuration showing the ftc-vme-mg1 data store on the FTC-AMP-5 B10000 over Fibre Channel, with Ransomware Detection enabled.
The B10000 also supports system-wide ransomware detection policies directly on the storage array, allowing administrators to define global detection sensitivity and automated snapshot retention behavior across protected volumes. As shown below, the Fort Collins environment had the array-level ransomware detection policy enabled with a low-confidence sensitivity profile and automatic snapshot retention configured. This provides an additional layer of protection beyond the per-data-store enablement in VME, ensuring the detection engine remains consistently enforced at the platform level regardless of how individual volumes are provisioned.
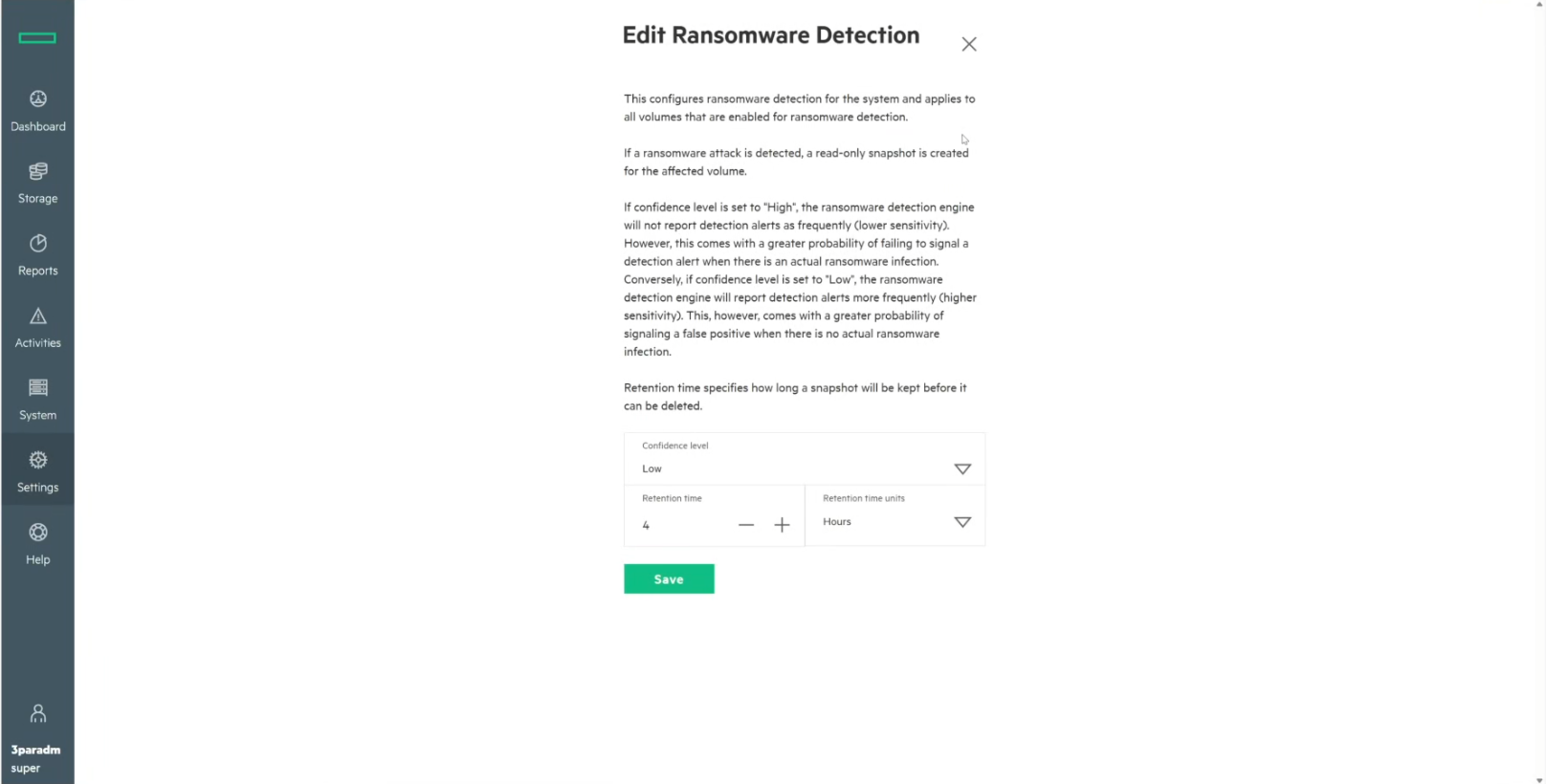
The detection logic for both is entropy-based. Random data, which is what encrypted data looks like at the block level, has high entropy. Legitimate workload data, even when compressed, has a structure the engine recognizes. The engine uses a CuSum entropy calculation to measure the disorder in incoming writes relative to an established baseline. The baseline is learned during a training window when a new volume is first protected and is then maintained by a rolling one-hour I/O profile, so that legitimate workload shifts do not generate false positives. When entropy departs from the baseline by a statistically significant margin, the engine flags the volume.
For the SOC, the key framing is that this is an encryption-detection engine serving as a last line of defense for the environment, not a replacement for endpoint protection. The endpoint is where ransomware should be caught first. The B10000 catches what the endpoint missed.
SIEM integration
The integration is deliberately vendor-agnostic. HPE’s role is to provide the groundwork and tools so the B10000 can feed audit and security log data into whatever SIEM an organization already runs, rather than steering customers toward a single HPE-preferred tool. Detection alerts and audit events are exported through the security syslog stream. The Fluentd-based aggregator HPE publishes on GitHub takes the raw syslog message, normalizes it to Elastic Common Schema, and tags the event with fields such as “event.kind: alert” and “event.severity: high” so the receiving platform’s existing rule engine picks it up without custom parsing. The important distinction is that this data is not merely compatible with modern SIEMs; it is active. It arrives structured to trigger automated alerts and downstream responses rather than sitting in a log archive waiting to be queried after the fact. Elastic Security and CrowdStrike Falcon Next-Gen SIEM are platforms HPE has explicitly validated, and the open syslog format means Microsoft Sentinel and other modern SIEMs can be onboarded with comparable effort.
Simulated ransomware on a Windows host
During remote testing against the HPE Fort Collins lab, a simulated ransomware workload was executed against a Windows host attached to a Virtual Lock-protected volume on the B10000. The simulation ran a controlled encryption script that produced the high-entropy write pattern characteristic of a ransomware encryption event, without using actual malware.
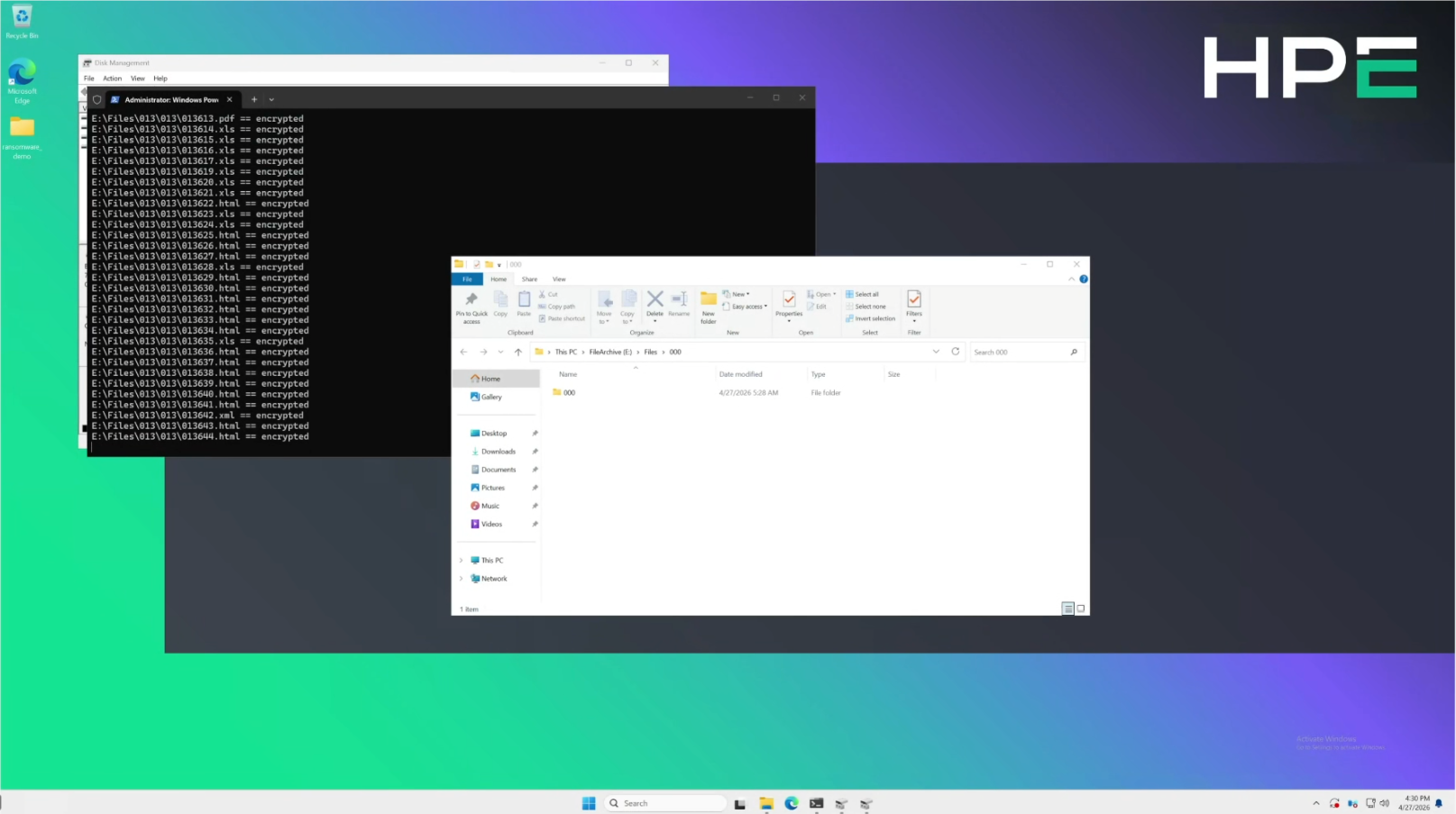
The B10000 detection engine raised the alert within four to five minutes of the encryption script beginning to write to the volume. The alert surfaced on the B10000 management console with the affected volume identified.
The four-to-five-minute window is short enough that immutable snapshots taken at or near the moment of detection capture a clean point-in-time before the attacker has finished traversing the volume. It is faster than most behavioral analytics running at the application layer because the B10000 sees writes at the block level as soon as they occur.
Respond: From Alert to Action
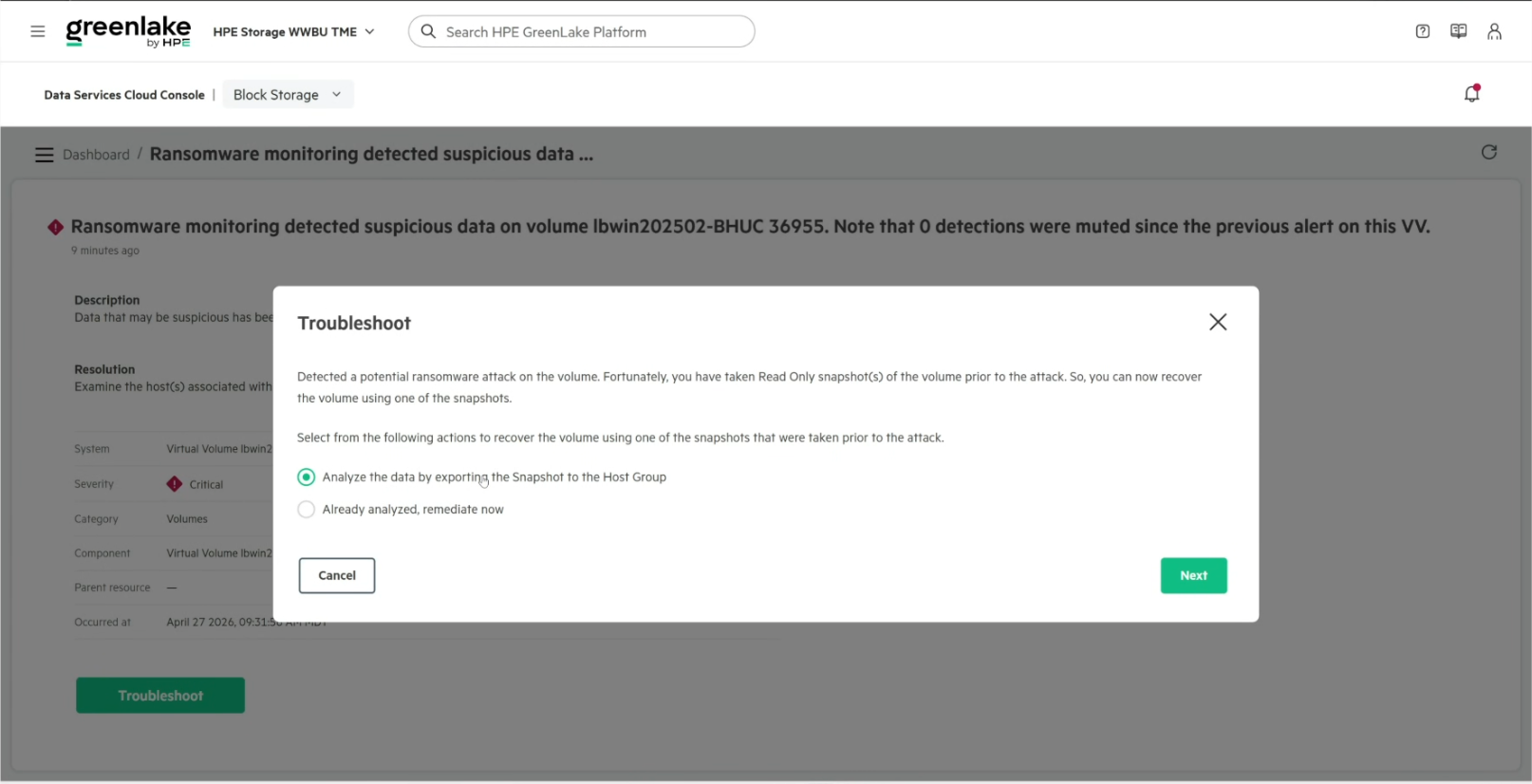
When the B10000 ransomware detection engine fires, the platform takes protective action on its own, before any external system is involved. At the moment of detection, the array captures an immutable snapshot of the affected volume and marks its status as degraded. This alert snapshot is not a clean recovery point and should not be used for restoration, as it may contain encrypted data. It is intended for forensic analysis, preserving the state of the volume at the time the attack was detected. Notably, the array does not cut off access to the volume. The data remains reachable, which is a deliberate design choice. The array raises the alarm and preserves the evidence. Still, it leaves the decision of how to proceed to the operators, who are better positioned to judge whether the event is a genuine attack or a false positive, such as a large, legitimate encryption or compression workload.
This autonomous behavior is the floor, not the ceiling, of the response capability. Because it runs directly on the array, it does not depend on a SIEM rule firing, a syslog stream remaining healthy, or an external automation tool being online. If every other layer fails, the moment-in-time snapshot still exists. That independence is the point: the response that matters most happens whether or not the rest of the stack is functioning.
Above that floor, the active SIEM integration described in the Detect section enables the orchestrated response. Because the B10000’s alerts arrive structured to trigger action rather than to be archived, a customer can build automated playbooks in the SIEM or security orchestration, automation, and response (SOAR) platform they already operate, whether that means extending snapshot retention on the affected volumes, isolating the host, opening an incident ticket, or notifying the response team. HPE provides the active, structured signal. The orchestration logic resides in the customer’s chosen tooling, keeping the response aligned with the runbooks and approval workflows the security team has already built.
One clarification matters here because the interface language can be layered. The B10000 alert offers an option to analyze the data, but the array itself does not scan for or identify specific malware. That option assumes the customer has their own scanning and forensic tooling to point at the affected data. The B10000’s job is detection and preservation, not remediation.
Recover: Tiered Restoration and Validation
Recovery is a tiered set of decisions: which recovery point, from which tier, restored to which environment, validated by which process. The architecture built in the Fort Collins lab supports a four-tier recovery model, where each tier exists because the others do not solve the same problem.
Tier 1: Zerto for continuous protection. Near-synchronous replication with continuous journal logging gives the lowest RPO in the stack. Granular restore lets the incident response team roll back a single VM or file to a checkpoint from moments before the encryption event. This is the tier to reach for when the alert fires quickly and the attacker’s window is narrow.
Tier 2: VME-native protection for daily VM-level restore. The HPE Morpheus VM Essentials snapshot stream provides operational recovery at the VM granularity. This is the tier that handles routine restore work and serves as the fallback if Tier 1 is unavailable.
Tier 3: B10000 immutable Virtual Lock snapshots for volume-level rollback. This is the tier that matters most for the ransomware case. Virtual Lock snapshots are protected against deletion and modification, and the promote operation is B10000-native, with no third-party ISV in the dependency chain.
Tier 4: StoreOnce Catalyst restore for long-term retention and cross-array recovery. Tiers 1 through 3 protect against events measured in hours or days. Tier 4 protects against events measured in weeks or months, in cases where the attacker established persistence long before the encryption fired, and when the only clean recovery point is older than any primary storage snapshot retention period. Catalyst stores are deduplicated, immutable, and can be replicated across StoreOnce systems or detached to Cloud Bank object storage. Catalyst Copy and Cloud Bank Detach together provide the “1” in the 3-2-1-1 model. This is also the tier where the physical-versus-VSA distinction noted in the architecture overview carries the most weight. As the last-resort recovery option, Tier 4 must be able to survive a hypervisor compromise. That is the argument for deploying StoreOnce on a dedicated physical appliance rather than as a VSA in production.
Closing Assessment
The two questions a security practitioner asks about a storage platform are whether the infrastructure remains under the organization’s control and whether the data remains protected. After working through the architecture in the Fort Collins lab, the B10000 answers both more completely than a storage array alone usually can, because the answer does not stop at the array.
The platform logs every administrative action, exposes every policy-relevant setting through its API, and streams the resulting audit and security telemetry to whatever SIEM the organization already runs. The governance plan remains the customer’s to write, but the instrumentation needed to implement it, evidence it, and prove it to an auditor is present and exposed rather than hidden behind a vendor portal. Immutable Virtual Lock snapshots mean that even a compromised administrator account cannot quietly destroy the recovery points, and any attempt to do so becomes a logged, queryable event.

In terms of protection, the detect-and-recover loop at the center of the architecture is the part that held up most convincingly. The B10000 flagged the simulated encryption workload within four to five minutes at the block level and captured a forensic snapshot at the moment of detection without waiting on an external system, and the affected volume was recovered cleanly from both a scheduled Virtual Lock snapshot promote and a StoreOnce Catalyst restore. That is the sequence that matters most during an incident, and it ran without a third-party product in the dependency chain.
What sets the architecture apart is not that the B10000 is dramatically more secure than competing arrays when considered in isolation. It is that HPE is one of the few vendors positioned to deliver storage, virtualization, replication, backup, and observability as a coordinated system, and to test that system as a whole against live ransomware in its own lab rather than validating each component in isolation. For an enterprise that owns the infrastructure but answers to a separate security team and an external regulator, that coordination is the difference between a collection of capable products and a resilience strategy that can be operated under pressure.
The architecture is also advancing quickly. HPE is on a steady release cadence across the stack, with tighter integration between VM Essentials and the B10000, ransomware detection expanding to additional data types beyond block volumes, and a published full-stack reference architecture, all on the near-term roadmap. The direction points toward more of the coordination handled natively by the platform and a clearer blueprint for assembling the kind of resilience design this paper examines.
For years, the storage array was treated as one of the safest assets in the building, largely because no one was paying attention to it. The case this architecture makes is that the array should be the opposite: not the overlooked box in the corner, but an active participant in detecting and surviving an attack, provided the organization does the work of turning the capabilities into a plan.
HPE B10000 Product Page
Additional Resources
HPE Alletra Storage MP B10000 – Cyber resilience with data-adaptive ransomware detection
HPE Alletra Storage MP B10000 ransomware protection framework
HPE Alletra Storage MP B10000 − SIEM integration
HPE Alletra Storage MP B10000 – Administrators hardening guide
HPE Alletra Storage MP B10000 security guide
Videos
hpe.com/uk/en/resource-library.video.hpe-alletra-storage-mp-b10000-r6-ransomware-detection-with…
hpe.com/uk/en/resource-library.video.hpe-alletra-storage-mp-b10000-and…
This report is sponsored by HPE. All views and opinions expressed in this report are based on our unbiased view of the product(s) under consideration.


 Amazon
Amazon